你真的會玩SQL嗎�?之邏輯查詢處理階段
最近要對數據庫進行優化��,但由于工作項目中已經很少親自寫SQL而且用的都不是很復雜的語句����,所以有些生疏了����,于是翻翻N年前的筆記資料�,想以此來記錄回顧總結一些實用的SQL干貨讓大家來學習���,若有不對之處可提出�。
記得剛出來行走江湖的時候也是只會增�、刪�、改��、查四大法寶��,一般公司沒有多少復雜的業務���,所以就夠用了����。但后來看著大神會寫個幾百行的SQL存儲過程就感覺自己是不是弱爆了�。
如今是大數據的時代���,對數據的處理要求越來越重視���,要出各種數據報表����,因此百萬數據處理速度�,數據庫明顯比后臺邏輯處理的優勢不是一個別���。
下面進入正題�����,寫了多年的SQL�,你真的玩會了SQL嗎�?
在此我想再次提示一個數據處理的中心思想���,SQL數據處理是集合思維�,不要用邏輯思維來思考��。
文中的示例來自自己的積累和TSQL2008技術內幕���。
基礎知識普及
對于教條式的定義請自己去查����,此處不會涉及到文鄒鄒的知識��,但還是強調一下基礎的重要性��,即使你理解了所有的概念��,但當組合起來用時也會一頭霧水���。
邏輯查詢處理階段
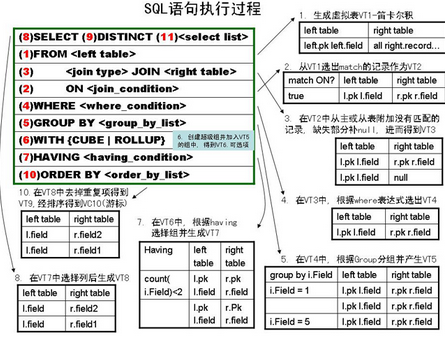
在以上的10個處理步驟中, 每一步的處理都生成一個虛擬表來作為下一步的輸入. 虛擬表對于調用者或輸出查詢來說是不存在的, 僅在最后步驟生成的表才會返回給調用者或者輸出查詢. 如果某一子句沒有出現在SQL語句中, 這一步就被簡單跳過..
這10個具體步驟是:
1.FROM: from子句中的兩個表首先進行交叉連接(笛卡爾積), 生成虛擬表VT1���。
2.ON:
on條件作用在VT1上, 將條件為True的行生成VT2�����。
3.OUTER: 如果outer join被指定, 則根據外連接條件,
將左表or右表or多表的未出現在VT2查詢結果中的行加入到VT2后生成VT3��。
4.WHERE: VT3表中應用Where條件,
結果為真的行用來生成VT4���。
5.GROUP BY: 根據Group by指定的列, 將VT4的行組織到不同的組中,
生成VT5����。
6.CLUB|ROLLUP: 超級組(分組之后的分組)被添加到VT5中, 生成VT6���。
7.HAVING: Having用來篩選組,
VT6上符合條件的組將用來生成VT7���。
8.SELECT: select子句用來選擇指定的列, 并生成VT8��。
9.DISTINCT:
從VT8中刪除重復的行后, VT9被生成�。
10.ORDER BY: 根據Order by子句, VT9中的行被排序, 生成游標10���。
注意事項:
第一步中FROM: 需要對兩表同時存在的列添加前綴, 以免混淆.
第二步中ON: 在SQL特有的三值邏輯(true,false,unknown)中, unkown的值也是確定的, 只是在不同情況下有時為true,
有時為false. 一個總的原則是: unknown的值非真即假, 非假即真. 也就是時說, unknown只能取true和false里面的一個值,
但是unknown的相反還是unknown.如:
在ON�����、WHERE和HAVING中做過濾條件時, unknown看做false;
在CHECK約束中, unknown被看做是true;
在條件中, 兩個NULL的比較結果還是Unknown.
在UNIQUE和PRIMARY KEY約束����、排序和分組中, NULL被看做是相等的. 例如Group by 將null分為一組, 而order
by將所有null排在一起.
第三步中OUTER: 如果多余兩張表, 則將VT3和FROM中的下一張表再次執行從第一步到第三步的過程.
第四步中WHERE: 由于此刻沒有分組, 也沒有執行select所以, where子句中不能寫分組函數, 也不能使用表的別名. 并且, 只有在外連接時,
on和where的邏輯才是不同的, 因此建議連接條件放在on中.
第五步中GROUP BY: 如果查詢中包含Group by 子句, 那么所有的后續操作(having,
select等)都是對每一組的結果進行操作.
Group by子句中可以使用組函數, 在Sql 2000中一旦使用組函數, 其后面的步驟將都不能處理, 而在
Sql2005中沒有這個限制.
第六步不常用, 略過.
第七步中HAVING: having表達式是僅有的分組條件. 注意: count(*)不會忽略掉null, 而count(field)會;
此外分組函數中不支持子查詢做輸入.
第八步中SELECT: 如果包含Group By子句, 那么在第5步后將只能使用Group By子句中出現的列, 如果要使用其他原始列則,
只能使用組函數.
另外, select在第八步才執行, 因此別名只能第八步之后才能使用, 并且只能在order by中使用.
第九步中DISTINCT: 當使用Group By子句時, 使用Distinct是多余的, 他不會刪除任何記錄.
第十步中ORDER BY: 按Order by子句指定的列排序后, 返回游標VC10.
別名只能在Order by子句中使用.
如果定義了Distinct子句, 則只能排序上一步中返回的表VT9, 如果沒有指定Distinct子句, 則可以排序不再最終結果集中的列. 例如:
如果不加Distinct則Order by可以訪問VT7和VT8中的內容.
這一步最不同的是它返回的是游標而不是表, Sql是基于集合論的, 集合中的元素師沒有順序的, 一個在表上引用Order
by排序的查詢返回一個按照特定特定物理順序組織的對象—游標. 所以對于視圖����、子查詢�、派生表等均不能將order by結果作為其數據來源.
建議: 使用表的表達式時, 不允許使用order by子句的查詢, 因此除非你真的要對行排序, 否則不要使用order by 子句.
內容為 RJ 寫的�����,邏輯非常清楚�,值得花點時間理解�,再次強調是因為復雜的集合數據處理過程中會得到不是你想要的結果���,這時就要你自己腦袋當SQL處理器來推出結果查出問題��,可能大多數寫了幾年的SQL都還沒弄明白��,但到了用時還是提前理解下�,非常重要����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
