R語言文本挖掘之中文分詞包—Rwordseg包(原理�����、功能���、詳解)
與前面的RsowballC分詞不同的地方在于這是一個中文的分詞包���,簡單易懂���,分詞是一個非常重要的步驟����,可以通過一些字典��,進行特定分詞����。大致分析步驟如下:
數據導入——選擇分詞字典——分詞
但是下載步驟比較繁瑣�����,可參考之前的博客: R語言·文本挖掘︱Rwordseg/rJava兩包的安裝(安到吐血)
——————————————————————————————————
Rwordseg與jiebaR分詞之間的區別
中文分詞比較有名的包非`Rwordseg`和`jieba`莫屬�,他們采用的算法大同小異�����,這里不再贅述�����,我主要講一講他們的另外一個小的不同:
`Rwordseg`在分詞之前會去掉文本中所有的符號�����,這樣就會造成原本分開的句子前后相連��,本來是分開的兩個字也許連在一起就是一個詞了�,
而`jieba`分詞包不會去掉任何符號�����,而且返回的結果里面也會有符號����。
所以在小文本準確性上可能`Rwordseg`就會有“可以忽視”的誤差���,但是文本挖掘都是大規模的文本處理�,由此造成的差異又能掀起多大的漣漪��,與其分詞后要整理去除各種符號�����,倒不如提前把符號去掉了��,所以我們才選擇了`Rwordseg`�。
來看一下這篇論文一些中文分詞工具的性能比較《開源中文分詞器的比較研究_黃翼彪�����,2013》
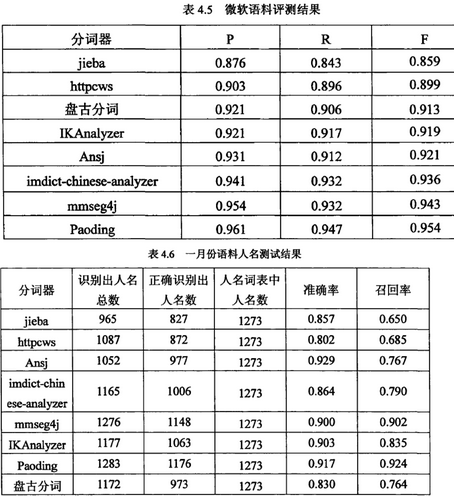
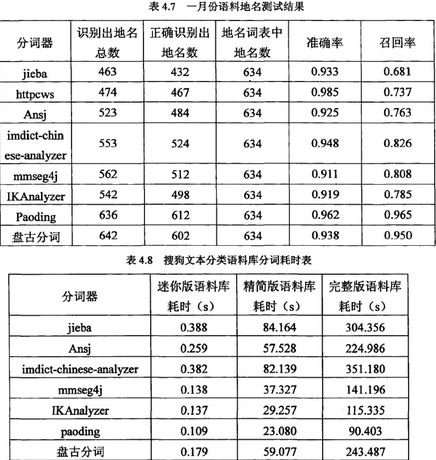
8款中文分詞器的綜合性能排名:
Paoding(準確率���、分詞速度����、新詞識別等����,最棒)
mmseg4j(切分速度�、準確率較高)
IKAnalyzer
Imdict-chinese-analyzer
Ansj
盤古分詞
Httpcws
jieba
——————————————————————————————————
Rwordseg分詞原理以及功能詳情
Rwordseg 是一個R環境下的中文分詞工具����,使用 rJava 調用 Java 分詞工具 Ansj����。
Ansj
也是一個開源的 Java 中文分詞工具���,基于中科院的 ictclas 中文分詞算法����, 采用隱馬爾科夫模型(Hidden Markov
Model, HMM)����。作者孫健重寫了一個Java版本���, 并且全部開源����,使得 Ansi 可用于人名識別����、地名識別����、組織機構名識別�����、多級詞性標注���、
關鍵詞提取�、指紋提取等領域�,支持行業詞典��、 用戶自定義詞典�。
1����、分詞原理
n-Gram+CRF+HMM的中文分詞的java實現.
分詞速度達到每秒鐘大約200萬字左右(mac air下測試)�,準確率能達到96%以上
目前實現了.中文分詞. 中文姓名識別 . 用戶自定義詞典,關鍵字提取����,自動摘要��,關鍵字標記等功能
可以應用到自然語言處理等方面,適用于對分詞效果要求高的各種項目.
該算法實現分詞有以下幾個步驟:
1��、全切分��,原子切分��;
2���、 N最短路徑的粗切分�����,根據隱馬爾科夫模型和viterbi算法��,達到最優路徑的規劃��;
3���、人名識別��;
4�����、 系統詞典補充�;
5�����、 用戶自定義詞典的補充����;
6����、 詞性標注(可選)
2��、Ansj分詞的準確率
這是我采用人民日報1998年1月語料庫的一個測試結果�����,首先要說明的是這份人工標注的語料庫本身就有錯誤�����。
P(準確率):0.984887218571267
R(召回率):0.9626488103178712
F(綜合指標F值):0.9736410471396494
3���、歧義詞����、未登錄詞的表現
歧異方面的處理方式自我感覺還可以�,基于“最佳實踐規則+統計”的方式�,雖然還有一部分歧異無法識別����,但是已經完全能滿足工程應用了�����。
至于未登錄詞的識別���,目前重點做了中文人名的識別�,效果還算滿意���,識別方式用的“字體+前后監督”的方式���,也算是目前我所知道的效果最好的一種識別方式了�。
4��、算法效率
在我的測試中����,Ansj的效率已經遠超ictclas的其他開源實現版本�。
核心詞典利用雙數組規劃�����,每秒鐘能達到千萬級別的粗分���。在我的MacBookAir上面�,分詞速度大約在300w/字/秒���,在酷睿i5+4G內存組裝機器上�����,更是達到了400w+/字/秒的速度�。數據分析師培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
