機器學習中的各種相似性�、距離度量
本文主要關注點在于各個距離��、相似度之間的優缺點����,及使用時候的注意事項���。
1. 閔可夫斯基距離
基本認識
該距離最常用的 p 是 2 和 1, 前者是歐幾里得距離(Euclidean distance)�,后者是曼哈頓距離(Manhattan distance)����。假設在曼哈頓街區乘坐出租車從 P 點到 Q 點����,白色表示高樓大廈��,灰色表示街道:
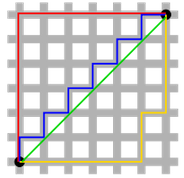
綠色的斜線表示歐幾里得距離��,在現實中是不可能的�����。其他三條折線表示了曼哈頓距離��,這三條折線的長度是相等的��。
當 p 趨近于無窮大時�,閔可夫斯基距離轉化成切比雪夫距離(Chebyshev distance)
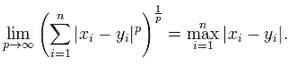
我們知道平面上到原點歐幾里得距離(p = 2)為 1 的點所組成的形狀是一個圓�,當 p 取其他數值的時候呢�����?

注意����,當 p < 1 時���,閔可夫斯基距離不再符合三角形法則�,舉個例子:當 p < 1, (0,0) 到 (1,1) 的距離等于(1+1)1/p>2, 而 (0,1) 到這兩個點的距離都是 1���。
優缺點及注意事項
閔可夫斯基距離比較直觀���,但是它與數據的分布無關�,具有一定的局限性���,如果 x 方向的幅值遠遠大于 y 方向的值�����,這個距離公式就會過度放大 x 維度的作用�。所以�,在計算距離之前���,我們可能還需要對數據進行 z-transform 處理���,即減去均值�,除以標準差
可以看到���,上述處理開始體現數據的統計特性了��。這種方法在假設數據各個維度不相關的情況下利用數據分布的特性計算出不同的距離�。如果維度相互之間數據相關(例如:身高較高的信息很有可能會帶來體重較重的信息��,因為兩者是有關聯的)�����,這時候就要用到馬氏距離(Mahalanobis
distance)了�����。
2. 馬氏距離
考慮下面這張圖����,橢圓表示等高線����,從歐幾里得的距離來算����,綠黑距離大于紅黑距離�����,但是從馬氏距離�,結果恰好相反:
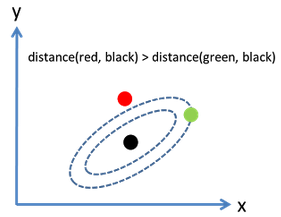
馬氏距離實際上是利用 Cholesky transformation 來消除不同維度之間的相關性和尺度不同的性質����。假設樣本點(列向量)之間的協方差對稱矩陣是Σ,
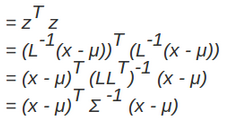
下圖藍色表示原樣本點的分布�,兩顆紅星坐標分別是(3, 3)��,(2, -2):
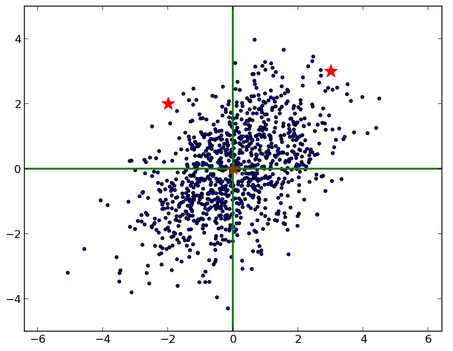
由于 x����, y 方向的尺度不同�,不能單純用歐幾里得的方法測量它們到原點的距離�����。并且�����,由于 x 和 y
是相關的(大致可以看出斜向右上)��,也不能簡單地在 x 和 y 方向上分別減去均值����,除以標準差��。最恰當的方法是對原始數據進行 Cholesky
變換�,即求馬氏距離(可以看到�,右邊的紅星離原點較近):
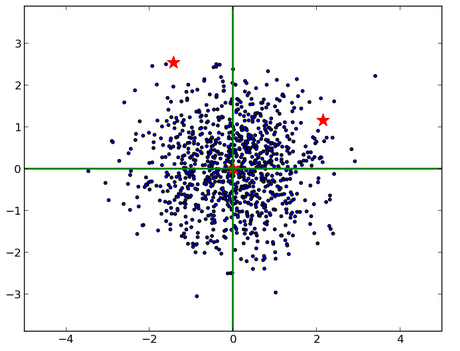
將上面兩個圖的繪制代碼和求馬氏距離的代碼貼在這里�,以備以后查閱:
# -*- coding=utf-8 -*-
# code related at: http://www.cnblogs.com/daniel-D/
import numpy as np
import pylab as pl
import scipy.spatial.distance as dist
def plotSamples(x, y, z=None):
stars = np.matrix([[3., -2., 0.], [3., 2., 0.]])
if z is not None:
x, y = z * np.matrix([x, y])
stars = z * stars
pl.scatter(x, y, s=10)
# 畫 gaussian 隨機點
pl.scatter(np.array(stars[0]), np.array(stars[1]), s=200, marker='*', color='r')
# 畫三個指定點
pl.axhline(linewidth=2, color='g')
# 畫 x 軸
pl.axvline(linewidth=2, color='g')
# 畫 y 軸
pl.axis('equal')
pl.axis([-5, 5, -5, 5])
pl.show()
# 產生高斯分布的隨機點
mean = [0, 0]
# 平均值
cov = [[2, 1], [1, 2]]
# 協方差
x, y = np.random.multivariate_normal(mean, cov, 1000).T
plotSamples(x, y)
covMat = np.matrix(np.cov(x, y))
# 求 x 與 y 的協方差矩陣
Z = np.linalg.cholesky(covMat).I
# 仿射矩陣
plotSamples(x, y, Z)
# 求馬氏距離
print '\n到原點的馬氏距離分別是:'
print dist.mahalanobis([0,0], [3,3], covMat.I), dist.mahalanobis([0,0], [-2,2], covMat.I)
# 求變換后的歐幾里得距離
dots = (Z * np.matrix([[3, -2, 0], [3, 2, 0]])).T
print '\n變換后到原點的歐幾里得距離分別是:'
print dist.minkowski([0, 0], np.array(dots[0]), 2), dist.minkowski([0, 0], np.array(dots[1]), 2)
馬氏距離的變換和 PCA 分解的白化處理頗 有異曲同工之妙����,不同之處在于:就二維來看�����,PCA 是將數據主成分旋轉到 x
軸(正交矩陣的酉變換)���,再在尺度上縮放(對角矩陣)����,實現尺度相同�����。而馬氏距離的 L逆矩陣是一個下三角���,先在 x 和 y 方向進行縮放��,再在 y
方向進行錯切(想象矩形變平行四邊形)����,總體來說是一個沒有旋轉的仿射變換�。
3. 向量內積���、余弦相似度和皮爾遜相關系數
向量內積是線性代數里最為常見的計算����,實際上它還是一種有效并且直觀的相似性測量手段�。
直觀的解釋是:如果 x 高的地方 y 也比較高�����, x 低的地方 y 也比較低����,那么整體的內積是偏大的����,也就是說 x 和 y 是相似的����。
舉個例子���,在一段長的序列信號 A 中尋找哪一段與短序列信號 a 最匹配�,只需要將 a 從
A信號開頭逐個向后平移����,每次平移做一次內積��,內積最大的相似度最大���。信號處理中 DFT 和
DCT也是基于這種內積運算計算出不同頻域內的信號組分(DFT 和 DCT是正交標準基�,也可以看做投影)���。向量和信號都是離散值����,如果是連續的函數值����,比如求區間[-1, 1]兩個函數之間的相似度�,同樣也可以得到(系數)組分���,這種方法可以應用于多項式逼近連續函數���,也可以用到連續函數逼近離散樣本點.
向量內積的結果是沒有界限的���,一種解決辦法是除以長度之后再求內積����,這就是應用十分廣泛的余弦相似度(Cosine similarity)�����。
余弦相似度與向量的幅值無關���,只與向量的方向相關��,在文檔相似度(TF-IDF)和圖片相似性(histogram)計算上都有它的身影�����。需要注意一點的是��,余弦相似度受到向量的平移影響�����,上式如果將 x 平移到 x+1, 余弦值就會改變���。怎樣才能實現平移不變性�����?這就是下面要說的皮爾遜相關系數(Pearson correlation)��,有時候也直接叫相關系數����。
皮爾遜相關系數具有平移不變性和尺度不變性�,計算出了兩個向量(維度)的相關性�����。不過��,一般我們在談論相關系數的時候�����,將 x 與 y 對應位置的兩個數值看作一個樣本點���,皮爾遜系數用來表示這些樣本點分布的相關性��。
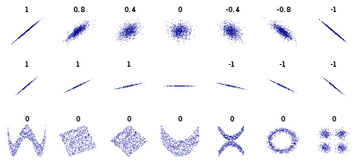
由于皮爾遜系數具有的良好性質�,在各個領域都應用廣泛��,例如���,在推薦系統根據為某一用戶查找喜好相似的用戶,進而提供推薦���,優點是可以不受每個用戶評分標準不同和觀看影片數量不一樣的影響��。
4. 分類數據點間的距離
漢明距離(Hamming distance)和杰卡德相似系數(Jaccard similarity)����,具體可以參考我的上一篇博客《【Matlab開發】matlab中bar繪圖設置與各種距離度量》�。
5. 序列之間的距離
【轉自《漫談機器學習中的距離和相似性度量方法》】上一小節我們知道�����,漢明距離可以度量兩個長度相同的字符串之間的相似度����,如果要比較兩個不同長度的字符串���,不僅要進行替換�,而且要進行插入與刪除的運算����,在這種場合下�����,通常使用更加復雜的編輯距離(Edit
distance, Levenshtein distance)等算法�。編輯距離是指兩個字串之間�,由一個轉成另一個所需的最少編輯操作次數�����。許可的編輯操作包括將一個字符替換成另一個字符����,插入一 個字符�,刪除一個字符�����。編輯距離求的是最少編輯次數�,這是一個動態規劃的問題�,有興趣的同學可以自己研究研究�����。
時間序列是序列之間距離的另外一個例子�����。DTW 距離(Dynamic Time
Warp)是序列信號在時間或者速度上不匹配的時候一種衡量相似度的方法���。神馬意思�����?舉個例子���,兩份原本一樣聲音樣本A�、B都說了“你好”��,A在時間上發生了扭曲����,“你”這個音延長了幾秒��。最后A:“你~~~好”����,B:“你好”���。DTW正是這樣一種可以用來匹配A��、B之間的最短距離的算法��。
DTW 距離在保持信號先后順序的限制下對時間信號進行“膨脹”或者“收縮”���,找到最優的匹配�����,與編輯距離相似��,這其實也是一個動態規劃的問題:
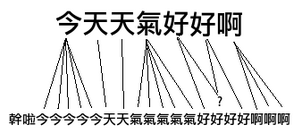
實現代碼:��、
#!/usr/bin/python2
# -*- coding:UTF-8 -*-
# code related at: http://blog.mckelv.in/articles/1453.html
import sys
distance = lambda a,b : 0 if a==b else 1
def dtw(sa,sb):
'''
>>>dtw(u"干啦今今今今今天天氣氣氣氣氣好好好好啊啊啊", u"今天天氣好好啊")
2
'''
MAX_COST = 1<<32
#初始化一個len(sb) 行(i)�,len(sa)列(j)的二維矩陣
len_sa = len(sa)
len_sb = len(sb)
# BUG:這樣是錯誤的(淺拷貝): dtw_array = [[MAX_COST]*len(sa)]*len(sb)
dtw_array = [[MAX_COST for i in range(len_sa)] for j in range(len_sb)]
dtw_array[0][0] = distance(sa[0],sb[0])
for i in xrange(0, len_sb):
for j in xrange(0, len_sa):
if i+j==0:
continue
nb = []
if i > 0: nb.append(dtw_array[i-1][j])
if j > 0: nb.append(dtw_array[i][j-1])
if i > 0 and j > 0: nb.append(dtw_array[i-1][j-1])
min_route = min(nb)
cost = distance(sa[j],sb[i])
dtw_array[i][j] = cost + min_route
return dtw_array[len_sb-1][len_sa-1]
def main(argv):
s1 = u'干啦今今今今今天天氣氣氣氣氣好好好好啊啊啊'
s2 = u'今天天氣好好啊'
d = dtw(s1, s2)
print d
return 0
if __name__ == '__main__':
sys.exit(main(sys.argv))
由于上面這個基本上沒有用過�����,這里僅僅轉載過來����,備用而已��。并不加以闡釋理解����。
6. 概率分布之間的距離
概率分布之間的距離度量是一個非常重要的課題���,這個回頭肯定能遇到����,等到時做一個專題來總結好了���,這里不再敘述��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
