R語言與回歸分析幾個假設的檢驗
一���、從線性回歸的假設說起
對于線性回歸而言����,若要求回歸估計有一些良好性質比如無偏性�����,就需要加上一些假定條件��。比如要達到估計的無偏性�,我們通常需要加上高斯-馬爾科夫條件:
A1�����、對參數而言的線性性
A2�、樣本的隨機抽樣性
A3��、誤差的條件均值為0
A4����、不存在完全共線性
A5��、同方差假設
在上述條件上加上誤差項服從正態分布�����,就得到了經典線性回歸模型的6大假定����。保證了估計的良好性質�����。
現在我們來考慮一下這幾個條件���,它們真的十分容易達到嗎�?
我們先從比較容易滿足的的假設A4入手分析:完全共線性導致的結果是最小二乘的結果不唯一�。所以這里要求的是數據相關性不能為1��,但并不是不能有相關性�。導致完全共線性的原因不外乎以下三個:1��、錯誤的將一系列已建立線性關系的因變量包括在處理的數據中(但其實這個的相關度還是達不到1的���,但是會影響到回歸的效果�����,更加會影響到你的解釋)2���、處理虛擬變量不當導致的錯誤�����。用r個虛擬變量表示離散變量取值時�,多重共線性在所難免(這個是真正的完全共線性����,因為離散變量表達了所有的情況)3�、樣本量過小導致的無法識別���。這個也只能增加樣本量來解決問題���。
再來看A2�����,這個我們通過數據收集方式的先驗知識來判斷最優���,我們不知道是也可以通過殘差的獨立性來看��,在R的car包中提供了一個可做獨立性檢測(durbin-watson檢驗)的函數durbinWatsonTest()�����。該檢驗適用于時間獨立數據���,對于非聚集型數據并不適用�。
看A3說的是誤差項里不包括自變量的任何信息���,這個在作解釋是十分重要的�����。也可以證明均值為0的條件總是可以達到的����,通過適當變換����。
A1�、A5就沒有那么容易達到��。雖然他們對無偏性的影響并不大�,最小二乘的估計量仍是無偏且一致的(相合的)�,但是有效性時會受到影響的����。
那么����,我們現在的問題就是如何判定這兩個假定成立����?
二����、異方差的線性回歸
關于異方差我們必須注意到這樣一個事實:即便誤差具有一致的方差��,最小二乘殘差仍有不等的方差�。我們可以通過對學生殘差(主要是排除一些異常值���,讓數據平穩一些)根據擬合值繪制散點圖來辨別之�����。當然我們也有統計的辦法如Breusch-Pagan檢驗
在R中���,擴展包lmtest中的Breusch-Pagan檢驗��?��;蛘呃胏ar包中的ncv.test()函數��。二者工作的原理都是相同的��。在回歸之后���,我們可以對擬合的模型采用bptest()函數
unrestricted<-lm(z~x)
bptest(unrestricted)
這將得到檢驗的“學生化的”(studentized)結果���。如果為了保持與其他軟件結論的一致性(包括ncv.test())����,我們可以設置studentize=FALSE
我們來看一個例子:以下數據取自伍德里奇的《計量經濟學導論》均保留原數據名
library(foreign)
B<-read.dta("D:/R/data/SAVING.dta")#導入數據
library(lmtest)
result2<-lm(sav~inc+size+educ+age+black,data=B)
bptest(result2)
studentized Breusch-Pagan test
data: result2
BP =5.5756, df = 5, p-value = 0.3497 #從這里看得出數據是不具有異方差性的
C<-read.dta("D:/R/data/SMOKE.dta")
result3<-lm(cigs~log(income)+cigpric+educ+age+restaurn,data=C)
bptest(result3)
studentized Breusch-Pagan test
data: result3
BP =11.0583, df = 5, p-value = 0.05024#這里可以認為數據有異方差性�,但表現的不是特別強烈
如果去掉“學生化”我們可以得到:
>result3<-lm(cigs~log(income)+cigpric+educ+age+restaurn,data=C)
>bptest(result3,studentize=FALSE)
Breusch-Pagan test
data: result3
BP =24.6376, df = 5, p-value = 0.0001637#這里可以看出異方差性是很明顯的�。
這也說明了學生化對異方差的修正作用�����。
對smoke數據作圖分析也可以得到一個不錯的��,直觀的結果��。
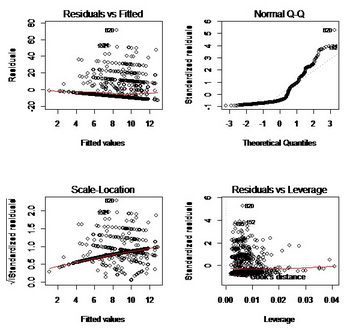
異方差的存在性影響ols估計量的有效性�����,使得t檢驗與F檢驗不再有效�����,所以存在異方差時�,必須使用異方差穩健標準誤代替標準誤���。一般的�����,我們使用white一致標準誤來做假設檢驗��。
為了計算異方差一致性的協方差矩陣�,我們可以利用car包中的hccm()函數�,而不是vcov()�����。
sandwich包中的vcovHC()命令可以實現同樣的功能���。同時利用vcovHAC()或者NeweyWest()函數可以進行異方差和自相關穩健性Newey—West估計(注1)��。
library(sandwich)
NeweyWest(result3)
neweywest<- coeftest(result3, vcov = NeweyWest(result3))
print(neweywest)#得出穩健的估計
summary(result3)
對比兩個估計的結果:(注意P值的變化)
穩健估計的:
Estimate Std.Error t value Pr(>|t|)
(Intercept) -2.054967 8.496552 -0.2419 0.808951
log(income) 1.891021 0.642539 2.9430 0.003344 **
cigpric -0.004685 0.099792 -0.0469 0.962567
educ -0.377021 0.169621 -2.2227 0.026513 *
age -0.045268 0.023225 -1.9491 0.051633.
restaurn -2.945906 1.042941 -2.8246 0.004851 **
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05‘.’ 0.1 ‘ ’ 1
直接回歸估計的:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.054967 8.778358 -0.234 0.81497
log(income) 1.891021 0.712092 2.656 0.00807 **
cigpric -0.004685 0.102518 -0.046 0.96356
educ -0.377021 0.167975 -2.244 0.02507 *
age -0.045268 0.028682 -1.578 0.11490
restaurn -2.945906 1.127952 -2.612 0.00918 **
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05‘.’ 0.1 ‘ ’ 1
也可以看到協方差陣的變化:
vcovHAC(result3)
vcov(result3)
三���、線性性的假設檢驗
car包中提供了一個函數可以自動的進行線性假設檢驗����。根據我們對模型的設定��,它既可以用一般的方法或調整后的協方差矩陣進行F或Wald檢驗����。例如�����,如果我們有一個包括常數項的五個參數的模型�,并且我們的零假設如下
H0:β0 =0����, β3+β4=0
我們可以用如下的命令加以實現
unrestricted<-lm(y~x1+x2+x3+x4)
rhs<-c(0,1)
hm<-rbind<-(c(1,0,0,0,0),c(0,0,1,1,0))
linear.hypothesis(unrestricted,hm,rhs)
如果unrestricted是由lm得到的�����,默認狀態下將會進行F檢驗��。如果是由glm得到的����,取而代之的將是Kai方檢驗����。檢驗的類型可以通過type進行修改���。
同樣����,如果我們想利用異方差或自相關穩健標準誤進行檢驗����,我們既可以通過設定white.adjust=TRUE來使用white標準誤���,也可以利用vcov計算我們自己的協方差矩陣����。例如����,如果我們想使用上述的Newey-West修正協方差矩陣����,我們可以進行如下的設定:
linear.hypothesis(unrestricted,hm, rhs, vcov=NeweyWest(unrestricted))(注2)
四�����、附注
注1:Newey-West
的自相關異方差一致性估計:當異方差的形式未知的時候���,加權最小二乘法(WLS)得到的估計結果雖然仍具有一致性�����,但是不在有效��。為了解決這一問題���,White(1980)提出了Heteroskedasticity
Consistent Covariances 方法使存在異方差時能夠對協方差矩陣進行一致性估計����,而無須知道異方差的形式�����,但是 White
提出的方法假定序列的殘差是不存在自相關的����,為了解決這一問題���,Newey-West(1987)提出了一個更為一般的估計量�����,使存在異方差和自相關是仍然能對協方差矩陣進行一致性估計�����。
注2����、設定white.adjust=TRUE將會通過提高white估計量的精度來修正異方差�;如果要使用經典的white估計量�����,我們可以設定white.adjust="hc0"
注3�、對于異方差檢驗的另一函數
調用library(lmtest)
Goldfeld-Quandt Test,GQ檢驗的思想是先把時間序列數據按順序排列����,然后截去一定數量的中間段數據�,留下的數據就自然分成兩組���,對這兩組數據各自回歸獲得各組的殘差平方和����,把兩個殘差平方和除以各自的自由度�����,然后再相除�����,就獲得了GQ統計量��,這是一個F統計量��。GQ檢驗的零假設為回歸不存在異方差�����;備折假設則為存在異方差����。
R語言中��,使用函數gqtest()進行檢驗�����。
gqtest(formula, point=0.5, fraction=0, alternative=c("greater", "two.sided", order.by=NULL, data=list())
GQ檢驗的思想是對數據回歸得到殘差序列,然后把殘差作為被解釋變量,原方程各解釋變量作為解釋變量做回歸,得到bp的統計量
注4���、異方差的手動算法
## packages and data
library("AER")
data("CigarettesB")
## regression
cig_lm2 < - lm(packs ~ price + income, data = CigarettesB)
## auxiliary regression
aux <- residuals(cig_lm2)^2
aux_lm <- lm(aux ~ income * price + I(income^2) + I(price^2),
data = CigarettesB)
## test statistic
nrow(CigarettesB) * summary(aux_lm)$r.squared
pchisq( nrow(CigarettesB) * summary(aux_lm)$r.squared,df=5,lower.tail=F)
[1] 0.007896581
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
