利用SPSS進行主成分分析
【例子】 以全國31個省市的8項經濟指標為例���,進行主成分分析����。 第一步:錄入或調入數據(圖1)�。

圖1 原始數據(未經標準化)
第二步:打開“因子分析”對話框��。
沿著主菜單的“Analyze→Data Reduction→FactorΚ”的路徑(圖2)打開因子分析選項框(圖3)���。
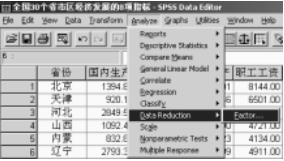
圖2 打開因子分析對話框的路徑
1
圖3 因子分析選項框
第三步:選項設置�����。
首先��,在源變量框中選中需要進行分析的變量�,點擊右邊的箭頭符號�����,將需要的變
�。在本例中�����,全部8個變量都要用上��,故全部調入量調入變量(Variables)欄中(圖3)
(圖4)�����。因無特殊需要����,故不必理會“ValueΚ”欄���。下面逐項設置�。
圖4 將變量移到變量欄以后
⒈ 設置Descriptives選項�����。
���,彈出Descriptives對話框(圖5)����。 單擊Descriptives按鈕(圖4)
2
圖5 描述選項框
在Statistics欄中選中Univariate
descriptives復選項�����,則輸出結果中將會給出原始數據的抽樣均值��、方差和樣本數目(這一欄結果可供檢驗參考)���;選中Initial
solution復選項�����,則會給出主成分載荷的公因子方差(這一欄數據分析時有用)���。
在Correlation
Matrix欄中���,選中Coefficients復選項����,則會給出原始變量的相關系數矩陣(分析時可參考)���;選中Determinant復選項���,則會給出相關系數矩陣的行列式�,如果希望在Excel中對某些計算過程進行了解�����,可選此項�,否則用途不大�。其它復選項一般不用����,但在特殊情況下可以用到(本例不選)���。
設置完成以后��,單擊Continue按鈕完成設置(圖5)���。
⒉ 設置Extraction選項�。
打開Extraction對話框(圖6)���。因子提取方法主要有7種��,在Method欄中可以看到���,系統默認的提取方法是主成分(Πρινχιπαλ χομπονεντσ)�,因此對此欄不作變動�,就是認可了主成分分析方法�����。
在Analyze欄中�,選中Correlation
matirx復選項��,則因子分析基于數據的相關系數矩陣進行分析���;如果選中Covariance
matrix復選項��,則因子分析基于數據的協方差矩陣進行分析���。對于主成分分析而言�,由于數據標準化了���,這兩個結果沒有分別��,因此任選其一即可����。
在Display欄中���,選中Unrotated factor solution(非旋轉因子解)復選項���,則在分析結果中給出未經旋轉的因子提取結果���。對于主成分分析而言�,這一項選擇與否都一樣�����;對于旋轉因子分析�����,選擇此項���,可將旋轉前后的結果同時給出��,以便對比��。
“山麓”圖)���,則在分析結果中給出特征根按大小分布的折線圖(形選中Scree Plot(
如山麓截面��,故得名)�,以便我們直觀地判定因子的提取數量是否準確�。
在Extract欄中���,有兩種方法可以決定提取主成分(因子)的數目���。一是根據特征根(Eigenvalues)的數值�����,系統默認的是λc=1�����。我們知道�,在主成分分析中�����,主成分得分的方差就是對應的特征根數值����。如果默認λc=1�,則所有方差大于等于1的主成分將被保留����,其余舍棄���。如果覺得最后選取的主成分數量不足���,可以將λc值降低�,例如取λc=0.9�;如果認為最后的提取的主成分數量偏多�,則可以提高λc值�����,例如取λc=1.1����。主成分數目是否合適����,要在進行一輪分析以后才能肯定���。因此��,特征根數值的設定�����,要在反復試驗以后才能決定����。一般而言���,在初次分析時����,最好降低特征根的臨

3
界值(如取λc=0.8) ���,這樣提取的主成分將會偏多�����,根據初次分析的結果���,在第二輪分析過程中可以調整特征根的大小��。
第二種方法是直接指定主成分的數目即因子數目��,這要選中Number
of
factors復選項�����。主成分的數目選多少合適���?開始我們并不十分清楚���。因此�,首次不妨將數值設大一些��,但不能超過變量數目��。本例有8個變量�,因此�����,最大的主成分提取數目為8���,不得超過此數���。在我們第一輪分析中�,采用系統默認的方法提取主成分�����。
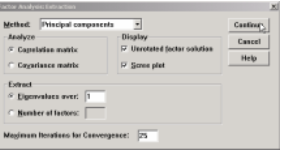
圖6 提取對話框
需要注意的是:主成分計算是利用迭代(Iterations)方法����,系統默認的迭代次數是25次���。但是�����,當數據量較大時���,25次迭代是不夠的����,需要改為50次��、100次乃至更多�����。對于本例而言��,變量較少�,25次迭代足夠�����,故無需改動����。
設置完成以后����,單擊Continue按鈕完成設置(圖6)���。
⒊ 設置Scores設置�。
選中Save as variables欄���,則分析結果中給出標準化的主成分得分(在數據表的后面)���。至于方法復選項����,對主成分分析而言�,三種方法沒有分別����,采用系統默認的“回歸”(Regression)法即可��。

圖7 因子得分對話框
4
選中Display factor score coefficient matrix���,則在分析結果中給出因子得分系數矩陣及其相關矩陣���。
設置完成以后����,單擊Continue按鈕完成設置(圖7)�。
⒋ 其它����。
對于主成分分析而言���,旋轉項(Rotation)可以不必設置�����;對于數據沒有缺失的情況下��,Option項可以不必理會��。
全部設置完成以后�����,點擊OK確定�,SPSS很快給出計算結果(圖8)��。
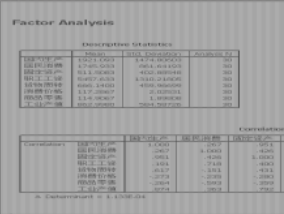
圖8 主成分分析的結果
第四步���,結果解讀��。
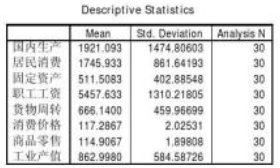
在因子分析結果(Output)中�,首先給出的Descriptive Statistics�����,第一列Mean對應的變量的算術平均值����,計算公式為
1nj=∑xij ni=1
第二列Std. Deviation對應的是樣本標準差�����,計算公式為
1nσj=[(xij?j)2]1/2 ∑n?1i=1
第三列Analysis N對應是樣本數目�����。這一組數據在分析過程中可作參考�。 5
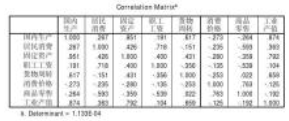
接下來是Correlation
Matrix(相關系數矩陣)����,一般而言����,相關系數高的變量��,大多會進入同一個主成分���,但不盡然�����,除了相關系數外��,決定變量在主成分中分布地位的因素還有數據的結構�����。相關系數矩陣對主成分分析具有參考價值�����,畢竟主成分分析是從計算相關系數矩陣的特征根開始的�����。相關系數陣下面的Determinant=1.133E-0.4是相關矩陣的行列式值����,根據關系式det(λI?R)=0可知�,det(λI)=det(R),從而Determinant=1.133E-0.4=λ1*λ2*λ3*λ4*λ5*λ6*λ7*λ8�。這一點在后面將會得到驗證�����。

在Communalities(公因子方差)中�,給出了因子載荷陣的初始公因子方差(Initial)和提取公因子方差(Extraction)�����,后面將會看到它們的含義�����。
在Total Variance Explained(全部解釋方差) 表的Initial Eigenvalues(初始特
6
征根)中���,給出了按順序排列的主成分得分的方差(Total)�,在數值上等于相關系數矩陣的各個特征根λ�����,因此可以直接根據特征根計算每一個主成分的方差百分比(%
of
Variance)�。由于全部特征根的總和等于變量數目����,即有m=∑λi=8����,故第一個特征根的方差百分比為λ1/m=3.755/8=46.939��,第二個特征根的百分比為λ2/m=2.197/8=
27.459���,……����,其余依此類推�����。然后可以算出方差累計值(Cumulative %)����。在Extraction Sums of Squared
Loadings�,給出了從左邊欄目中提取的三個主成分及有關參數����,提取的原則是滿足λ>1���,這一點我們在圖6所示的對話框中進行了限定����。
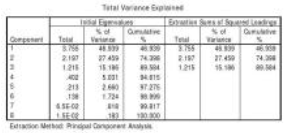
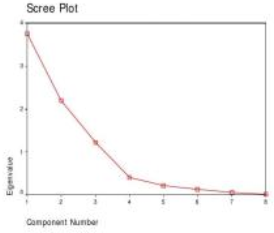
圖8 特征根數值衰減折線圖(山麓圖)
主成分的數目可以根據相關系數矩陣的特征根來判定�����,如前所說���,相關系數矩陣的特 7
征根剛好等于主成分的方差����,而方差是變量數據蘊涵信息的重要判據之一�。根據λ值決定主成分數目的準則有三:
i 只取λ>1的特征根對應的主成分
從Total Variance Explained表中可見����,第一���、第二和第三個主成分對應的λ值都大于1�����,這意味著這三個主成分得分的方差都大于1��。本例正是根據這條準則提取主成分的�����。
ii 累計百分比達到80%~85%以上的λ值對應的主成分
在Total Variance Explained表可以看出��,前三個主成分對應的λ值累計百分比達到89.584%��,這暗示只要選取三個主成分�����,信息量就夠了����。
iii 根據特征根變化的突變點決定主成分的數量
從特征根分布的折線圖(Scree Plot)上可以看到�,第4個λ值是一個明顯的折點����,這暗示選取的主成分數目應有p≤4(圖8)���。那么����,究竟是3個還是4個呢��?根據前面兩條準則����,選3個大致合適(但小有問題)���。
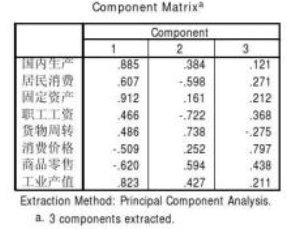
在Component
Matrix(成分矩陣)中�,給出了主成分載荷矩陣��,每一列載荷值都顯示了各個變量與有關主成分的相關系數���。以第一列為例��,0.885實際上是國內生產總值(GDP)與第一個主成分的相關系數���。將標準化的GDP數據與第一主成分得分進行回歸�,決定系數R2=0.783(圖9)�,容易算出R=0.885�����,這正是GDP在第一個主成分上的載荷����。
下面將主成分載荷矩陣拷貝到Excel上面作進一步的處理:計算公因子方差和方差貢獻�。首先求行平方和��,例如��,第一行的平方和為
h12=0.88492+0.38362+0.12092=0.9449
這是公因子方差���。然后求列平方和�����,例如����,第一列的平方和為
s12=0.88492+0.60672+…+0.82272=3.7551
這便是方差貢獻(圖10)����。在Excel中有一個計算平方和的命令sumsq�,可以方便地算出一組數據的平方和�。顯然��,列平方和即方差貢獻��。事實上�,有如下關系成立:
至于行平方和����,顯然與前面公因子方差(Communalities)表中的Extraction列對應的數據一樣��。如果我們將8個主成分全部提取�,則主成分載荷的行平方和都等于1(圖11)�,即有hi=1���,sj=λj���。到此可以明白:在Communalities中�����,Initial對應的是初始公因子方差����,實際上是全部主成分的公因子方差���;Extraction對應的是提取的主成分的公因子方差���,我們提取了3個主成分���,故計算公因子方差時只考慮3個主成分�。
8
4.00000
第一主成分
2.00000
0.00000
-2.00000
國內生產總值
圖9 國內生產總值(GDP)的與第一主成分的相關關系(標準化數據)
圖10 主成分方差與方差貢獻
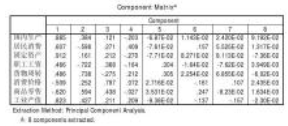
9
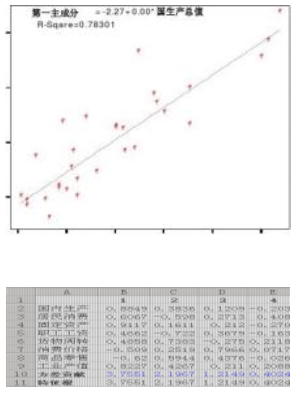
圖11 全部主成分的公因子方差和方差貢獻
提取主成分的原則上要求公因子方差的各個數值盡可能接近�����,亦即要求它們的方差極小�����,當公因子方差完全相等時��,它們的方差為0���,這就達到完美狀態�。實際應用中�,只要公因子方差數值彼此接近(不相差太遠)就行了�。從上面給出的結果可以看出:提取3個主成分的時候�����,居民消費的公因子方差偏小����,這暗示提取3個主成分��,居民消費方面的信息可能有較多的損失��。至于方差貢獻���,反映對應主成分的重要程度�,這一點從方差的統計學意義可以得到理解��。
在圖11中�����,將最后一行的特征根全部乘到一起�,得0.0001133�����,這正是相關系數矩陣的行列式數值(在Excel中���,求一組數據的乘積之和的命令是product)��。
最后說明Component
Score Coefficient Matrix(成分得分系數矩陣)和Component Score Covariance
Matrix(成分得分協方差矩陣)���,前者是主成分得分系數��,后者是主成分得分的協方差即相關系數����。從Component Score
Covariance
Matrix可以看出����,標準化主成分得分之間的協方差即相關系數為0(j≠k)或1(j=k)���,這意味著主成分之間彼此正交即垂直��。
初學者常將Component
Score Coefficient
Matrix表中的數據當成主成分得分或因子得分���,這是誤會����。成分得分系數矩陣的數值是主成分載荷除以相應的特征根得到的結果�。在Component
Matrix表中����,將第一列數據分別除以λ1=3.755,第二列數值分別除以
立即得到Component Score Coefficient����;反過來���,如果將Component Score λ2=2.197,…�,
Coefficient Matrix表中的各列數據分別乘以λ1=3.755�����,λ2=2.197,…�����,則可將其還原為主成分載荷即Component Matrix中的數據��。

10
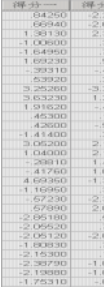
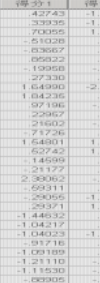
實際上����,主成分得分在原始數據所在的SPSS當前數據欄中給出���,不過給出的都是標準化的主成分得分(圖12a)�����;將各個主成分乘以相應的√λ即特征根的二次方根可以將其還原為未經標準化的主成分得分����。
a.標準化的主成分得分 b. 非標準化的主成分得分
圖12 兩種主成分得分
計算標準化主成分得分的協方差或相關系數����,結果與Component Score Covariance 11
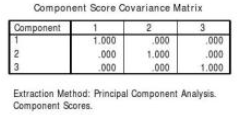
Matrix表中的給出的結果一致(見圖13)����。
第一因子 第二因子 第三因子
第一因子 1 第二因子 0.00000 1 第三因子 0.00000 0.00000 1
圖13 主成分(得分)之間的相關系數矩陣
第五步�,計算結果分析����。
從Component
Matrix即主成分載荷表中可以看出����,國內生產總值�、固定資產投資和工業產值在第一主成分上載荷較大�,亦即與第一主成分的相關系數較高���;職工工資和貨物周轉量在第二主成分上的載荷絕對值較大�����,即負相關程度較高�;消費價格指數在第三主成分上的載荷較大���,即相關程度較高�����。
因此可將主成分命名如下:
第一主成分:投入-產出主成分���; 第二主成分:工資-物流主成分��; 第三主成分:消費價格主成分��。
問題在于:一方面����,居民消費和商品零售價格指數的歸類比較含混����;另一方面�����,主成分的命名結構不清�。因此���,有必要作進一步的因子分析���。

至于因子旋轉之類���,留待“因子分析”部分說明��;計算結果的系統分析不屬于軟件操作范圍
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
