如何成為一名數據分析師:數據的初步認知
對所有從事數據相關工作的人而言����,都有一個老生常談的問題: 數據認知 !畢竟在真正開始分析�����、BI
報表開發或者建模前���,對數據進行一定的審查和認知是必須的�。今天��,就在此和大家一同探討下數據的初步認知��。在本文的講解中��,會將數據的初步認知劃分為三大步驟:
數據質量檢查����、數據類型認知���、指標值統計 ����。
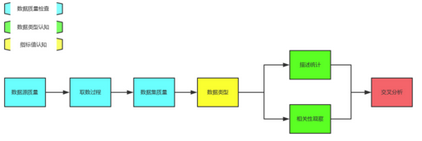
一�、數據質量檢查
1) 關注不同數據源在統計質量上的差異
不同的數據來源���,因統計����、管控��、可共享程度等原因在數據粒度和數據質量的保障上都有天壤之別�����。根據數據來源的渠道主要可將它劃分為:內部數據和外部數據����,下面逐個介紹它們之間的特點和差異���。
1. 內部數據源
業務數據:主要指后端研發主動存儲的業務數據����,一般是對公司運營非常核心的數據�����,如訂單數據���、用戶信息等��。這類數據的準確性一般是最高的�,因為它往往關系到公司產品能否正常運轉����,統計的正確性也就至關重要;
埋點數據:通過埋點技術采集的用戶訪問數據���,不論是自建埋點還是采用第三方埋點工具�,因為埋點實施�、統計上傳機制等����,都會造成埋點數據的準確性遠不如業務數據;
數據倉庫的數據:數據倉庫數據它是由生產庫數據經過一輪或者多輪次的數據轉換����,中間可能發生的異常情況比生產庫的數據更多����。諸如:無人維護��、轉換邏輯與理解不一致等�。
對于業務數據����、埋點數據��、數據倉庫數據三種類型的數據源我們檢查的側重點有所不同:
業務數據:業務數據的復雜度主要在于字段含義�、表之間關聯關系以及字段與業務的實際對應關系���,主要檢查的也是這三點;
埋點數據:埋點數據主要需要檢查埋點是否與你所期望的業務事件匹配�,包括埋點采集的是頁面訪問還是按鈕點擊�����、埋點采集時機等;
數據倉庫數據:主要了解其中業務指標統計邏輯����、計算轉換邏輯��、腳本更新機制等�。
2. 外部數據源
用戶調研數據:通過市場調研得到用戶反饋數據���,存在的風險主要在于市場調研人員的敷衍執行自行捏造數據以及被調研對象自身對自身判斷的錯誤;
行業發展數據:通過百度指數���、微信指數����、阿里指數或者其它行業觀察機構統計的數據來觀察行業發展情況的數據;
合作方數據:合作方提供的數據���,不同公司之間在指標定義和統計規范上都可能有明顯差異�����,需要重點關注���。此外�,兩家公司之間的用戶匹配也是一大難點�,需要被重點關注���。
外部數據源的數據粒度一般較粗糙���,數據質量上也比較難以保證���,需要做更多的觀察和驗證����。我們可實施的檢查措施也相對較少�,只能在使用保持更高的警惕性���,慎之又慎才能更多地規避錯誤�����。
2) 關注取數過程���,檢查取數代碼
我們通過各種方法獲取數據���,SQL 查詢是數據類工作人員最常見的取數方式�����。SQL 語句的出錯將導致得到的數據集出錯���,以下是進行 SQL 檢查時需要被重點關注的點:
關注 join 處理的邏輯關系�����,包括采用的 SQL 連接方式 inner�����、left 還是 outer����、兩張表之間數據對應關系是 1:1��、1:n 還是n:m 等;
關注 SQL 細節�,包括是否采用 distinct 去重���、采用 case 語句劃分類別時的分類區間邊界����、group by 進行數據聚合的指標粒度是否正確;
多版本代碼檢查時關注選擇條件�����,對于 SQL 復用的場景�����,我們要重點關注數據選擇條件的更新替換是否完全;
聚合處理時�����,最好結合 if 條件排除極端值�����、異常值�。
3) 關注處理數據集的空值和異常值
在對數據集是否正確的檢查中���,最容易發現需要被處理的情況就是 空值和異常值
����??罩党霈F在數據集中往往一眼便能識別;異常值則需要一定經驗性地判斷��,例如:數值特別夸張��、文本特別長����、不匹配的數據類型���。在后續步驟的數據認知中�,對指標進行統計匯總���、分布觀察等也能幫助識別異常值����。
1. 空值處理
空值���,如果在平時的匯總統計中可忽略則忽略�,如果不可忽略則可采用以下方法來處理:
替換:使用平均值�、眾數進行替換或者使用最接近的數據替換它����,需要仔細對比尋找該行數據的其它值是否相近;
推斷:運用模型結合使用非空變量進行推斷���、預測計算得到這個空值����,如:時間序列���、回歸模型等;
刪除:實在無法處理的空值��,而且你已經確定它會影響到后續的計算�、分析�,那么你可以考慮將該行記錄刪除��。如果不確定是否會影響�,可考慮暫不處理����。
2. 異常值處理
初步觀察尋找異常值:
在 Excel 中可以通過篩選功能或去除重復值對數據列進行觀察;
在 SQL 中可以通過 distinct 進行去重觀察;
在 Python 中��,可以通過 pandas.drop_duplicates() 等方式進行去重觀察����。
垃圾數據或者異常值能采取的處理手段較少�,當數據記錄占比較大��,我們首先應去尋找造成數據異常的原因���,嘗試從源頭解決它;當數據記錄占比不多時��,我們可以采取直接刪除的方式�。
二���、數據類型認知
數據類型的認知主要可從類型�、數據單位��、數據量綱三個角度去觀察�����、去認知數據����。這一過程后����,我們一般對數據整體有一個比較粗線條的認識���,知道各列的統計單位�����、各列的數據類型�、量綱或者說數量級等����。
類型:同一列數據的數據類型必須保持一致!如:時間序列不得與數值型數據混合����、數值型數據不得與文本數據混合;
數據單位:同一列數據的單位必須保持一致!否則量級將完全不一致��,不具備任何可比性���。如:成交金額����,不能既有以分為單位也有以元為單位的混合;
數據量綱:不同數據列的量綱有時會有明顯差異���,主要指整數型數據和百分比數據��。如:活躍用戶數與平臺用戶活躍率��。當需要進行作圖對比觀察時候�,我們需要對量綱進行處理�,這涉及到標準化/歸一化��,常見的歸一化方法有:
標準差標準化:
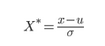
離差標準化:
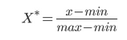
對數標準化:
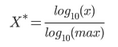
三��、指標值統計
1) 通過描述統計對數據集中趨勢�����、離散程度�����、分布作認知
描述統計指對數據進行一些描述性的統計��,包括均值�����、中位數��、方差等�����。它主要包含三個方面:
通過均值���、眾數��、中位數等觀察平均水平或說是集中趨勢;
通過方差與標準差等指標觀察離散程度���、波動大小;
通過分位數��、最大最小值�、數據分布圖等觀察指標的區間分布情況����。
1. 平均數
常常說的是算術平均數�,即“N 個數字相加后除以 N“��。在實際業務中��,我們還會使用加權平均數�,即“給不同維度的指標賦予不同業務權重后再相加除以權重總和���,一般權重可以設為 1”�����。
平均數的表示含義是:一個群體在某項數據上的一般水平或者集中趨勢���。
2. 眾數
眾數�,即序列中出現最多的那個數字����。
眾數真正的價值�����,不在于數值型數據中的使用而在于用在類別型的數據中�。在數值型數字中��,可能因為數字精度太細����,導致數字出現次數都很少�����,幾乎沒有眾數;而類別型數據中�,眾數有時會比較具有代表性��。比如:系統每
5 分鐘從天氣預報網站讀取一次實時天氣��,以小時為單位預測未來天氣時��,我們可以簡單取 12 次讀取中出現次數最多的記錄作為這個小時的平均天氣����。
3. 中位數
顧名思義�,中位數就是指排在中間位置的數字���,將序列分為兩部分�����。
中位數的優勢在于它能避免數據的平均水平受到異常值的影響����。在數據未進行較完整的清洗時�,強烈建議采用中位數代表序列的中間水平����。
4. 方差與標準差
方差和標準差是在概率論和統計方差衡量隨機變量或一組數據時離散程度的度量���,衡量數據序列的波動情況���。
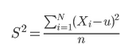
以上為方差計算公式���,開方的結果即為標準差����。
5. 四分位數
百分位即降數據升序排列后���,具體數據值的序號除以數據值的總數���,所得出的百分比���,即該數據值對應的百分位數��。我們一般比較關心:25%���、50%���、75% 分位數�。
6. 最大值���、最小值
顧名思義�,最大值��、最小值本身沒有什么好解釋的�����。
四分位數組合最大值�����、最小值���,可以讓我們初步認知數據的分布特征����。
7. 數據分布
進行了簡單的描述統計���,我們想對數據的分布進行簡單的觀察��,得到一個更加直觀的感受�����,可以制作頻率分布圖���、箱線圖來進行觀察�。
2) 相關系數統計�,對指標間的相互作用關系進行認知
當我們需要觀察兩個字段之間是否存在相互影響的關系時�����,我們可以簡單的使用相關系數�����。以下介紹三種相關系數����,在不通場景有不同的適用度�。
1. 皮爾遜相關
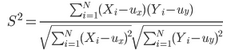
用于度量兩個變量X和Y之間的相關(線性相關)���,其值介于-1和1之間�����。
當 r>0 時��,表示兩變量正相關��,r<0 時����,兩變量為負相關;
當 |r|=1 時�,表示兩變量為完全線性相關���,即為函數關系;
當 r=0 時���,表示兩變量間無線性相關關系;
當 0<|r|<1 時��,表示兩變量存在一定程度的線性相關���。且 |r| 越接近 1�����,兩變量間線性關系越密切;|r| 越接近于 0����,表示兩變量的線性相關越弱;
一般可按三級劃分:0.8-1.0 極強相關����,0.6-0.8 強相關���,0.4-0.6 中等程度相關���,0.2-0.4 弱相關���,0.0-0.2 極弱相關或無相關�����。
適用條件:
數據(近似)服從正態分布
盡可能沒有異常點
用于描述線性相關
缺點:當樣本量 n 較小時����,相關系數的波動較大;
2. 斯皮爾曼等級相關
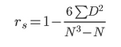
斯皮爾曼等級相關是根據等級資料研究兩個變量間相關關系的方法����,是依據兩列成對等級的各對等級數之差來進行計算的����。它與相關系數一樣��,取值在 -1 到 +1 之間�,所不同的是它是建立在等級的基礎上計算的�����。
適用條件:斯皮爾曼等級相關對原始變量的分布不作要求�,屬于非參數統計方法�,使用范圍更廣��。
缺點:
斯皮爾曼等級相關系數和皮爾遜相關系數都與樣本的容量有關�����,尤其是在樣本容量比較小的情況下��,其變異程度較大;
需要先對數據進行等級劃分�。
3. 肯德爾和諧系數
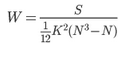
肯德爾和諧系數是計算多個等級變量相關程度的一種相關量����。
前述的斯皮爾曼等級相關討論的是兩個等級變量的相關程度���,用于評價時只適用于兩個評分者評價 N 個人或N件作品��,或同一個人先后兩次評價 N
個人或 N 件作品�����,而肯德爾和諧系數則適用于數據資料是多列相關的等級資料�,即可是 k 個評分者評 (N) 個對象�����,也可以是同一個人先后 k
次評 N 個對象�����。
通過求得肯德爾和諧系數�����,可以較為客觀地選擇好的作品或好的評分者��。
3) 多維交叉觀察�,利用數據進行業務分析
多維交叉觀察���,其實已經是分析階段的主要工作��。在初步的數據觀察中��,我們不會進行過多的交叉對比�����,除非不可避免的要對某些維度進行觀察�、驗證��。
以上就是關于數據初步認知的介紹.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
