R語言之數據管理
數據挖掘最重要的一環就是如何管理你的數據���,因為原始數據一般都不能直接用來進行分析��,需要對原始數據進行增加衍生變量�、數據分箱�、數據標準化處理���;對因子型變量進行啞變量處理�����;數據抽樣和類失衡數據處理����。本專題會詳細介紹以上內容的數據挖掘技術及R語言實現����。
數據轉換
對于數據挖掘分析建模來說���,數據轉換(Transformation)是最常用�����、最重要���,也是最有效的一種數據處理技術����。經過適當的數據轉換后����,模型的效果常??梢杂忻黠@的提升��,也正因為這個原因�����,數據轉換成了很多數據分析師在建模過程中最喜歡使用的一種數據處理手段��。另一方面���,在絕大數數據挖掘實踐中��,由于原始數據��,在此主要是指區間型變量(Interval)的分布不光滑(或有噪聲)�����,不對稱分布(Skewed
Distributions)�����,也使得數據轉化成為一種必須的技術手段�。
按照采用的轉換邏輯和轉換目的的不同��,數據轉換主要分為以下四大類:
產生衍生變量�����。
這類轉換的目的很直觀�,即通過對原始數據進行簡單�����、適當地數據公式推導��,產生更有商業意義的新變量����。例如���,我們收集了最近一周的付費人數和付費金額���,此時想統計每日的日均付費金額(arpu=revenue/user)����,此時就可以通過前兩個變量快速實現����。
> # 創建數據集
> w <- data.frame(day = 1:7,
+ revenue = sample(5000:6000,7),
+ user = sample(1000:1500,7))
> w
day revenue user
1 1 5391 1223
2 2 5312 1418
3 3 5057 1343
4 4 5354 1397
5 5 5904 1492
6 6 5064 1113
7 7 5402 1180
> # 增加衍生變量人均付費金額(arpu)
> w$arpu <- w$revenue/w$user
> w
day revenue user arpu
1 1 5391 1223 4.408013
2 2 5312 1418 3.746121
3 3 5057 1343 3.765450
4 4 5354 1397 3.832498
5 5 5904 1492 3.957105
6 6 5064 1113 4.549865
7 7 5402 1180 4.577966
從中不難發現����,得到這些衍生變量所應用到的數據公式很簡單�����,但是其商業意義是明確的�,而且跟具體的分析背景和分析思路密切相關�。
衍生變量的產生主要依賴于數據分析師的業務熟悉程度和對項目思路的掌握程度���,如果沒有明確的項目分析思路和對數據的透徹理解���,是無法找到有針對性的衍生變量的�。
改善變量分布特征的轉換�����,這里主要是指不對稱分布所進行的轉換��。
在數據挖掘實戰中��,有些數據是不對稱的�����,嚴重不對稱出現在自變量中常常會干擾模型的擬合�,最終會影響模型的效果和效率�。如果通過各種數學變換��,使得變量的分布呈現(或者近似)正態分布��,并形成倒鐘形曲線�����,那么模型的擬合常常會有明顯的提升�����,轉換后自變量的預測性能也可能得到改善�,最終將會提高模型的效果和效率���。
常見的改善分布的轉換措施如下:
取對數(Log)
開平方根(SquareRoot)
取倒數(Inverse)
開平方(Square)
取指數(Exponential)
這邊以取對數為例進行說明��。在R的擴展包ggplot2中自帶了一份鉆石數據集(diamonds)��,我們從中抽取1000個樣本最為研究對象�,研究數據中變量carat(克拉數)�、price(價格)的數據分布情況�����,并研究兩者之間的關系���,最后利用克拉數預測鉆石的價格�����。
> library(ggplot2)
> set.seed(1234)
> dsmall <- diamonds[sample(1:nrow(diamonds),1000),] # 數據抽樣
> head(dsmall) # 查看數據前六行
carat cut color clarity depth table price x y z
6134 0.91 Ideal G SI2 61.6 56 3985 6.24 6.22 3.84
33567 0.43 Premium D SI1 60.1 58 830 4.89 4.93 2.95
32864 0.32 Ideal D VS2 61.5 55 808 4.43 4.45 2.73
33624 0.33 Ideal G SI2 61.7 55 463 4.46 4.48 2.76
46435 0.70 Good H SI1 64.2 58 1771 5.59 5.62 3.60
34536 0.33 Ideal G VVS1 61.8 55 868 4.42 4.45 2.74
> par(mfrow = c(1,2))
> plot(density(dsmall$carat),main = "carat變量的正態分布曲線") # 繪制carat變量的正態分布曲線
> plot(density(dsmall$price),main = "price變量的正態分布曲線") # 繪制price變量的正態分布曲線
> par(mfrow = c(1,1))
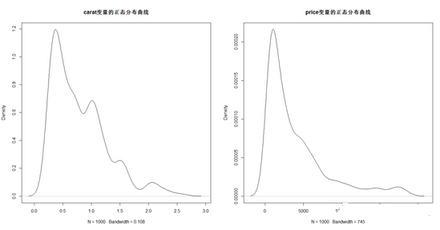
從正態分布圖可知����,變量carat和price均是嚴重不對稱分布�����。此時我們利用R語言中的log函數對兩者進行對數轉換����,再次繪制正態密度圖�。
> par(mfrow = c(1,2))
> plot(density(log(dsmall$carat)),main = "carat變量取對數后的正態分布曲線")
> plot(density(log(dsmall$price)),main = "price變量取對數后的正態分布曲線")
> par(mfrow = c(1,1))
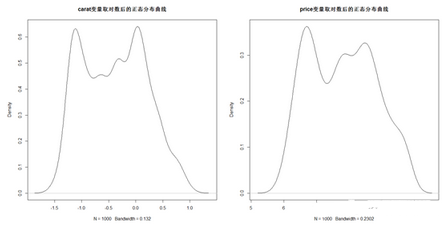
可見�����,經過對數處理后�����,兩者的正態分布密度曲線就對稱很多��。最后��,讓我們一起來驗證對原始數據建立線性回歸模型與經過對數變量后再建模的區別����。
> # 建立線性回歸模型
> fit1 <- lm(dsmall$price~dsmall$carat,data = dsmall) # 對原始變量進行建模
> summary(fit1) # 查看模型詳細結果
Call:
lm(formula = dsmall$price ~ dsmall$carat, data = dsmall)
Residuals:
Min 1Q Median 3Q Max
-8854.8 -821.9 -42.2 576.0 8234.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2391.74 97.44 -24.55 <2e-16 ***
dsmall$carat 7955.35 104.45 76.16 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1582 on 998 degrees of freedom
Multiple R-squared: 0.8532, Adjusted R-squared: 0.8531
F-statistic: 5801 on 1 and 998 DF, p-value: < 2.2e-16
> fit2 <-lm(log(dsmall$price)~log(dsmall$carat),data=dsmall) # 對兩者進行曲對數后再建模
> summary(fit2) # 查看模型結果
Call:
lm(formula = log(dsmall$price) ~ log(dsmall$carat), data = dsmall)
Residuals:
Min 1Q Median 3Q Max
-1.07065 -0.16438 -0.01159 0.16476 0.83140
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.451358 0.009937 850.5 <2e-16 ***
log(dsmall$carat) 1.686009 0.014135 119.3 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2608 on 998 degrees of freedom
Multiple R-squared: 0.9345, Adjusted R-squared: 0.9344
F-statistic: 1.423e+04 on 1 and 998 DF, p-value: < 2.2e-16
通過對比MultipleR-squared發現�,模型1的R平方是0.8532����,模型2的R平方是0.9345����,R平方的值是越接近1說明模型擬合的越好���,所以經過對數處理后建立的模型2優于模型1��。我們也可以通過在散點圖繪制擬合曲線的可視化方式進行查看����。
> # 在散點圖中 繪制擬合曲線
> par(mfrow=c(1,2))
> plot(dsmall$carat,dsmall$price,
+ main = "未處理的散點圖及擬合直線")
> abline(fit1,col="red",lwd=2)
> plot(log(dsmall$carat),log(dsmall$price),
+ main = "取對數后的散點圖及擬合直線")
> abline(fit2,col="red",lwd=2)
> par(mfrow=c(1,1))
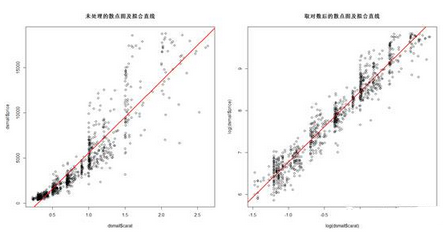
可見����,取對數后繪制的散點更集中在紅色的線性回歸線上��。
區間型變量的分箱轉換�。
分箱轉換(Binning)就是把區間型變量 (Interval)轉換成次序型變量(Ordinal)�,其轉換的目的如下:
降低變量(主要是指自變量)的復雜性����,簡化數據���。比如��,有一組用戶的年齡����,原始數據是區間型的��,從10~60歲���,每1歲都是1個年齡段����;如果通過分箱轉換�����,每10歲構成1個年齡組�����,就可以有效簡化數據���。R語言中有cut函數可以輕易實現數據分箱操作��。
> age <- sample(10:60,15)
> age <- sample(10:60,15) # 創建年齡變量
> age
[1] 26 41 59 33 50 16 28 18 52 30 25 44 37 23 47
> age_cut <- cut(age,breaks = seq(10,60,10))
> age_cut
[1] (20,30] (40,50] (50,60] (30,40] (40,50] (10,20] (20,30] (10,20] (50,60]
[10] (20,30] (20,30] (40,50] (30,40] (20,30] (40,50]
Levels: (10,20] (20,30] (30,40] (40,50] (50,60]
> table(age_cut) # 查看不同年齡段的人數
age_cut
(10,20] (20,30] (30,40] (40,50] (50,60]
2 5 2 4 2
可見��,利用cut函數分箱得到的區間段是左開右閉的����,我們通過table函數查看不同區間段的人數����,發現有5人在20到30歲之間����。
針對區間型變量進行的標準化操作��。
數據的標準化(Normalization)轉換也是數據挖掘中常見的數據轉換措施之一�,數據標準轉換的目的是將數據按照比例進行縮放�����,使之落入一個小的區間范圍之內���,使得不同的變量經過標準化處理后可以有平等分析和比較的基礎����。
最簡單的數據標準化轉換是Min-Max標準化�����,也叫離差標準化��,是對原始數據進行線性變換�,使得結果在[0,1]區間�,其轉換公式如下:
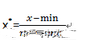
其中���,max為樣本數據的最大值���,min為樣本數據的最小值�。
在R中�����,我們可以利用max函數和min函數非常輕易地構建一個Normalization函數�����,實現Min-Max標準化過程���。
> dat <- sample(1:20,10) # 從1到20中有放回隨機抽取10個
> normalization <- function(x) {
+ (x-min(x))/(max(x)-min(x))
+ } # 構建Min-Max標準化的自定義函數
> dat # 原始數據
[1] 19 5 8 13 15 18 16 1 3 9
> normalization(dat) # 經過Min-Max標準化的 數據
[1] 1.0000000 0.2222222 0.3888889 0.6666667 0.7777778 0.9444444 0.8333333
[8] 0.0000000 0.1111111 0.4444444
另一種常用的標準化處理是零-均值標準化�,即把數據處理稱符合標準正態分布�。也就是均值為0���,標準差為1���,轉換公式如下:
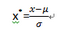
其中����,μ為所有樣本數據的均值�����,σ為所有樣本數據的標準差�。
在R中���,用scale( )函數得到Z-Score標準化����。其表達形式為:scale(x, center = TRUE, scale = TRUE)�����。
總體來說�����,數據變換的方式多種多樣�,操作起來簡單�、靈活���、方便�,在 實踐應用中的價值也是比較明顯的����。
2. 數據抽樣
“抽樣”對于數據分析和挖掘來說是一種常見的前期數據處理技術和階段�����,之所以要采取抽樣,主要原因在于如果數據全集的規模太大����,針對數據全集進行分析運算不但會消耗更多的運算資源����,還會顯著增加運算分析的時間����,甚至太大的數據量有時候會導致分析挖掘軟件運行時的崩潰�。而采用了抽樣措施�����,就可以顯著降低這些負面的影響�;另一個常見的需要通過抽樣來解決的場景就是:我們需要將原始數據進行分區���,其中一部分作為訓練集����,用來訓練模型��,剩下的部分作為測試集�,用來對訓練好的模型進行效果評估���。
R中的sample( )函數可以實現數據的隨機抽樣��?����;颈磉_形式為:
sample(x, size, replace = FALSE, prob = NULL)
其中x是數值型向量�����,size是抽樣個數�����,replace表示是否有放回抽樣���,默認FALSE是無放回抽樣�,TURE是有放回抽樣��。
> # sample小例子
> set.seed(1234)
> # 創建對象x�����,有1~10組成
> x <- seq(1,10);x
[1] 1 2 3 4 5 6 7 8 9 10
> # 利用sample函數對x進行無放回抽樣
> a <- sample(x,8,replace=FALSE);a
[1] 2 6 5 8 9 4 1 7
> # 利用sample函數對x進行有放回抽樣
> b <- sample(x,8,replace=TRUE);b
[1] 7 6 7 6 3 10 3 9
> # 當size大于x的長度
> (c <- sample(x,15,replace = F))
Error in sample.int(length(x), size, replace, prob) :
cannot take a sample larger than the population when 'replace = FALSE'
> (c <- sample(x,15,replace = T))
[1] 3 3 2 3 4 4 2 1 3 9 6 10 9 1 5
可見�,b中抽取的元素有重復值���。如果我們要抽取的長度大于x的長度����,需要將replace參數設置為T(有放回抽樣)�����。
有時候����,我們想根據某一個變量對數據進行等比例抽樣(即抽樣后的數據子集中的該變量各因子水平占比與原來相同)�����,雖然我們利用sample函數也可以構建�����,但是這里給大家介紹caret擴展包中的createDataPartition函數���,可以快速實現數據按照因子變量的類別進行快速等比例抽樣�。其函數基本表達形式為:
createDataPartition(y,times = 1,p = 0.5,list = TRUE,groups = min(5, length(y)))
其中y是一個向量�����,times表示需要進行抽樣的次數����,p表示需要從數據中抽取的樣本比例��,list表示結果是否是list形式��,默認為TRUE����,groups表示果輸出變量為數值型數據��,則默認按分位數分組進行取樣���。
以鳶尾花數據集為例��,我們想按照物種分類變量進行等比例隨機抽取其中10%的樣本進行研究�。
> # 載入caret包�,如果本地未安裝就在線安裝caret包
> if(!require(caret)) install.packages("caret")
載入需要的程輯包:caret
載入需要的程輯包:lattice
載入需要的程輯包:ggplot2
Warning message:
程輯包‘ggplot2’是用R版本3.3.3 來建造的
> # 提取下標集
> splitindex <- createDataPartition(iris$Species,times=1,p=0.1,list=FALSE)
> iris_subset <- iris[splitindex,]
> prop.table(table(iris$Species)) # 查看原來數據集Species變量各因子占比
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
> prop.table(table(iris_subset$Species))# 查看子集中Species變量各因子占比
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
可見�����,抽樣后的子集中Species中各類別的占比與原來數據集的相同��。
3. 類失衡數據處理
另外一個常見的需要通過抽樣來解決的場景就是:在很多小概率事件�、稀有事件的預測建模過程中�����,比如信用卡欺詐事件��,在整個信用卡用戶中����,屬于惡意欺詐的用戶只占0.2%甚至更少��,如果按照原始的數據全集��、原始的稀有占比來進行分析挖掘��,0.2%的稀有事件是很難通過分析挖掘得到有意義的預測和結論的���,所有對此類稀有事件的分析建模���,通常會采取抽樣的措施�,即認為增加樣本中“稀有事件”的濃度和在樣本中的占比�����。對抽樣后得到的分析樣本進行分析挖掘��,可以比較容易地發現稀有時間與分析變量之間的價值���,有意義的一些關聯性和邏輯性�����。
克服類失衡問題常用的技術有以下兩種:
偏置學習過程的方法��,它應用特定的對少數類更敏感的評價指標����。
用抽樣方法來操作訓練數據�����,從而改變類的分布���。
有多種抽樣方法用于改變數據集中類的失衡�����,常用的有以下兩種:
欠采樣法����,它從多數類中選擇一小部分案例���,并把它們和少數類個案一起構成一個有更加平衡的類分布的數據集�。
過采樣法����,它采用另外的工作模式�����,使用某些進程來復制少數類個案�。
在R中��,DMwR包中的SMOTE(
)函數可以實現SMOTE方法��。主要參數有如下三個:perc.over:過采樣時�,生成少數類的樣本個數;k:過采樣中使用K近鄰算法生成少數類樣本時的K值��,默認是5��;perc.under:欠采樣時����,對應每個生成的少數類樣本����,選擇原始數據多數類樣本的個數����。例如����,perc.over=500表示對原始數據集中的每個少數樣本����,都將生成5個新的少數樣本�����;perc.under=80表示從原始數據集中選擇的多數類的樣本是新生的數據集中少數樣本的80%���。
> # 加載DMwR包
> if(!require(DMwR)) install.packages("DMwR")
載入需要的程輯包:DMwR
載入需要的程輯包:lattice
載入需要的程輯包:grid
> dat <- iris[, c(1, 2, 5)]
> dat$Species <- factor(ifelse(dat$Species == "setosa","rare","common"))
> table(dat$Species)
common rare
100 50
> # 進行類失衡處理
> # perc.over=600:表示少數樣本數=50+50*600%=350
> # perc.under=100:表示多數樣本數(新增少數樣本數*100%=300*100%=300)
> newData <- SMOTE(Species ~ ., dat, perc.over = 600,perc.under=100)
> table(newData$Species)
common rare
300 350
> # perc.over=100:表示少數樣本數=50+50*100%=100
> # perc.under=200:表示多數樣本數(新增少數樣本數*200%=50*200%=100)
> newData <- SMOTE(Species ~ ., dat, perc.over = 100,perc.under=200)
> table(newData$Species)
common rare
100 100
4. 數據啞變量處理
虛擬變量 ( Dummy Variables) 又稱虛設變量���、名義變量或啞變量��,用以反映質的屬性的一個人工變量�,是量化了的自變量�,通常取值為0或1���。引入啞變量可使線形回歸模型變得更復雜�,但對問題描述更簡明�����,一個方程能達到兩個方程的作用���,而且接近現實�。
舉一個例子�����,假如變量“性別”的取值為:男性�、女性��。我們可以增加2個啞變量來代替“性別”這個變量��,分別為性別.男性(1=男性/0=女性)��、性別.女性(1=女性/0=男性)���。
caret擴展包中的dummyVars(
)函數是專門用來處理變量啞變量處理的函數��,其表達形式為:dummyVars(formula,data, sep = ".",
levelsOnly = FALSE, fullRank = FALSE,
...)����。其中���,formula表示模型公式����,data是需要處理的數據集����,sep表示列名和因子水平間的連接符號��,levelsOnly默認是FALSE�,當為TRUE時表示僅用因子水平表示新列名��,fullRank默認是FALSE��,當為TRUE時表示進行虛擬變量處理后不需要出現代表相同意思的兩列�����。
假如有一份customers數據集��,包括id��、gender��、mood和outcome變量���,其中gender和mood都是因子型變量�,我們需要將它們進行啞變量處理��。
> customers <- data.frame(
+ id=c(10,20,30,40,50),
+ gender=c('male','female','female','male','female'),
+ mood=c('happy','sad','happy','sad','happy'),
+ outcome=c(1,1,0,0,0))
> customers
id gender mood outcome
1 10 male happy 1
2 20 female sad 1
3 30 female happy 0
4 40 male sad 0
5 50 female happy 0
> library(caret)
載入需要的程輯包:ggplot2
Warning message:
程輯包‘ggplot2’是用R版本3.3.3 來建造的
> # 啞變量處理
> dmy <- dummyVars(" ~ .", data = customers)
> trsf <- data.frame(predict(dmy, newdata = customers))
> print(trsf)
id gender.female gender.male mood.happy mood.sad outcome
1 10 0 1 1 0 1
2 20 1 0 0 1 1
3 30 1 0 1 0 0
4 40 0 1 0 1 0
5 50 1 0 1 0 0
經過啞變量處理后��,原來的變量gender變成兩列gender.female和gender.male����,變量mood變成mood.happy和mood.sad兩列����,新生成的列里面的內容均是0/1�,已經幫我們做了歸一化處理���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
