大數據時代:傳統BI還能走多遠
從事BI多年��,經歷了經營分析系統的大建設��,大發展時期��,也有幸處在大數據與傳統BI系統的交替之際���,因此特別來談談���,傳統BI還能走多遠�����?
技術為業務服務�,因此這里不談技術�����,更多從使用者的角度去闡述原因�,理了八個方面�,每個方面都是筆者親歷�����,當然任何窮舉法都無法證明絕對正確�,但希望能引起思考��。
1�、資源申請-從月到日���,不可同日耳語
自從企業有了大數據MPP��、HADOOP�、流處理三個資源池���,租戶生效基本都是所見即所得�����。公司甚至為了申請方便���,搞了資源套餐���,我們申請資源叫點套餐�,這種資源申請模式為對外靈活開放數據提供了基本保障�����,在半年時間內��,內外部租戶已經開出了100多個(以前可能叫數據集市)�,現在回想起來����,如果沒有這個能力��,公司的對外變現基本不可能�����。
無論是阿里云還是AWS����,都是這個套路�����,但為什么企業要自己做���,因為較大的企業本身內部就是個巨大的市場���,有各類的應用要求���,從數據�����、安全��、接口�、技術等各個方面講���,都不適合放到外部平臺�。
傳統BI的小型機階段�����,沒有資源池概念�,資源申報按硬件臺數算�,需要提前申請預算��,即使硬件到位�����,集成時間也過于漫長�,記得以前為11個地市規劃11個數據集市���,采用四臺570劃分12個分區����,搞了1個多月��,效率不可同日而語�。
大數據系統在資源粒度�����、申請速度���、資源動態擴展等各個方面都完爆傳統BI�����,在業務快速部署上具有無法比擬的優勢����,為業務創新奠定了很好的基礎�����。如果你做過DB2的項目集成啥的�,每一次都涉及規劃��、劃盤�、分區�、安裝等等����,就知道啥叫等待�����。
2�����、數據采集-多樣性才能創造更多應用場景
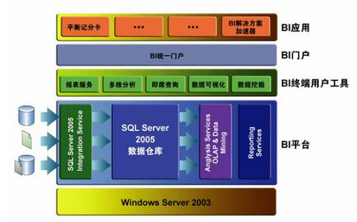
傳統ETL的基本套路都是從源數據庫導出成文本�,然后通過客戶端工具導入到目的數據庫��,導出用EXPORT�����,傳輸用FTP�,導入用IMPORT��,當然�����,同種類型的數據庫可能用DBLINK等這種快捷方式��,程序中采用ODBC啥的連接數據庫來進行操作�����。很多公司專門開發了一些多庫之間互導數據的工具����,當然一般企業級的平臺不用����,可擴展性����、靈活性太差���。傳統ETL的技術非常適應以天或月為分析周期的靜態應用要求�。
我想大多數企業����,BI的數據分析現在周期基本還是天��,筆者做了10年BI�����,記得企業很長一段時間�����,是以月為單位ETL數據的��,當然���,從業務的角度講��,夠用即可��,有人會問�����,數據的周期減少到小時���、分鐘�����、秒以致實時����,到底有多大現實意義?但真的業務上不需要更短周期的分析嗎?是因為大家BI分析的套路習慣使然還是能力不夠使然?
從取數的角度講���,業務人員永遠希望你取得數據越快越及時越好���,我們原來只出月報����,后來性能上去了����,復雜的日報也能出了����,日報變成了標配��,日報之后呢���,實時是否應該成為未來的標配?
從應用的角度講����,企業除了一堆運營指標報表����,一般有營銷和風控兩個角度有數據的現實需求�����,實時營銷顯然比靜態營銷效果更好一點�,BAT如果不搞實時營銷基本就沒法活���,實時風控顯然比離線風控效果更好有一點�,比如反欺詐系統��,如果不是實時的監聽�,如何在詐騙的事中介入?
從趨勢的角度講����,如果你認同未來的世界是滿足個性化的世界�����,那么��,只有實時的數據才能蘊含更多的信息�,才能給你更為個性化的服務����,你會想到太多的場景需要實時化采集�。
即使你沒有以上提的任何需求����,但技術和業務永遠是互動的��,你具備了按小時提供的能力���,人家就會創造按小時的業務場景�,你具備了實時的提供能力���,人家就會創造實時的業務場景�。誰是蛋誰是雞說不清楚�����,但如果你想服務的更好����,就應該在技術層面更前瞻性一點�。
但傳統BI能支撐嗎?傳統企業的BI不實時����,本質不是沒有需求��,也許是能力不夠所致�,我記得以前CRM上線要搞個實時放號指標監控�,也是蠻困難的事情���,以前出賬只有月報啊���,現在����,沒有日報����,還能活?
我記得很多年前第一份日賬報表是IT人員自己提的���,因為能力到了��。 那未來10年呢?
ETL是傳統數據倉庫中的一個概念��,我覺得該升級了����,多樣化的采集方式是王道�,這是大勢所趨�����,有三樣東西是最重要的����,一個是采集方式的百花齊放�����,即消息�、數據流���、爬蟲�、文件�����、日志增量都能支持�����,二是數據的流動不是單向的��,不僅僅是E����,而且是X,即交換����,這樣就極大衍生了ETL的內涵���,三是數據采集的分布式����,可以并行動態擴展����,ETL的讀寫問題能較好解決����。這些恰是傳統BI做不到的���。
3���、計算性能-性價比是王道���,更迭速度比想象的快
DB2����、Teradata在數據倉庫領域一直占據著巨大的份額���,我們用GBASE+HADOOP花了半年時間把2臺P780替換掉了�,綜合性能可以說是原來的1.5倍����,但投資只有幾分之一�,雖然前期涉及一些調優�,對于代碼也有更高的要求��,但性價比非常高�����,關鍵是能夠多租戶動態擴展�����,容災能力也超DB2���。記得以前DB2一旦節點出現問題�����,雖然也能切換����,但性能往往下降一半����,極大影響業務�。
傳統數據倉庫�����,對于不同的數據處理方式往往是一視同仁的�����,但事實上�����,不同數據處理階段�����,對于數據處理的要求存在結構性的不同�,一些簡單的轉化和匯總�,在庫外方式處理比庫內處理合算���,但傳統BI習慣于把數據全部導入到數據倉庫中做��,浪費了珍貴的小型機系統資源�����,性價比很低����。因此���,當前MPP+HADOOP混搭型數據倉庫漸成趨勢�,HADOOP擅長海量簡單的批量處理����,MPP擅長數據關聯分析�����,比如eBAY,中國移動等都采用了類似的方案����。
從綜合的角度講�,DB2等數據倉庫當然有它的優勢�,比如引以為豪的穩定����,但這些技術過于依賴國外�,感覺運維能力每況愈下��,關鍵問題的解決越來越力不從心���,穩定這個詞也要打上大大的問號�,不知道其他企業感覺如何�����。要相信筆者不是打國產GBASE廣告��,坑很多����,但值得擁有��。
4���、報表系統-審美疲勞不可避免�,個性化是趨勢
用過很多商業化的報表系統���,比如BRIO�����、BO���、BIEE等等��,系統都提供了較好的可視化界面��,對于輕量級數據的展現也不錯�����,但我覺得這個對于大型企業來講沒有吸引力�。
一是可替代性太強�,現在開源組件太多了��,功能也雷同�����,為什么要用標準化被捆綁的東西����,對于具有一定開發能力的公司�����,似乎無此必要����。
二是開源性太差�����,企業有大量個性化的要求����,比如安全控制等等����,但這些產品的開放性較差�����,很多時候滿足不了要求����。
三是不靈活�,再通用����,能做得過EXCEL嗎�,不要奢望從一個報表系統上能直接摘取一個報表粘貼到一個報告上���,總是要二次加工�,既然這樣�����,還不如數據直接灌入EXCEL簡單����。
四是速度太慢��,當前的報表已經不是傳統BI意義的報表�����,因為維度和粒度要求很細��,結果記錄數過億的也不在少數����,比如我們的指標庫一年記錄是百億條��,傳統BI報表根本無法支撐�����,樣子好看是暫時的�,業務人員最關注的始終是報表的速度�����。
當然��,對于小企業可能仍然具有一定吸引力����,但這個開放的時代����,需求和新技術層出不窮�,這類標準化的產品能趕上變化嗎?如果你希望HBASE跟BIEE結合����,怎么辦?是等著廠家慢慢推出版本�,還是干脆自己干?
5�、多維分析-適應性較差��,定制化才是方向
用過一些商業化的多維分析系統��,也叫OLAP吧�����,比如IBM的ESSBASE�����。OLAP是幾十年前老外提出的概念����,通過各維度分析快速得到所需的結果���,但這個OLAP到底有多大的實用價值?
OLAP產品總是想通過通用化的手段解決一個專業性分析問題����,從誕生開始就有硬傷�,因為分析變化無常�,你是希望自己在后臺隨心所欲用SQL馳騁江湖還是面對一個呆板的界面進行固定的復雜的多維操作?筆者作為技術人員不喜歡用它�����,但業務人員也不喜歡用它�����,操作門檻偏高����。
在開放性上����,傳統OLAP的后臺引擎仍然是傳統數據庫�����,顯然不支持一些海量的大數據系統;打CUBE是個設計活�����,非常耗時����,每次更新數據要重打CUBE���,總是讓筆者抓狂�����,不知道現在有啥改進;千萬級數據量��、10個維度估計也是它的性能極限了吧;最后����,以前打的CUBE真的能解決你當前的分析問題?
淘寶的數據魔方一定程度說明了OLAP的發展方向���,針對特定的業務問題�����,提供特定的多維數據解決方案�,我們需要提供給用戶的是一個在體驗���、性能���、速度上都OK的專業化系統�。
業務導向+定制化的后臺數據解決方案(比如各類大數據組件)是未來OLAP的方向����。
6�、挖掘平臺-從樣本到全量�,需要全面升級裝備
SAS��、SPSS都是傳統數據挖掘的利器��,但他們大部分時候只能在PC上進行抽樣分析����,顯然���,大數據的全量分析是其無法承擔的�����,比如社交網絡��、時間序列等等����。
傳統數據挖掘平臺似乎沒有拿得出手的東西����,以前IBM DB2有個DATA
MINER���,后來放棄了�,Teradata可以�����,有自己的算法庫�,但面對海量數據其計算能力顯然也力不從心��,跟大數據的SPARK等差了一個檔次�����,我們接觸的很多合作伙伴�����,大多開始將SPARK做為大規模并行算法的標準套件了���。
即使如邏輯回歸�、決策樹等傳統算法�, SPARK顯然能基于更多的樣本數據甚至全量數據進行訓練�����,比SPSS�,SAS僅能在PC上搗鼓要好很多�����。
傳統BI的SAS和SPSS仍然有效���,但基于大數據平臺的全量算法也應該納入BI的視野�����。
7���、數據管理-不與時俱進����,就是一個死
數據管理類的系統很難建�����,因為沒有你生產系統也不會死���,有了也很難評估價值�,且運維的成本過高���,一不小心就陷入了到底誰服務誰的問題����。
最早接觸元數據管理系統是在2006-2007年吧�����,那個時候搞元數據還是蠻有前瞻性的��,搞了很多年���,卻明白一個道理���,如果你把元數據當成一個外掛��,這個元數據系統沒有成功的可能�����,搞事后補錄這種看似可以的方法����,無論制度如何完善���,系統解析能力如何強大����,也最終會走向源系統和元數據兩張皮的現象���,失去應有的價值�。
只要不解決這個問題����,我嚴重懷疑傳統BI元數據管理真正成功的可能�����。大數據時代��,隨著數據量����、數據類型�、技術組件等的不斷豐富����,搞事后元數據更是不可能的事情�。
新時代的數據管理系統長啥樣?一提倡生產即管理�,也就是說���,元數據管理的規則是通過系統化的方式固話在系統生產流程中�,我們提倡無文檔的數據開發���,因為文檔就是元數據���,所有關于元數據的要求已經梳理成規則并成為數據開發環境的一部分�����。比如你建個表�����,在給你可視化開發界面時����,關于表的定義已經強制要求在線輸入必須的說明����,你寫的代碼也被規則化����,以便于元數據自動解析�,成為數據質量監控的一部分��。
二要能評估數據效益����,通過一的手段����,數據跟應用可以形成關聯�����,應用的價值可以傳導為數據的價值����,為數據的價值管理提供標準�,做數據最郁悶的是����,我創造了一個模型��,但不知道這個模型的價值�,自己的工作變得可有可無����,我也不知道如何開展優化��,幾十萬張表爛在哪里���,不敢去清理它們����。
三是跨平臺管理�,這么多的技術組件��,比如HADOOP��、MPP�����、流處理等等���,你的管理系統要能無縫銜接和透明訪問�����,每新增一類組件����,都要能及時接入管理系統����,否則�����,接入一個�����,該組件上的數據就成為游離之外的數據����,數據管理無從談起��。
數據管理��,最怕半拉子工程��,要系統化�,就要做徹底�����,否則����,還不如文檔記錄算了��,沒什么多大的區別����。
8�、審視定位-BI干BI的事情�,各司其職
傳統BI����,做報表取數的太多����,研究平臺和算法的太少�,重復勞動太多���,創造性工作太少��,隨著業務的發展����,BI的人逐漸老去���,但系統中留下的東西不多����,非常遺憾����。
大數據時代到來���,這種情況需要改變�,該是重新審視自己的定位的時候了�����,報表取數的確是BI的基礎工作���,但從事BI的人不應該總是扮演拉磨的驢子的角色����,應該是最終掌舵的那個人��,我可以拉一會���,但我需要研究如何拉得更快�����,最后讓機器來代替我拉���,或者讓拉磨的工作非常愉快����,需要的人可以自己來拉��。
BI的人有太多需要創新和學習的東西��,如果有太多取數��,搞個取數機器人�,如果太多報表���,搞個指標體系�����,如果太多需求����,搞個自助工具或給個租戶環境���,誘惑業務人員自己來做��,需求永無止境�����,欲望永不滿足���,靠人肉填坑�,永遠填不滿的���,需要BI人的引導�,授人予魚��,不如授人予漁��。
傳統BI還能走多遠�����?提了八點��,對于處于不同階段的人�,可能也有不同的理解��,當然僅為一家之言��,希望有所啟示�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
