SPSS統計分析案例:對應分析
兩個分類變量間的關系����,無法直接使用常見的皮爾遜相關系數來表述�����,多采用頻數統計�����、交叉表卡方檢驗等過程進行處理�����,當分類變量的取值較多時����,列聯表頻數的形式就變得更為復雜�,很難從中歸納出變量間的關系�。
對應分析���,則是解決分類變量間關系這個復雜問題的有力武器���。也稱為相應分析���,是一種多元統計分析方法�,目的是在同時描述各變量分類間關系時�,在一個低維度空間中對對應表中的兩個分類變量進行關系的描述����。
常見應用領域如市場研究分析����、競爭分析等�。
一先看一個案例
對于男性而言���,個人職位是否與吸煙有關�,假設有人收集了這樣的一組數據��,如下:
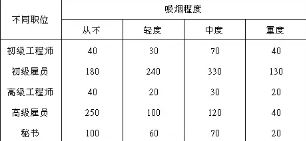
數字表示人數��,僅從交叉表內數據大小按照熱度區分的話����,效果大概是這個樣子���,紅色越深的格子表示人數越多:
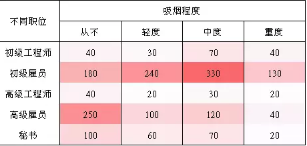
我們發現初級雇員普遍吸煙���,中度最多�����,其他的表現并不明顯��,總體上很難發現什么規律�����。
除了熱圖之外���,還可以考慮常見的條形圖���,效果如下:
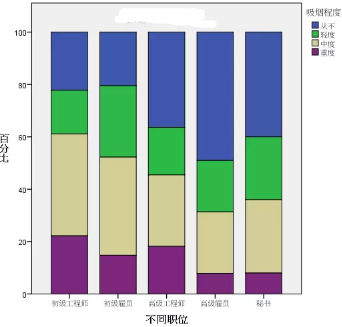
可視化的效果要比前面熱圖好很多��,給人的直觀感覺是�����,職位較高的男性���,重度吸煙的比例較低���,多數從不吸煙�����。
經過以上兩種圖示化方法的預處理��,我們能從其中總結職位和吸煙關系的把握并不大�����。
二SPSS交叉表卡方檢驗
熟悉SPSS統計分析的人可能還會想到��,是否可以先采用交叉表卡方檢驗來觀察職位和吸煙之間的關系呢�����?

在SPSS的數據視圖下����,對數據按頻數變量進行加權���,然后依次點擊【分析】→【描述統計】→【交叉表】����,在【交叉表:統計】對話框內勾選【卡方】����,其他參數默認設置�����。來看結果:
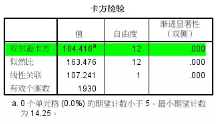
原假設職位和吸煙兩個變量間相互獨立���,漸進顯著性小于0.01��,說明兩個變量間不完全獨立��,不同職位其吸煙程度有著顯著差別���。
卡方檢驗的結果給我們吃下一顆放心丸子��,職位和吸煙之間的關系值得深入研究��,但它們之間的關系到底應該如何描述呢�?前面嘗試的熱力圖���、條形圖���、交叉表卡方檢驗均沒有給出完美結論�����。
三SPSS簡單對應分析
之所以前面先講述三種方法����,主要目的是告訴大家��,對應分析實際上也是一種數據可視化的技術��,同時它也能輸出卡方檢驗�����,下面具體來看����。
步驟1:案例數據導入SPSS軟件
SPSS對應分析對數據的要求是按變量存儲����,一般包括三個變量����,兩個名義變量和一個頻數變量�����,如果原始數據在Excel文件中是一個二維表��,需要首先將其轉換為一維表格�����,再導入SPSS軟件�。
小蚊子老師主編的暢銷書《誰說菜鳥不會數據分析》(P164)中介紹過實用方法��,在Excel數據文件中����,采用【數據透視表向導】功能��,利用【多重合并計算數據區域】的方法�����,快速地實現二維表轉為一維表�����,我在 SPSS常見問題答疑電子書 中也有類似的講述��,對此感興趣的可以參考學習�����。
數據較少時�,最簡單的方法就是復制粘貼���,也可以快速實現二維表轉一維表���。不管如何處理���,最終導入SPSS的數據文件長這樣:
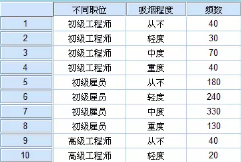
步驟2:數據加權
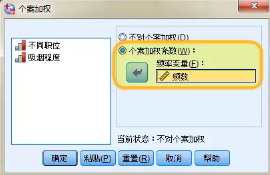
我們的分析任務是搞清楚職位和吸煙程度兩個名義變量的關系�����,要對他們進行量化考察�,需要用頻數數據加權���,SPSS數據視圖下���,依次點擊菜單【數據】→【個案加權】�����,將頻數數據移入右側【頻率變量】框內�,對職位和吸煙兩個變量進行加權����。
步驟3:對應分析主面板參數設置
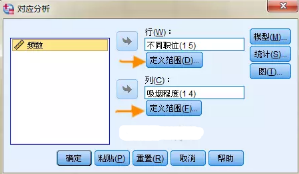
菜單欄中依次點擊【分析】→【降維】→【對應分析】����,打開對應分析主面板�,依次將【不同職位】【吸煙程度】兩個名義變量移入行和列框內��。
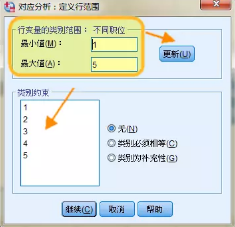
點擊下方【定義范圍】按鈕��,以定義行范圍為例�����,行變量【不同職位】有5個分類水平����,標簽值從小到到依次為1-5���,所以最小值輸入數字“1”�,最大值輸入數字“5”��,然后點擊右側【更新】按鈕�,此時下方的【類別約束】框內自動出現1-5一個序列��,類似操作�����,完成對列變量范圍的定義���。點擊【繼續】返回主面板�。
步驟4:對應分析模型參數設置
在主面板上點擊【模型】按鈕�����,打開模型對話框���。
一般默認采取2維���,距離測量勾選【卡方】����。對應分析也是一種降維技術�,通常選擇在一個二維表和二維圖形中考察分類變量間的關系���。
行和列變量間的距離測度軟件默認選擇【卡方】�����,當用卡方測量距離時����,SPSS軟件只默認選擇【除去行列平均值】作為標準化方法��。
最底部的【正態化方法】相對比較復雜�����,理解起來有一定難度�,建議選擇軟件默認選項【對稱】�����,檢查兩個變量分類間的差異或相似���。
點擊【繼續】按鈕��,返回主面板�����。
步驟5:對應分析統計參數設置
軟件默認勾選【對應表】【行點概述】【列點概述】����,點擊【繼續】按鈕��,返回主面板����。
步驟6:對應分析圖參數設置
對應分析最重要的結果之一�����,就是對應圖����,主面板上點擊【圖】按鈕�,打開圖對話框��,散點圖選項中默認勾選【雙標圖】��,也就是我們最終想要的對應圖了��。其他默認設置��,點擊【繼續】按鈕�,返回主面板���。
最后在主面板中點擊【確定】按鈕��,SPSS軟件開始執行對應分析�。
四SPSS對應分析結果解讀
結果1�����、對應表
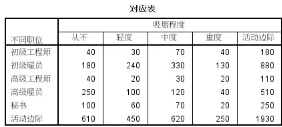
對應表實際上就是交叉表����,行與列交叉的單元格顯示為頻數���,行與列的活動邊際��,具體為對應行和列的和�。對應表看看即可�,了解一下�����,不用深究�����。
結果2���、模型摘要表
模型摘要表是關鍵結果之一�����,重點考察�����。

此表類似于因子分析的總方差表�,第一列【維】較抽象�����,可以理解為因子分析的因子��,第2-5列分別為奇異值���、慣量����、卡方值及sig值���,隨后給出各個維度所能解釋兩個變量關系的百分比�����。
首先來看卡方檢驗的結果����,卡方值=164.416�,顯著性Sig值=0.000<0.01�,表明此次分析的兩個名義變量�,職位和吸煙程度不完全獨立���,存在一定關系�,這和前面交叉表卡方檢驗結果一致�����。
卡方檢驗通過之后�,再來解讀對應分析的其他結果更有意義���。
摘要表數據表明��,前兩個維度累積慣量可解釋99.5%的信息�,效果非常不錯�����,此次分析較成功���。
結果3���、行/列點總覽
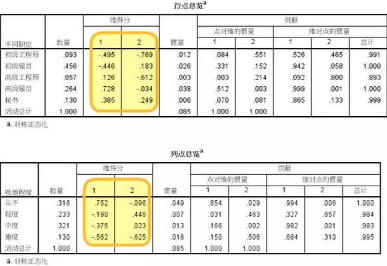
這兩個表格���,主要輸出各類別在各維度上的得分�����,后續最重要的對應圖�����,將依據這兩組維度得分進行繪制�����。
結果4����、對應圖
對應分析關鍵結果之一���,重點考察����。
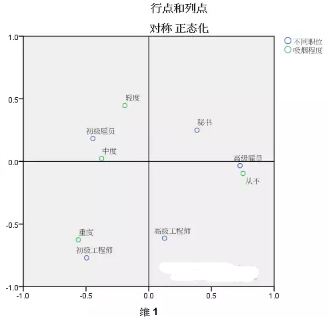
模型摘要表中�,我們已經確認前兩個維度解釋能力很棒��,那么SPSS軟件默認將采用這兩個維度的得分制作二維散點圖�,也就是現在的對應圖���。
此時我們可以看到�����,不同職位的5個類別和吸煙程度的4個類別被標記為不同的顏色進行區分���,職位點和吸煙點間距離有遠有近����,距離的遠近包含了它們之間的關系�����。
總體觀察來看�����,容易發現初級雇員和中度距離較近����,可以理解為初級雇員多為中度吸煙�;而高級雇員和從不吸煙的距離比較近���,說明高級別雇員很少吸煙�����。此外職別最低的初級工程師和重度吸煙較近����,說明這個級別的職工重度吸煙居多��。
對應分析對應圖的解讀做過總結�����,一共有7種解讀的方式�,按照四象限以及市場定位的方法��,本例分析的對應圖可以作出如下優化:
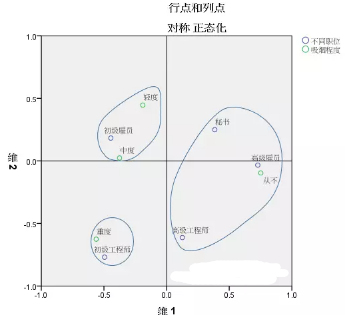
以維度1原點為界�,吸煙程度中的輕度�����、中度�、重度均在左側�,而從不吸煙則單獨出現在右側��,說明從不吸煙和其他三種類別區別較大����,與此對應的是����,高級工程師和高級雇員這三個職位也集中在右側�����,可以理解為職別較高的人最有可能是從不吸煙��。采用同樣的方式�����,容易發現���,初級雇員與輕度和中度吸煙距離較近�����,職別最低的初級工程師與重度吸煙距離近����,這和總體觀察時的結論一致�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
