SPSS:數據的加權
在SPSS軟件中�,Data
View(數據視圖)在默認情況下每一行就是一條記錄��,通常情況下我們也是這樣錄入數據的�。但是�,在有些情況下我們得到的數據可能是已經初步匯總過的�,如下面所說的情況��,如果有168個相同的觀察數據�����,每一行就是一個記錄���,則需要輸入168行�,這樣做非常麻煩���。SPSS當然考慮了這個問題���,并且比較容易地解決了這個問題����。具體辦法是使用頻數格式錄入數據��,即相同取值的觀測只錄入一次��,另加一個頻數變量記錄該數值共出現了多少次�����。這樣就需要在分析前先用Data(數據)主菜單中的Weight
Cases(加權個案)過程將數據指定為該種格式��。然后再進行分析����。數據加權的方法如下:
加權個案案例:為了研究抽煙與肺癌的關系�,隨機采訪了45個正常人與55個肺癌患者����,詢問記錄了他們是否抽煙�,數據記錄結果詳見下表:
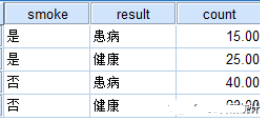
對數據進行加權操作的方法如下:
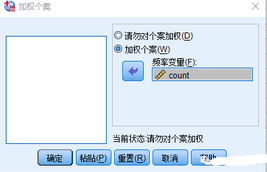
依次點擊菜單“數據——加權個案”�,其界面如下圖所示����。點擊選中“加權個案”單選框�,將左側變量列表中“人數”變量選中進入“頻率變量”選框作為加權變量���。點擊確認����。
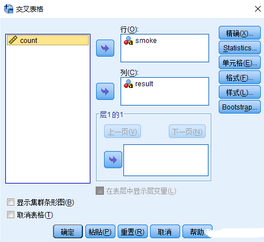
加權后的數據表面上看沒什么變化����,但在旗分析過程中會產生差異���。以下以列聯表交叉表分析為例�����,解釋加權變量的應用���。
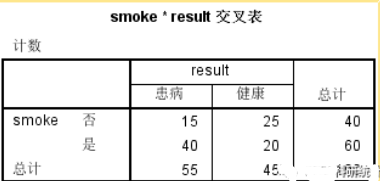
在數據沒有加權后得出的交叉表如下表�,可以看出SPSS只按照實際的行數進行了統計�����,不能真實的反應實際情況�。
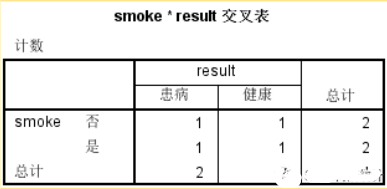
而加權之后所得出的交叉表清晰的反映出了是否吸煙所對應的患病與健康的人數��,可以清晰的發現吸煙的患者要明顯高于未吸煙的患者���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
