R語言︱噪聲數據處理�、數據分組—分箱法(離散化�����、等級化)
分箱法在實際案例操作過程中較為常見�,能夠將一些數據離散化�,等級化����,比如年齡段����,我們并不想知道確切的幾歲�,于是乎可以將其分組�����、分段���。
基礎函數中cut能夠進行簡單分組�����,并且可以用于等寬分箱法�。
cut函數:cut(x, n):將連續型變量x分割為有著n個水平的因子.(參考來自: R語言︱數據集分組�����、篩選)
分箱法分為等深分箱(樣本量一致�,比等寬好)���、等寬分箱(cut函數可以直接獲?���。?��。
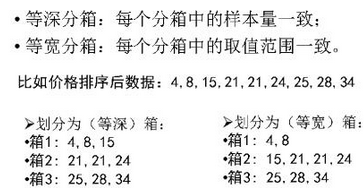
著重看一下等深分箱法,筆者在這根據課程code之上��,自己編譯了一個等深分箱函數sbdeep�。
[html]view plaincopyprint?
sbdeep=function(data,parts,xiaoz){
parts<-parts #分幾個箱
xiaoz<-xiaoz #極小值
value<-quantile(data,probs = seq(0,1,1/parts)) #這里以data等比分為4段����,步長為1/4
number<-mapply(function(x){
for (i in 1:(parts-1))
{
if(x>=(value[i]-xiaoz)&x<value[i+1])
{
return(i)
}
}
if(x+xiaoz>value[parts])
{
return(parts)
}
return(-1)
},data)
#打標簽L1L2L3L4
return(list(degree=paste("L",number,sep=""),degreevalue=number,value=table(value),number=table(number))) #將連續變量轉化成定序變量�,此時為L1,L2,L3,L4...根據parts
}
該函數是對單個序列數據進行等深分箱�,可以返回四類:
一個基于L1L2L3....的每個指標標簽序列degree�;
標簽序列值degreevalue�����,
每個百分位數對應的變量值value����,
不同百分點的數量number��。
應用一:
R語言等寬分箱小案例
R語言的等寬分箱法一般都是用cut來獲取���,但是用法來說在網上還是比較少見的�����。譬如這里有一個需求就是把連續數列����,根據等寬分箱的辦法切分開來��。這個應該怎么做呢���?
來看一個cut的案例:
[plain]view plaincopyprint?
> a <- c(1,2,3,4,5,6,4,3,2,1)
> cut(a,10)
[1] (0.995,1.5] (1.5,2] (2.5,3] (3.5,4] (4.5,5] (5.5,6] (3.5,4] (2.5,3] (1.5,2] (0.995,1.5]
Levels: (0.995,1.5] (1.5,2] (2,2.5] (2.5,3] (3,3.5] (3.5,4] (4,4.5] (4.5,5] (5,5.5] (5.5,6]
> cut(a,10,labels=F)
[1] 1 2 4 6 8 10 6 4 2 1
一個數列���,簡單的cut滯后��,就變成一個levels�����,因子型的一個區間范圍�,但是這個結果一般不是我們想要的���,我們想要對連續數據進行切割�����。那么就是用R語言中的cut函數的����,labels參數���。
可以從案例中看到�,labels=F之后��,就變成了一系列等級型的分組序號���,就像聚類一樣���,模型跑出來之后����,就給數列打了一個標簽�。那么就可以這樣選擇你想要的����,譬如我要選擇連續變量的數值上的前10%的數值:
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;













 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
