缺失數據處理-插值法
在數據挖掘中��,原始海量的數據中存在著大量不完整��、不一致��、有異常�、偏離點的數據����。這些問題數據輕則影響數據挖掘執行效率���,重則影響執行結果��。因此數據預處理工作必不可少��,而其中常見工作的就是數據集的缺失值處理����。
數據缺失值處理可分兩類�����。一類是刪除缺失數據�����,一類是進行數據插補�����。前者比較簡單粗暴����,但是這種方法最大的局限就是它是以減少歷史數據來換取數據的完備�,會造成資源的大量浪費�����,尤其在數據集本身就少的情況下�,刪除記錄可能會直接影響分析結果的客觀性和準確性
本文介紹數據常用的插補方法���。對拉格朗日插值法和滑動平均窗口法進行重點介紹和實現����。
介紹
常用的插值方法如下:
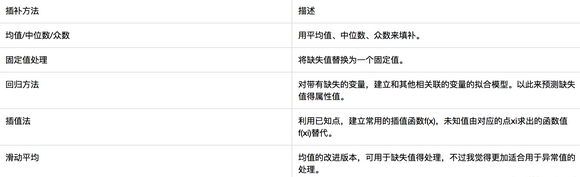
這里只對插值法和窗口滑動平均進行介紹�。
滑動平均窗口法
概念:
??一個列表a 中的第 i 個位置數據為缺失數據����,則取前后 window 個數據的平均值���,作為插補數據����。
示例:
a = [3,4,5,6,None,4,5,2,5] ���、 window = 3
則 None位置的數據為:(4+5+6+4+5+2)/6 = 2.67
拉格朗日插值法
概念
??根據數學概念可知����,對于平面上已知的n個點(無兩點在一條直線上)可以找到一個n-1次的多項式���,使此多項式通過這n個點��。
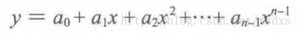
??因此我們需先求得多項式函數L(x)����,然后將缺失值對應的點x帶入插值多項式得到缺失值的近似值L(x)�。多項式函數L(x)的求法如下:

實現
代碼
# coding:utf-8
# 拉格朗日插值代碼
import pandas as pd # 導入數據分析庫Pandas
from scipy.interpolate import lagrange # 導入拉格朗日插值函數
# 構建原始數據
data = pd.DataFrame([
["2015/3/1", 59],
["2015/2/28", 2618.2],
["2015/2/27", 2608.4],
["2015/2/26", 2651.9],
["2015/2/25", 3442.1],
["2015/2/24", 3393.1],
["2015/2/23", 3136.6],
["2015/2/22", 3744.1],
["2015/2/21", ],
["2015/2/20", 4060.3],
["2015/2/19", 3614.7],
["2015/2/18", 3295.5],
["2015/2/16", 2332.1],
["2015/2/15", 2699.3],
["2015/2/14", ],
["2015/2/13", 3036.8],
["2015/2/12", 1865],
["2015/2/11", 3014.3],
["2015/2/10", 2742.8],
["2015/2/9", 2173.5],
["2015/2/8", 3161.8],
["2015/2/7", 3023.8],
["2015/2/6", 2998.1],
], columns=[u'日期', u'銷量'])
# 設置異常值,把銷量大于5000和銷量小于400的異常值替換為None
data[u'銷量'][(data[u'銷量'] < 400) | (data[u'銷量'] > 5000)] = None
# 把要處理的數據取出來,pandas中dataframe格式單獨取出一列就是series數據格式
tmp_data_1 = data[u'銷量'].copy()
tmp_data_2 = data[u'銷量'].copy()
def ployinterp_column(series, pos, window=5):
"""
:param series: 列向量
:param pos: 被插值的位置
:param window: 為取前后的數據個數
:return:
"""
y = series[list(range(pos - window, pos)) + list(range(pos + 1, pos + 1 + window))] # 取數
y = y[y.notnull()] # 剔除空值
return lagrange(y.index, list(y))(pos) # 插值并返回插值結果
def sma_mothod(series, pos, window=5):
"""
:param series: 列向量
:param pos: 被插值的位置
:param window: 為取前后的數據個數
:return:
"""
y = series[list(range(pos - window, pos)) + list(range(pos + 1, pos + 1 + window))] # 取數
y = y[y.notnull()]
return reduce(lambda a, b: a + b, y) / len(y)
for j in range(len(tmp_data_1)):
if (tmp_data_1.isnull())[j]: # 如果為空即插值��。
tmp_data_1[j] = ployinterp_column(tmp_data_1, j)
print j, data.loc[j, u'日期'], tmp_data_1[j]
print
for j in range(len(tmp_data_2)):
if (tmp_data_2.isnull())[j]: # 如果為空即插值��。
tmp_data_2[j] = sma_mothod(tmp_data_2, j)
print j, data.loc[j, u'日期'], tmp_data_2[j]
輸出
0 2015/3/1 -291.4
8 2015/2/21 4275.25476248
14 2015/2/14 3680.66999227
0 2015/3/1 2942.74
8 2015/2/21 3236.97
14 2015/2/14 2883.43
分析
對比之下�����,滑動窗口方法的輸出都還比較合理����。但顯而易見的是拉格朗日插值對0位置的數據處理的很不好�����,插值為
-291.4����。擬合點的數據格式為(x,y)���,具體數據:(1, 2618.2), (2, 2608.4),(3, 2651.9),(4,
3442.1), (5, 3393.1)����。我們把拉格朗日多項式打印出來:
??L(x) = -94.97 x^4 + 1065 x^3 - 3991 x^2 + 5930 x^1 - 291.4
??把 x= 0 帶入得到 L(x)���,就得到了 -291.4����。這里x=0就是L(x)的截距�。直觀感覺就不太合理���,猜測就是拉格朗日插值法對邊緣數據敏感(即插值需要左右兩邊數據提供信息���,在缺失左邊數據信息情況下�����,得到的結果就不太合理)����,日后求證�!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
