SPSS分析技術:簡單對應分析
分類型數據(包括定類數據和定序數據)在數據分析中扮演著重要的角色���,例如�����,分類型數據能夠幫助我們對每個數據記錄進行分門別類��,但是由于分類型數據的特點�,很多基于均值��、方差和標準差的分析方法就不太適用了����,通常使用的分析方法是基于頻數的卡方檢驗和邏輯回歸等����。面對變量個數少���、分類類別少的簡單局面�,卡方檢驗和二分類邏輯回歸還能夠從容應對���,一旦變量數量和變量類別多時�,分析結果的解讀就讓人頭痛了�。
例如��,研究全國34個省級行政區居民的收入水平情況�����,通過抽樣收集數據�,使用卡方檢驗能夠很容易得出不同省級行政區居民的收入水平分布有顯著性差異���,但是無法得到北京市高收入居民比例高���、云南低收入居民比例低這樣具體的結果����,也就是無法對分類變量各類別間的相關關系進行清楚展現����。對應分析是解決類別相關關系展示很好的方法�,它能夠將分類交叉表轉換為相應的對應分析圖���,從而使分類結果圖形化��、直觀化���。
對應分析原理
數據統計分析方法有個很有趣的特點��,就是名字很多��,經常出現同一個分析方法在不同書籍中的名稱不同�,真有點百家爭鳴的味道��,這是因為由人組成的社會�����,人們總是希望自己能夠青史留名���,這不足為奇����。對應分析在很多地方也被稱為同質性分析或數量化方法���。
對應分析的實質就是將交叉表里面的頻數數據作變換以后��,展現在散點圖上�,從而將抽象的交叉表信息形象化��。這個變換過程涉及到線性代數的內容�,因此在這里就不做數學公式的推導了��,草堂君在這里做個形象的解釋��。
我們以兩個分類變量的情況來介紹對應分析的原理��。學習過卡方檢驗的朋友應該知道��,卡方檢驗的實質是將實際的頻數分析與期望頻數作對比����,如果差距很大���,超過界限值��,那么就可以認為組成交叉表的兩個分類變量之間具有相關性��。舉個生活例子�����,某汽車生產企業的市場部收集了某款汽車的銷售數據���,制成頻數交叉表:如果年齡變量與選購的汽車顏色之間沒有相關關系�����,那么這些頻數應該是相似的��,沒有巨大差異����,反之���,如果這兩個分類變量間有相關關系�����,那么某個或某些單元格里的頻數將顯著大于其它單元格�����。
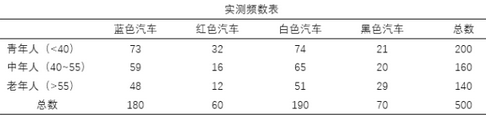
根據上表的數據�,可以制作出由期望頻數組成的交叉表�,期望頻數的計算公式為行頻數和*列頻數和/總頻數(參考第一列的計算過程)�����?���?ǚ綑z驗就是將上表的實際頻數與下表的期望頻數做逐個對比�����,算出卡方值和檢驗概率���,從而判斷兩個變量是否有顯著性差異�����。
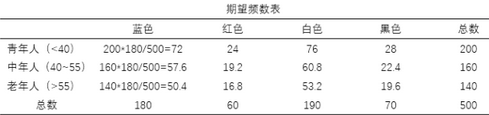
對應分析承接上面兩個表格的工作��,它首先算出每個單元格的標準化殘差��,計算公式為:
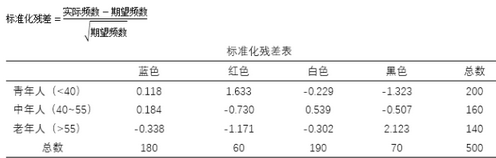
從上面的公式來看�����,標準化殘差包含了某個年齡段和某種汽車顏色的相關關系信息���,相當于相關系數�����。說到這里�����,是否想到因子分析����。是的�,對應分析進行到這里�����,下一步也是提取標準化殘差矩陣(交叉表)的公因子�����,然后將3個年齡群體和4個汽車顏色放入由公因子(新維度)組成的坐標空間內����,通過它們之間的空間距離判斷相關性強弱��。
案例分析
歐洲人的眼睛和頭發顏色可以用“絢爛多彩”來形容���,特別是北歐和東歐人�����。歐洲人頭發的顏色不僅有黑色�,還有棕色����、亞麻色����、金黃色和紅色�;眼睛的顏色有棕色���、藍色�����、灰色���、褐色和綠色�。在基因理論和技術沒有發展起來以前���,歐洲人的眼睛顏色和頭發顏色的關系一直是研究的熱點��,眼睛顏色和頭發顏色到低是隨機搭配的呢��?還是眼睛的某種顏色更多和某種頭發顏色搭配�?對應分析方法在這個問題上的研究一直被奉為經典案例�����?���;蚣夹g發展起來以后��,從基因的層面驗證了上述對應分析的結果����。

下面我們就以經典的����,Fisher在1940采集的5387名蘇格蘭人的眼睛和頭發顏色數據為例�,介紹如何使用SPSS進行簡單對應分析���,并對結果進行解釋�����。
分析思路
做簡單對應分析(只有兩個分類變量)之前����,需要對交叉表進行卡方檢驗�����,只有卡方檢驗結果顯示兩個分類變量之間具有相關性����,才有必要作對應分析���,如果兩個分類變量之間沒有相關關系���,也就失去作對應分析的必要了����。
分析步驟
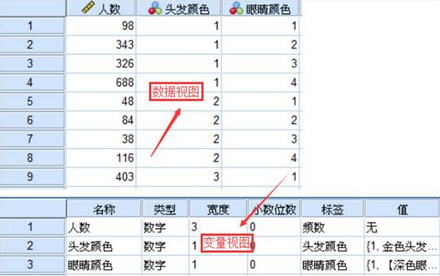
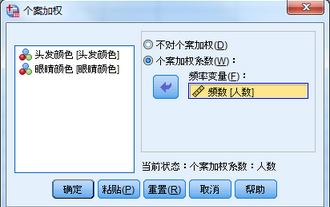
1���、個案加權處理�;大家記住����,涉及到分類數據頻數分析的情況��,大多數情況下都需要進行個案加權處理���。選擇菜單【數據】-【個案加權】�,依照下圖進行操作���,進行個案加權�。
2�、選擇菜單【分析】-【降維】-【對應分析】���,在跳出的對話框中進行如下操作�����。將頭發顏色選為行變量�����;眼睛顏色選為列變量�;點擊定義范圍�����,依據變量的分類數值填寫最小值和最大值��,然后點擊更新����。
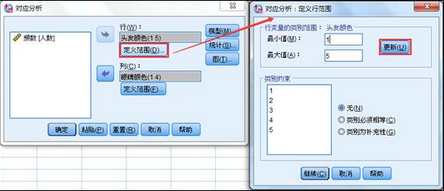
3�、其它設置保持軟件默認狀態就可以���。點擊確定�,輸出結果�。
結果解釋
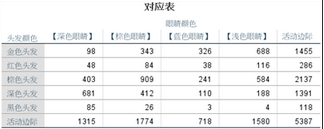
1���、交叉表格���,也就是由兩個分類變量組成的交叉列聯表����,交叉單元格內的數值代表頻數���。
2�、對應分析摘要表���;

最后一行顯示的是上方交叉列聯表的卡方檢驗結果�����,顯著性小于0.05����,說明眼睛顏色和頭發顏色之間存在相關關系��,這決定了對應分析是否有意義�。
結果顯示通過標準化殘差矩陣總共提取了三個公因子���,也就是三個維度�����,其中前面兩個維度能夠解釋原來變量99.6%的信息�����,因此第三個維度不做考慮��。
奇異值和慣量都是線性代數的概念���,慣量等于奇異值的平方�。慣量值就相當于因子分析中的特征值����,代表對應維度在解釋原始數據信息中的重要性����。
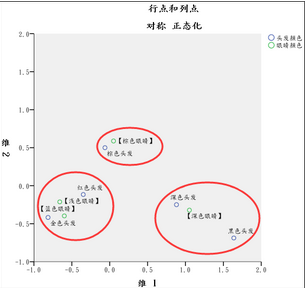
3����、行變量和列變量坐標�;這兩個表格顯示行變量和列變量中每個類別在新產生兩個維度中的坐標值����。通過這兩個表格的數據結果就能夠做出對應分析散點圖���。數量代表每個類別的人數比例��;

點對維的慣量表示分類變量中每個類別對維度的貢獻�,例如�����,第一個維度主要由眼睛顏色中的深色(0.605)和淺色(0.286)構成�;
維對點的慣量正好相反��,表示每個類別信息分別在兩個維度的比例����,例如深色眼睛的信息在第一個維度中占96.5%�,第二個維度只有3.5%�。
4�、對應分析散點圖�;從散點圖上看�����,金色頭發�����、紅色頭發與淺色眼睛和藍色眼睛的相關性強����;棕色眼睛和棕色頭發相關性強�����;深色頭發�、黑色頭發與深色眼睛的相關性強����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
