經典的大數據問題
隨著信息的高速發展�,越來越多的數據信息等待處理�,如何快速的從這些海量數據中找到你所需要的數據呢?這就是大數據的處理問題����,下面我對幾個經典的大數據問題進行分析~~~~
一. 設計算法找到每日訪問百度出現次數最多的IP地址?
分析:將所有的IP逐個寫入到一個大文件中����,因為當IP地址采用點分十進制的方式表示的時候是32位的�,所以最多存在2^32個IP��?����?梢圆捎糜成涞姆绞?���,比如模1000����,將這個較大的文件映射為1000個小文件�,再將每個小文件加載到內存中找到每個小文件中出現頻率最大的IP(可以使用hash_map的思想進行頻率統計);然后在這1000個最大的IP中找出那個出現頻率最大的IP����,就是出現次數最多的IP了�����。
算法思想如下:(分而治之+hash)
1).IP地址最多有2^32=4G個��,所以不能直接將所有的IP地址加載到內存中
2).可以考慮采用”分而治之”的思想���,就是將IP地址Hash(IP)%1024值�,將海量IP分別存儲到1024個小文件中����,這樣每個小文件最多包含(2^32)/(2^10)=4M個IP地址
3).對于每一個小文件�,可以構建一個IP值為key,出現次數為vaue的hash_map����,通過value的比較找到每個文件中出現次數最多的那個IP地址
4).經過上述步驟已經得到1024個出現次數最多的IP地址�����,再選擇一定的排序算法找出這1024個IP中出現次數最多的那個IP地址
二.給兩個文件���,分別有100億個整數�����,我們只有1G內存�����,如何找到兩個文件的交集?
分析:我們知道對于整形數據來說�,不管是有符號的還是無符號的�����,總共有2^32=4G個數據(100億個數據中肯定存在重復的數據)��,我們可以采用位圖的方式來解決����,假如我們用一個位來代表一個整形數據����,那仫4G個數共占512M內存���。我們的做法是將第一個文件里的數據映射到位圖中�����,再拿第二個文件中的數據和第一個文件中的數據做對比����,有相同的數據就是存在交集(重復的數據���,交集中只會出現一次).

三.假定一個文件有100億個整形數據����,1G內存���,如何找到出現次數不超過兩次的數字?
分析:要解決這個問題同樣需要用到位圖的思想�,在問題二中已經了解到采用位圖的一個位可以判斷數據是否存在��,那仫找到出現次數不超過兩次的數字使用一個位是無法解決的�,在這里可以考慮采用兩個位的位圖來解決.
根據上述分析我們可以借助兩個位��,來表示數字的存在狀態和存在次數���,比如:00表示不存在��,01表示存在一次����,10表示存在兩次����,11表示存在超過兩次;類似問題二的計算過程:如果一個數字占一位�,需要512M內存即可�����,但是如果一個數字占兩位���,則需要(2^32)/(2^2)=2^30=1G內存;將所有數據映射到位圖中查找不是11的所對應的數字就解決上述問題了���。
題目擴展:其他條件不變�,假如只給定512M內存該如何找到出現次數不超過兩次的數字?
分析:將數據分批處理���,假若給定的是有符號數���,則先解決正數��,再解決負數���,此時512M正好解決上述問題.
四.給兩個文件��,分別有100億個query�����,我們只有1G內存����,如何找到兩文件交集?分別給出精確算法和近似算法!
分析:看到字符串首先應該反應過來的就是布隆過濾器�����,而問題四的近似算法就是采用布隆過濾器的方法��,之所以說布隆過濾器是近似的算法�,因為它存在一定
的誤判(不存在是肯定的��,存在是不肯定的);而要想精確判斷字符串文件的交集�,我們可以采用分而治之的方法:將大文件切分為一個一個的小文件����,將一個又一個的小文件拿到內存中做對比�,找到對應的交集�����。
1.布隆過濾器的近似解決辦法:
根據不同的字符串哈希算法��,可以計算出不同的key值�����,然后進行映射��,此時可以映射到不同的位置��,只有當這幾個位全部為1的時候這個字符串才有可能存在(因為當字符串過多的時候可能映射出相同的位)�,只有一個位為0�,那仫該串一定是不存在的���,所以說布隆過濾器是一種近似的解決辦法��。將第一個文件映射到布隆過濾器中�,然后拿第二個文件中的每個串進行對比(計算出特定串的key����,通過不同的哈希算法映射出不同的位��,如果全為1則認為該串是兩個文件的交集;如果有一位為0那仫該串一定不是交集).
既然叫做切分���,顧名思義就是將大文件切分為小文件�����,那仫如何切分?切分的依據是什仫呢?如果我們在切分的時候可以將相似或者相同的文件切分到同一個文件中那仫是不是就加快了查找交集的速度呢?答案是肯定的����。
知道了哈希切分的依據我們應該如何處理呢?我們可以根據字符串的某個哈希算法得到該字符串的key��,然后將key模要分割的文件數(假設為1000個文件�����,文件編號為0~999)�,我們將結果相同的字符串放到同一個文件中(兩個文件中的字符串通過相同的哈希算法就會被分到下標相同的文件中)�����,此時我們只需要將下標相同的文件進行比對就可以了���。��。����。
哈希切分明顯比布隆過濾器的方法效率要高�����,時間復雜度為O(N).
具有刪除功能的BloomFilter:


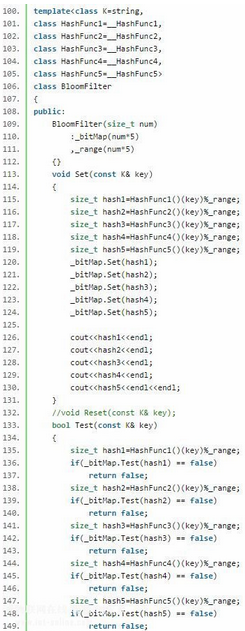


在上面實現的布隆過濾器中引用了不同的哈希算法���,有想研究哈希算法的的童鞋可參考各種字符串Hash函數>>>
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
