魅族大數據上云之路
首先我先介紹一下魅族大數據上云的背景�����,即我們為什么要上云��?
在開始之前我們默認今天參與直播的各位同學對Hadoop相關技術和Docker都有一定的了解�,另外以下提到Hadoop是泛指目前魅族大數據使用的Hadoop生態圈技術�����,資源除特別說明則泛指存儲資源��、計算資源和網絡資源的總和����。
我們先來看一下魅族大數據在沒有上云的時候所遇到的主要問題有以下幾個方面:
1.資源隔離不徹底
由于一些歷史問題���,我們跑在Hadoop上的任務腳本質量參差不齊�����,導致經常有一些異常任務會短時間吃掉所有的機器資源�,導致整臺機器down掉�。
2.資源利用效率低
目前我們的業務增速很快��,每個Q都需要一定數量的機器擴容���,但是業務的增速往往不是線性的��,為某些關鍵時間點的峰值需求而準備的機器常常在峰值過去之后存在大量的資源閑置��。
3.集群運維成本高
由于一些存儲�、網絡方面的物理故障以及異常任務導致故障恢復都需要運維同學人工介入�����。常見的高可用解決方案都需要侵入到Hadoop技術體系內部����,有一定技術門檻�����。公共運維部門的同學無法很好的支持大數據團隊服務器運維��。集群部署模型復雜���,過程繁瑣
基于以上這些存在的問題���,我們經過一番技術預研發現����,上云之后可以很好的解決我們的問題�����。
在討論上云的總體規劃之前��,我覺得有必要先把幾個非常重要但是卻容易混淆的概念先做一下簡單解釋��,這里只是點到為止��,希望這對大家理解后面的內容會很有幫助
Docker≠容器技術
Linux很早就推出了內核虛擬化技術LXC����,Docker是有Docker公司研發的����,它把LXC做了進一步的封裝(現在已經替換成了它自己實現的libcontainer���,加上鏡像管理等一系列功能��,變成了一套完整��、易用的容器引擎�����。2015年的dockerCon大會上����,docker和CoreOS共同推出了Open
Container Project 來統一容器的定義和實現標準)����。
這里提一些圈兒內的軼事給大家提供點兒談資:
剛才提到的OCP(Open Container
Project)的建立�,google才是背后的真正推手����,因為當年Docker的快速發展���,打敗了google曾經的開源容器技術lmctfy�,Docker公司和CoreOS原本和睦���,共同發展Docker技術���,后來由于意見上的分歧�����,兩家都想做容器技術的標準制定者��,google暗中支持CoreOS���,后來CoreOS隨即自立門戶�,發布了自己的容器技術Rocket�����,并且和google的kubernetes合作發布了容器服務平臺Tectonic�,Docker公司和CoreOS由此徹底決裂�。后來Linux基金會出面調和����,google也從中協調����,雙方都退讓了一步����,才最終和解推出了OCP���,但是有心人可以看一下OCP項目的成員名單就知道���,Dcoker公司在這中間只占很小的一部分�����,google在其中扮演了重要角色�。此外Docker公司也放棄了自己對Docker技術的獨家控制權����,做為回報Docker的容器實現被確定為OCP的新標準�,但源代碼都必須提交給OCP委員會�。不難看出google實際上是為了報當年lmctfy的一箭之仇��,借CoreOS之手狠踩了Docker公司一腳��,自己也成為了容器技術領域的實際控制者
總結下來Docker只是眾多容器技術中的一種���,只是由于它最近的火爆而幾就成了容器技術的代名詞����。
容器技術≠虛擬化技術
容器技術只是實現虛擬化的一種輕量級的解決方案����,常見的虛擬化方案還包括
KVM��、Xen和vmware的解決方案等���。
虛擬化≠等于云
虛擬化技術只是一個完整云服務體系中包含的一個技術手段���,但不是全部���,甚至不是必須的�����。完全使用物理機也可以搭建一個云���。
常見的云服務體系中的核心服務還包括:
認證服務鏡像服務網絡服務(例如:SDN(軟件定義網絡)和物理網絡)計算服務(管理�����、分配����、調度計算任務)對象存儲服務(直接為應用提供數據讀寫服務)塊存儲服務(為主機提供類似裸物理磁盤的存儲服務)
(以上的分類方式參考了亞馬遜AWS的云服務體系)
魅族大數據上云的一個整體規劃�,基本上分為3個大的階段:
PART I — Hadoop on DockerPART II — Container Cluster Management SystemPART III — Hadoop on Cloud Operating System
(這次分享針對PART I的內容)
魅族大數據目前已經來到第三個階段�,前兩個階段也是我們曾經走過的���,由于今天篇幅的限制重點介紹第一部分�����,hadoop on docker的內容�。
Hadoop on Docker方案演進
首先來說明一下我們為什么要上docker���,通過在Docker 上部署Hadoop���,我們可以實現:有效的提升集群部署效率����,原本需要運維手工部署的過程��,現在可以通過一個命令直接從Docker Registry中pull對應的鏡像�,一鍵啟動�。
安全性:在Docker中運行的應用�����,在沒有主動配置的情況下�,基本無法訪問宿主機的文件系統�����,這樣可以很好的保護宿主機的文件系統和其他設備��。
資源調控/隔離:Docker可以對應用所需要的資源���,如CPU計算資源����、內存資源��、存儲資源���、網絡帶寬等進行調控(資源調控目前只支持容器啟動前的一次性配置)���,不會因為單一任務的一場導致整個hadoop集群掛起����。
一致性:只要源自同一個鏡像���,hadoop集群中的任何節點都可以保持統一的軟件環境�����,不會由于管理員的人為失誤導致集群環境不一致��。
可用性:由于容器節點的輕量級特征��,我們可以非常方便的部署一些針對namenode 的HA方案��。另外即使遇到極端情況集群整個掛掉��,我們也可以快速的重啟整個hadoop集群�。
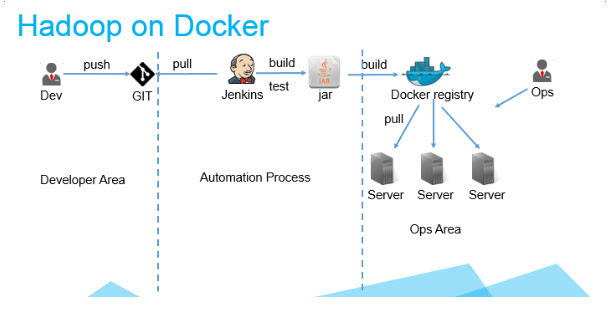
開發者只需要關心代碼本身�,代碼編寫完成后提交到Git��,之后的構建�,測試��、build docker 鏡像���,提交鏡像到docker registry都可以由jenkins自動化完成�����,運維只需要負責在合適的機器上啟動對應鏡像的服務即可���。
目前魅族大數據已經經歷過docker方案的預研和實施�����,并且在線下測試和開發環境中已經開始使用docker驅動DevOps提高開發->測試的效率�����,目前在測試環境中docker宿主機集群規模50+��,容器數1000+���。
在這個過程中��,我們也經歷了從單純的docker����,到一個完整的容器云環境的演變���,docker的build ship run理念看起來很美����,但是實際使用起來如果只有docker還是會面臨很多的問題和挑戰��。
具體的原因我分了以下幾個方面來介紹���,這些也是我們曾經踩過的坑����,是構建一個完善的云計算環境來服務大數據技術不可避免的幾個核心點�。
資源隔離/動態分配
資源的隔離其實使我們在使用docker之前面臨的一個大問題����,經常會由于ETL同學不是特別注意寫了一些有問題的任務腳本��,上線后導致整個hadoop集群資源耗盡�,關鍵任務出現延遲甚至失敗��,運維的同學每天被這種問題折騰的死去活來�����。
而采用了docker之后���,Docker通過libcontainer調用linux內核的相關技術(現在windows和其他操作系統也開始native支持容器技術了��,具體進展大家可以關注Open
ContainerProject和docker的官網)實現了容器間的資源隔離��,資源的分配可以在docker容器啟動時通過啟動參數來實現�����,這里舉幾個簡單的例子:
CPU配額控制:docker run-it –rm stress –cpu 4
–cpu代表指定CPU的配額參數����,4代表配額的值����,這里的配額可以簡單理解為CPU的占用率��,比如一個宿主機中有兩個容器在運行時都指定了—cpu
4���,則相當于運行時這兩個容器各站CPU配額的50%��,注意這里的配額并不是一個嚴格的限制�,在剛才的例子中����,如果容器1完全空閑�,則容器2是可以完全占用100%的CPU的�,當容器1開始使用CPU時���,則容器2的CPU配額才會逐步下降����,直到兩個容器都各站50%為止�����。
內存控制:docker run-it –rm -m 128m
-m參數指定了內存限制的大小���,注意這里的值指的只是物理內存空間的限制����,docker在運行容器的時候會分配一個和指定物理內存空間一樣大的swap空間�����,也就是說����,應用在運行期占用內存達到了-m參數指定值的兩倍時��,才會出現內存不足的情況�。
Docker的資源限制目前必須在容器啟動時手工完成�,但是在大規模集群的環境下�,手工逐一根據物理機的資源情況進行配額的指定顯然是不現實的�����。而且docker并不支持存儲空間的配額限制���,只能限制讀寫的速率�。
Docker現階段還不能滿足需求���,我們需要一個可以根據集群的實際運行情況進行計算資源�����、存儲資源�、網絡資源的合理分配的解決方案�。
我們經過實踐的檢驗����,發現Docker的資源隔離相比于傳統虛擬機技術還是有很多做的不徹底的地方��,除了上面所屬的之外�,在安全上也一直存在一些比較大的隱患�,比如docker一直以來都不支持user namespace��。
所以如果容器內的應用使用root賬號啟動��,而啟動時又帶上—priviledge參數的話����,會導致容器內的root和宿主機的root權限一直�,帶來非常大的安全隱患���。在這里稍微補充一點�,在最新的1.10版本的docker中已經支持了user
namespace(通過–userns-remap參數)����。
但是魅族大數據并沒有升級到這一版��,這也是由于我們的服務編排和容器集群管理使用的是google開源的kubernetes����,目前最新版的kubernetes1.2官方聲明最新支持的docker版本只到1.9���,有關kubernetes的內容有機會會在后續的分享中跟大家交流���。
定義鏡像/存儲結構
定義存儲結構的目的是為了實現部署環境的標準化���,之前我們也嘗試過直接提供一個帶SSH服務的容器節點���,這樣感覺用起來跟虛擬機是沒什么差別��,但是這樣一來之前虛擬機運維時碰到的各種環境不一致的問題還是會出現�,docker的多層鏡像結構的優勢就完全沒有發揮出來��。
通過一個base鏡像定義好一套標準���,這就像maven的parent
pom一樣(這個比喻有些不夠恰當��,maven更多的是進行包依賴的管理�����,而docker的多層鏡像存儲結構可以定義一個完整的基礎運行環境�����,并且這個環境是可以繼承的)���,可以給大家提供一個標準的環境基礎設置���,另外上層應用非常方便的可以收集容器中的數據�����,使用容器的服務��。
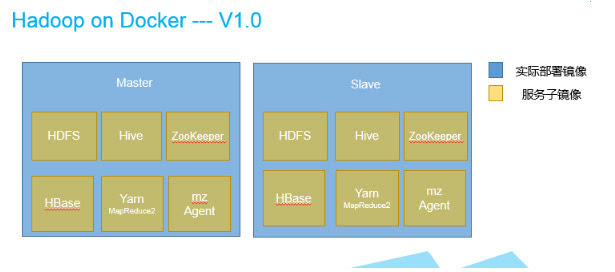
首先我們按照部署模型劃分鏡像結構�,對每一個Hadoop生態中的服務都抽象出一個對應的鏡像���,這個服務鏡像包含了主從架構的兩套配置���,使用環境變量來區分該服務鏡像到底是作為master還是slave部署����。
這樣做的好處是可以降低鏡像的數量��,方便做配置和服務版本的管理和升級�����,另外需要注意的是mz agent�����,這是我們自定義的一個鏡像�����,用來進行臨時文件的清理�����、日志數據收集����,以及對接第三方的監控服務實現�,向我們的監控平臺發送自定義的一些集群健康度指標數據����。
此外它還負責接收客戶端的管理指令請求����,可以讓集群管理員像操作一臺服務器一樣的對整個集群或集群中的特定主機進行操作�����。
為了方便做統一的監控和存儲的管理���,我們在鏡像內定義了一些基本的目錄結構

bin目錄用來存放鏡像服務的binary包以及shell腳本tmp目錄用來存放臨時文件���,mz
agent會定時進行文件的清理data存放一些需要持久化的數據文件��,通過volume掛載到宿主機的目錄中����,包括一些需要進行分析的應用日志���,應用的數據文件等���。conf保存服務相關配置信息鏡像管理使用git+docker
registry�,git中保存鏡像的構建過程��,Dockerfile�����,docker registry保存實際鏡像��。
這樣定義鏡像結構可以幫助我們通過統一的標準更好的進行監控����、報警���、發布管理等相應特性的實現��。上層的平臺應用只需要將一些必要的實現諸如到base鏡像中�,就可以實現統一的運行環境升級��。
這里會存在一個問題�,docker容器在運行時產生的數據是保存在宿主機的特定目錄的����,而且這些數據的生命周期跟容器的生命周期一樣��,一但容器銷毀��,則這些數據也會一并刪除�,如果將HDFS部署在容器中�,這也是不能容忍的���。
我們如果通過volume的方式將數據掛載到宿主機則會導致宿主機中存在大量跟容器的ID相關的存儲目錄�,而且一旦節點掛掉想要在其他節點上啟動相同的服務還需要進行數據的遷移�����。大規模集群的環境下在每個節點上管理這些目錄會帶來額外的運維成本��。
為了解決這一問題����,我們需要一個存儲管理的服務來托管容器運行時生成的數據��,使得Hadoop集群能夠隨時創建����,隨時銷毀�。集群內的應用服務不需要關心運行時生成的數據存放在哪里����,如何管理等等��。
在分布式環境下運行容器
由于hadoop生態圈技術的特點���,docker必須部署在分布式的環境中��,而這會帶來很多新的挑戰���。如果有熟悉docker的同學就會發現一個問題���,HDFS默認會將數據做3個副本��。
但docker可以在同一個宿主機中啟動多個容器�����,如果這三個副本都落在了同一個宿主機上�����,那么一但宿主機down掉����,三個副本就一起失效����,HDFS的這種利用多副本來提高數據可用性的策略就無效了�����。
不僅是HDFS����,其他需要通過類似雙master或多副本的結構來做HA的方案都會遇到同樣的問題��。
在只使用docker的情況下�����,只能通過人工的方式�,將namenode和datanode分開在不同的宿主機上啟動��。
這樣一來�����,一但某個容器內的服務掛掉�����,為了保持有足夠數量的服務中容器��,則需要運維的同學人工的通過監控平臺去檢查集群目前各宿主機的負載和健康度情況�,同時結合不同容器服務的部署架構要求選擇合適的宿主機啟動容器�����。
雖然最后部署的動作已經相對自動化��,但是選擇部署服務器的過程依然是痛苦的�。
再補充一點�,如果希望升級Hadoop生態中的某個服務的版本�����,一般都是先在測試環境進行部署驗證��,ok之后才會將鏡像發送到線上的Registry�,這就涉及到了如何隔離測試和線上生產環境的問題����,不同環境的存儲����、計算�、網絡資源必須相對隔離���。
如果是在運行中的集群中更新服務的版本則還會涉及到灰度發布的問題�。如果線上集群已經存在了多個版本的服務����,則還要考慮個版本升級過程是否有差異�,是否需要進行滾動發布等�����,這些docker暫時都不能幫我們解決����,僅僅依靠人工或者自己搭建平臺來完成依然需要很大的工作量�����。
這也就引出了Docker僅僅作為一個容器引擎的不足����,如果需要大規模的部署�,我們需要一個容器調度管理服務�����,來按照我們指定的策略分配容器運行的實際宿主機����。同時能夠根據預定義的發布更新策略�����,對運行中的容器服務進行動態的滾動更新(rolling update)
多宿主機網絡解決方案
另外我們遇到的一個無法忽略的就是多宿主機環境下的網絡問題��,既然要在集群環境下運行���,那么如何在多宿主機的環境下讓各臺宿主機上運行的容器都能分配到一個指定網段內的IP���,并且彼此之間可以進行正常網絡通信��。
由于大數據相關的應用和服務往往需要進行大量的網絡吞吐���,這一方案在性能上也不能有很大的損失�。
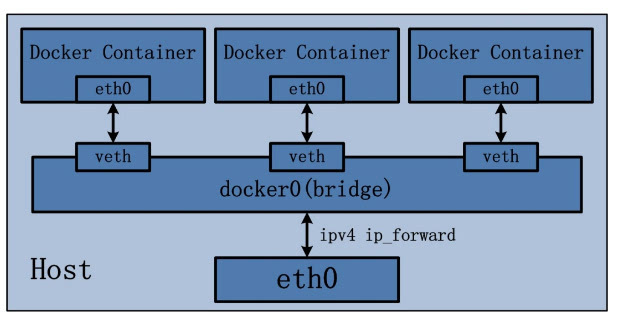
Docker自帶的網絡模塊如上圖所示�����,通過一個虛擬化的docker0網橋��,把主機上的eth0端口和docker
engine內部的container通過veth
pair連接到一起�,容器間的網絡通訊都是通過docker0網橋來轉發���,容器帶外網的請求是通過docker0網橋來進行NAT轉換后發送到外網���,這樣的網絡方案能夠在單一宿主機上解決網絡通信的問題���。
但一旦進入多宿主機的集群環境��,各個的宿主機上運行的容器就無法得知彼此的IP網段和路由信息��。
在Docker的技術體系中�����,解決這一問題目前主流的方案有以下幾種:
Dockernetworking(from 1.9)FlannelOpenvSwitchWeavecalico
這幾種解決方案的優缺點和適用場景涉及內容很多�,有興趣的同學可以參考一下這篇文章���。
http://www.chunqi.li/2015/11/15/Battlefield-Calico-Flannel-Weave-and-Docker-Overlay-Network/
我們采用了上述的最后一種calico����,主要是出于性能上的考慮����,calico是一個純layer 3
的解決方案�,使用了一個etcd作為外部配置信息存儲��,通過BGP廣播路由表配置����,直接用主機的靜態路由表定義路由�,整個過程沒有NAT��,沒有Tunnel封包拆包過程����。
使得數據包的體積減小�,降低了網絡開銷�����,所以只要理論上layer3可達的網絡環境�����,同時對協議支持的要求不是太苛刻(由于是layer3
的解決方案�����,所以只支持TCP����、UDP���、ICMP協議)同時對性能����、吞吐量����、網絡延遲有要求的場景都是適合的����。當然其他的解決方案也有他們的適用場景��,具體大家可以參考上面的那篇文章��。
小結
今天由于時間關系沒辦法把Hadoop on Docker方案的方方面面都做詳細的介紹��,因此主要選了一些重點的問題和挑戰來跟大家分享�����,主要的內容就到這里了���,但是還有一些上面提到的遺留問題沒有深入下去:
如何搭建一個存儲管理的服務來托管容器運行時生成的數據����,使得Hadoop集群能夠隨時創建�,隨時銷毀����。集群內的應用服務不需要關心運行時生成的數據存放在哪里��,如何管理等等��。
如何搭建一個容器調度管理服務�,來按照我們指定的策略分配容器運行的實際宿主機�。同時能夠根據預定義的發布更新策略��,對運行中的容器服務進行動態的滾動更新(rolling update)��。
網絡方面�,如何在一個多集群�、多租戶的環境下有效的管理和分配網絡資源���,讓各集群之間相對隔離��,又有統一的網關可以彼此訪問����。
如何對一個復雜的微服務環境進行編排和管理���。
這些都是構建一個完善云服務所不能避免的問題��,docker自身也深知這些問題�,如果細心關注docker的官方網站就會看到�����,他們也在通過docker-machine��、docker-compose�、docker-swarm等意圖為docker打造一個完整的解決方案�����,使其拜托最初人們認為docker只是一個容器引擎這樣的印象���。
魅族大數據為了能夠在生產環境中搭建一套完整的容器云服務環境����,針對這些問題實踐出了一套解決方案���,基本架構組成是
Docker 容器引擎Registry負責鏡像管理Kubernetes容器編排����,集群資源管理監控Swift 存儲服務
目前已經有30%的任務量運行在這套容器云平臺下�����,線下�、測試��、正式三套環境通過registry配合kubennetes的跨namespace調度實現任務的快速發布和更新���。
除了hadoop集群之外�,我們自己的平臺應用也正在逐步的遷移到這套環境當中���。但為了保證線上任務的穩定性���,hadoop集群和平臺應用集群是namespace和宿主機雙隔離的�。
今天的內容都是以單純的docker為主�,其他幾塊的內容以后可以在Hadoop on Container Cluster Management System和Hadoop on Cloud Operating System當中再跟大家逐一介紹���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
