醫療大數據分析管理系統的設計與科研應用
1 背景
我院半結構化電子病歷起用于2005年��,至今已積累電子病歷近50萬份���。由于病歷完成者主要是進修醫和學生�,數據質量無法滿足科研需求�����,我們又開發了科研電子病歷系統����,供科研人員在其中補充錄入普通電子病歷沒有的數據��。兩個系統共為科研數據中心的數據來源�����??蒲袛祿行牡膽么蟠筇岣吡丝蒲泄ぷ餍始皽蚀_性�。但隨著數據量和查詢維度的增加�,數據查詢和數據挖掘的速度越來越慢��。為此����,我們決定引入分布式存儲及分布式計算技術��,建立醫療大數據分析管理系統���,來提高數據處理效率��。
2 硬件系統架構
我們采用MongoDB作為存儲工具�����。首先��,因為普通關系型數據庫的每次操作都會有一致性檢查�,而MongoDB的設計沒有這個步驟����,所以MongoDB的存儲效率比普通關系型數據庫更高����。其次����,醫院總數據量低于5T����,綜合考慮數據量級及管理成本�����,沒有選擇hadoop�����。而且�,MongoDB也考慮了設備故障出現的場景���,在設計時就做了容災和故障轉移的方案�。
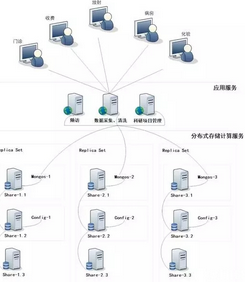
圖1 硬件系統架構
如圖1所示�����,客戶端連接3臺應用服務器��,應用服務器主要負責隨訪�、數據采集清洗和科研項目管理等業務�。因為做大數據分析��,盡管本項目對存儲量要求不高����,但對I/O及CPU運算速度卻要求很高���,故設計9臺PC服務器用來進行分布式存儲及計算��,這9臺PC服務器由三套副本集組成���,以提高存儲及計算效率���。每個副本集又由三個存儲節點組成���,每個存儲節點各有分工�,但數據相互備份�,以保證數據安全����。
MongoDB的集群部署方案中有三類角色:實際數據存儲結點(shard)��、配置文件存儲結點(config server)和路由接入結點(mongos)����。連接的客戶端直接與路由結點相連�����,從配置結點上查詢數據�,根據查詢結果到實際的存儲結點上查詢和存儲數據���。
mongos��,數據庫集群請求的入口��,所有的請求都通過mongos進行協調�����,不需要在應用程序添加一個路由選擇器�����,mongos自己就是一個請求分發中心���,它負責把對應的數據請求請求轉發到對應的shard服務器上�����。在此我們考慮部署3臺mongos作為請求的入口����,防止其中一臺宕機后所有的mongodb請求都無法操作���。
config
server���,顧名思義為配置服務器�����,存儲所有數據庫元信息(路由����、分片)的配置��。mongos本身沒有物理存儲分片服務器和數據路由信息����,只是緩存在內存里���,配置服務器則實際存儲這些數據��。mongos第一次啟動或者關掉重啟就會從
config server 加載配置信息���,以后如果配置服務器信息變化會通知到所有的 mongos 更新自己的狀態�,這樣 mongos
就能繼續準確路由���。在此我們考慮部署3臺config server 配置服務器�,就算其中一臺宕機���, mongodb集群仍然可用��。
shard�,實際的數據存儲節點����,把既往一臺服務器存儲的數據分散到3臺存儲�����,不僅存儲空間大大的擴展����,同時硬盤的讀寫��,網絡的IO��、CPU和內存都得到很大的擴展��。在Mongodb集群中只要設置好了分片規則���,通過mongos操作數據庫就能自動把對應的數據操作請求轉發到對應的分片機器上�����。同時每個分片有3臺服務器組成副本集(Replica
Set) ����,保證同一份數據存儲三份��。
3 軟件系統架構
院內醫療數據大量分散存儲在HIS�、LIS�����、EPR�、PACS等子系統中�,院外數據主要存儲在隨訪系統中�。這些數據具有多源相關性��、異構性��、海量高速性的特點��,有效的數據整合是大數據分析的前提��。首先�,所有子系統數據通過醫院系統集成平臺進行采集�����,然后通過解析�、映射��、標準化等手段進行加工處理�,最后存儲于數據倉庫中�����。數據倉庫中的數據通過聚合統計��、結構化����、歸一等技術手段�,為大數據查詢���、挖掘�����、隨訪����、科研項目管理等應用系統提供數據支撐,具體如圖2所示��。
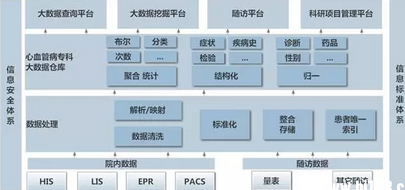
圖2 軟件系統架構
4 應用效果分析
我院科研大數據分析管理系統啟用后效果明顯����,到目前為止已建立20個專業科研數據庫����,支持了15個科研項目�����。完成各類科研查詢200余項次�,發表論文上百篇�����,其中SCI文章數十篇��?�?蒲泄ぷ骺冃чL期在北京市醫管局系統名列前茅����?����?蒲腥藛T普遍反映工作效率有很大改善���。
5 目前存在的不足
5.1數據分析與建模中存在的問題
首先��,醫療信息系統通常不是為了科研和數據分析設計的��。從數據分析的角度看�����,醫療數據通常比較復雜���,醫療數據建模與醫療業務流程關系密切�����,需要不同領域的知識���,包括醫學�����、生物統計學��、流行病學和信息學等����。在某些涉及基因療法的醫學數據中���,還需要有基因學領域的專家�。僅憑HIS廠商是無法實現的���。因此如何協調好各領域專家�����,建立行之有效的數據模型是項目成敗的關鍵����。
5.2 醫學自然語言處理難度大���,影響數據質量
由于大量詳細的病人信息以文本形式存儲�,而文本描述的信息通常存在歧義和很多非標準化描述��,如何把這些非結構化數據轉化為統一的結構化數據是醫學信息處理的重要步驟����。自然語言處理是解決方案之一�。將非結構化醫療數據轉化為結構化數據需要一系列醫學自然語言處理技術�����,包括:醫學名實體識別�,名實體自動編碼���,名實體修飾詞識別���,時間信息抽取等�。作為信息抽取的關鍵技術��,醫學信息抽取一直是醫學自然語言處理的研究熱點��。
5.3 病案質量欠佳
科研數據中心的數據是需要經過結構化���、標準化處理后才能存儲的��。這些數據要求以病例個體為單位�����,以時間為線索����,按照開放的標準架構進行組織存儲����,如HL7�����、CDA����,保證病例數據的可用性和可擴展性���。提供靈活的數據檢索能力���,方便查找符合條件的病例����,并通過數據輸出接口將數據導出成為標準的�����,可供第三方平臺處理的數據格式�。
臨床科研對病案質量要求更高����,低質量的病案會直接導致臨床科研結果的偏差����。因此����,嚴謹的病歷書寫規范及數據校驗�,對每一個數據元素進行標準化定義�,是必不可少的步驟�。
5.4 患者提供隨訪數據的依從性有待提高
隨訪數據對于醫學科研的意義不言而喻���。在實踐過程中��,我們發現心腦血管疾病人群大多為老年人�����,而老年人對于電子設備操作不熟練����,影響了數據采集的及時性和準確性����。未來應通過可穿戴設備�����、遠程會診�����、異地醫療機構信息系統互聯互通等方式提高患者����,特別是外地患者隨訪的依從性�����。
6 結論與展望
醫療衛生行業的數據資源為大數據技術應用提供了條件����。目前醫療大數據的相關標準與軟件應用等研究仍處在起步階段����,開拓空間大�,提供機會多���,但也面臨諸多現實問題����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
