Python語言描述機器學習之Logistic回歸算法
本文介紹機器學習中的Logistic回歸算法�����,我們使用這個算法來給數據進行分類�。Logistic回歸算法同樣是需要通過樣本空間學習的監督學習算法�����,并且適用于數值型和標稱型數據����,例如�,我們需要根據輸入數據的特征值(數值型)的大小來判斷數據是某種分類或者不是某種分類�����。
一�����、樣本數據
在我們的例子中�����,我們有這樣一些樣本數據:
樣本數據有3個特征值:X0X0���,X1X1���,X2X2
我們通過這3個特征值中的X1X1和X2X2來判斷數據是否符合要求��,即符合要求的為1���,不符合要求的為0����。
樣本數據分類存放在一個數組中
我們在logRegres.py文件中編寫如下函數來準備數據�,并將數據打印觀察一下:
#coding=utf-8
from numpy import *
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
print 'dataMat:\n',dataMat
我們來觀察一下這個數據樣本:
dataMat:
[[1.0, -0.017612, 14.053064], [1.0, -1.395634, 4.662541], [1.0, -0.752157, 6.53862], [1.0, -1.322371, 7.152853], [1.0, 0.423363, 11.054677], [1.0, 0.406704, 7.067335], [1.0, 0.667394, 12.741452], [1.0, -2.46015, 6.866805], [1.0, 0.569411, 9.548755], [1.0, -0.026632, 10.427743], [1.0, 0.850433, 6.920334], [1.0, 1.347183, 13.1755], [1.0, 1.176813, 3.16702], [1.0, -1.781871, 9.097953], [1.0, -0.566606, 5.749003], [1.0, 0.931635, 1.589505], [1.0, -0.024205, 6.151823], [1.0, -0.036453, 2.690988], [1.0, -0.196949, 0.444165], [1.0, 1.014459, 5.754399], [1.0, 1.985298, 3.230619], [1.0, -1.693453, -0.55754], [1.0, -0.576525, 11.778922], [1.0, -0.346811, -1.67873], [1.0, -2.124484, 2.672471], [1.0, 1.217916, 9.597015], [1.0, -0.733928, 9.098687], [1.0, -3.642001, -1.618087], [1.0, 0.315985, 3.523953], [1.0, 1.416614, 9.619232], [1.0, -0.386323, 3.989286], [1.0, 0.556921, 8.294984], [1.0, 1.224863, 11.58736], [1.0, -1.347803, -2.406051], [1.0, 1.196604, 4.951851], [1.0, 0.275221, 9.543647], [1.0, 0.470575, 9.332488], [1.0, -1.889567, 9.542662], [1.0, -1.527893, 12.150579], [1.0, -1.185247, 11.309318], [1.0, -0.445678, 3.297303], [1.0, 1.042222, 6.105155], [1.0, -0.618787, 10.320986], [1.0, 1.152083, 0.548467], [1.0, 0.828534, 2.676045], [1.0, -1.237728, 10.549033], [1.0, -0.683565, -2.166125], [1.0, 0.229456, 5.921938], [1.0, -0.959885, 11.555336], [1.0, 0.492911, 10.993324], [1.0, 0.184992, 8.721488], [1.0, -0.355715, 10.325976], [1.0, -0.397822, 8.058397], [1.0, 0.824839, 13.730343], [1.0, 1.507278, 5.027866], [1.0, 0.099671, 6.835839], [1.0, -0.344008, 10.717485], [1.0, 1.785928, 7.718645], [1.0, -0.918801, 11.560217], [1.0, -0.364009, 4.7473], [1.0, -0.841722, 4.119083], [1.0, 0.490426, 1.960539], [1.0, -0.007194, 9.075792], [1.0, 0.356107, 12.447863], [1.0, 0.342578, 12.281162], [1.0, -0.810823, -1.466018], [1.0, 2.530777, 6.476801], [1.0, 1.296683, 11.607559], [1.0, 0.475487, 12.040035], [1.0, -0.783277, 11.009725], [1.0, 0.074798, 11.02365], [1.0, -1.337472, 0.468339], [1.0, -0.102781, 13.763651], [1.0, -0.147324, 2.874846], [1.0, 0.518389, 9.887035], [1.0, 1.015399, 7.571882], [1.0, -1.658086, -0.027255], [1.0, 1.319944, 2.171228], [1.0, 2.056216, 5.019981], [1.0, -0.851633, 4.375691], [1.0, -1.510047, 6.061992], [1.0, -1.076637, -3.181888], [1.0, 1.821096, 10.28399], [1.0, 3.01015, 8.401766], [1.0, -1.099458, 1.688274], [1.0, -0.834872, -1.733869], [1.0, -0.846637, 3.849075], [1.0, 1.400102, 12.628781], [1.0, 1.752842, 5.468166], [1.0, 0.078557, 0.059736], [1.0, 0.089392, -0.7153], [1.0, 1.825662, 12.693808], [1.0, 0.197445, 9.744638], [1.0, 0.126117, 0.922311], [1.0, -0.679797, 1.22053], [1.0, 0.677983, 2.556666], [1.0, 0.761349, 10.693862], [1.0, -2.168791, 0.143632], [1.0, 1.38861, 9.341997], [1.0, 0.317029, 14.739025]]
labelMat:
[0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0]
樣本數據dataMat的第一列���,也就是我們的特征值X0X0全部為1����,這個問題我們之后在計算回歸參數時需要注意理解�����。所有的樣本數據一共100條�,對應的分類結果也是100個����。
那么����,我們現在的問題是:
我們要找到樣本空間中的特征值與分類結果的關系��。設計一個函數或者功能�����,實現在輸入一組特征值后��,能夠根據樣本空間特征值與分類結果的關系����,自動為輸入的數據進行分類�,即得到結果要么是1���,要么是0��。
二�����、Sigmoid函數
為了解決上一節我們提到的問題���,我們這里先介紹一下Sigmoid函數:
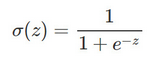
這個函數有如下幾個特征:
當z=0z=0時�,值為0.50.5
當zz不斷增大時���,值將趨近于1
當zz不斷減小時��,值將趨近于0
我們來看一下函數的曲線圖:
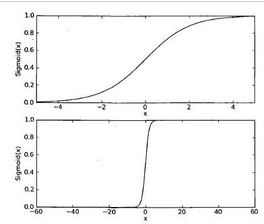
我們如果將樣本空間的3個特征值X0X0��、X1X1和X2X2的值代入到函數中�,計算出一個結果�����。那么這個結果將是接近與我們的分類結果的(0到1之間的一個數值)�。如果這個結果接近0那么我們就認為分類為0����,如果結果接近1我們就認為分類為1�����。
以什么方式代入到函數中呢����?其實簡單的相加就可以����,因為zz不斷增大或者減小時�,函數的值就相應的趨近于1或者0����。我們使z=x0+x1+x2z=x0+x1+x2
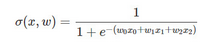
但是實際的情況是我們的計算結果和實際的分類值���,會有誤差����,甚至是完全不正確�����。為了矯正這個問題���,我們為樣本空間的3個特征值X0X0����、X1X1和X2X2��,一一定義一個回歸系數w0w0����、w1w1和w2w2���,使這個誤差減小�。即使z=w0x0+w1x1+w2x2
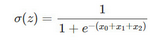
其實不難想象�,這組ww回歸系數的值決定了我們計算結果的準確性����,甚至是正確性�。也就是說�,這組ww的值反應了樣本空間分類的規則����。
那么��,我們在輸入一組樣本之外的數據時�����,配合正確的ww回歸系數����,我們就能得到比較接近樣本空間分類規則的分類結果�����。
問題又來了�����,我們怎么來得到這樣一組ww回歸系數呢���?
三���、梯度上升法
梯度上升法����,是在函數的梯度方向上�����,不斷的迭代計算參數值���,以找到一個最大的參數值�。迭代公式如下:
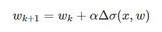
其中���,αα為步長��,Δσ(w)Δσ(w)為σ(w)σ(w)函數梯度����。關于梯度的推導請參考這里�����。作者的數學能力有限�,就不做說明了�。
最后�����,我們可以得到梯度的計算公式:
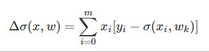
那么�,迭代公式如下:
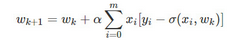
公式說明:
wk+1wk+1為本次迭代XX特征項的回歸系數結果
wkwk為上一次迭代XX特征項的回歸系數結果
αα為每次迭代向梯度方向移動的步長
xixi為XX特征項中第i個元素
yiyi是樣本中第i條記錄的分類樣本結果
σ(xi,wk)σ(xi,wk)是樣本中第i條記錄����,使用sigmoid函數和wkwk作為回歸系數計算的分類結果
[yi?σ(xi,wk)][yi?σ(xi,wk)]是樣本第i條記錄對應的分類結果值,與sigmoid函數使用wkwk作為回歸系數計算的分類結果值的誤差值���。
現在�,我們有了計算回歸系數的公式���,下面我們在logRegres.py文件中來實現一個函數�,實現計算樣本空間的回歸系數�����,并打印一下我們的結果:
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #100行3列
#print dataMatrix
labelMat = mat(classLabels).transpose() #100行1列
#print 'labelMat:\n',labelMat
print 'labelMat 的形狀:rowNum=',shape(labelMat)[0],'colNum=',shape(labelMat)[1]
rowNum,colNum = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((colNum,1)) #3行1列
#print shape(dataMatrix)
#print shape(weights)
#print shape(labelMat)
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #100行1列
#print h
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #3行1列
return weights
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
#weights=gradAscent(dataMat,labelMat)
#print 'dataMat:\n',dataMat
#print 'labelMat:\n',labelMat
print weights
打印結果:
回歸系數:
[[ 4.12414349]
[ 0.48007329]
[-0.6168482 ]]
為了驗證我們計算的回顧系數的準確性�,我們觀察一下樣本空間的散點圖和回歸系數的擬合曲線����。我們以z(x1,x2)=w0+w1x1+w2x2作為我們的擬合函數���,在坐標系中畫出它的擬合曲線��。以樣本空間中X1X1和X2X2的值作為橫坐標和縱坐標�����,畫出樣本空間的散點�。代碼如下:
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
y = y.transpose()
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
weights=gradAscent(dataMat,labelMat)
print '回歸系數:\n',weights
plotBestFit(weights)
運行后��,我們得到如下圖片:
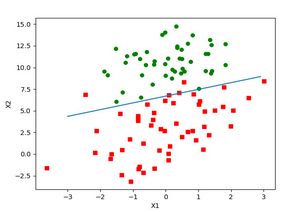
通過我們的觀察�����,我們的這個回歸系數的算法還是比較準確的�����,擬合曲線將樣本數據分成兩部分����,并且符合樣本的分類規則���。
接下來��,我們來實現一個分類器�����,并測試這個分類器:
def classify0(targetData,weights):
v = sigmoid(targetData*weights)
if v>0.5:
return 1.0
else :
return 0
def testClassify0():
dataMat,labelMat=loadDataSet()
examPercent=0.7
row,col=shape(dataMat)
exam=[]
exam_label=[]
test=[]
test_label=[]
for i in range(row):
if i < row*examPercent:
exam.append(dataMat[i])
exam_label.append(labelMat[i])
else:
test.append(dataMat[i])
test_label.append(labelMat[i])
weights=gradAscent(exam,exam_label)
errCnt=0
trow,tcol=shape(test)
for i in range(trow):
v=int(classify0(test[i],weights))
if v != int(test_label[i]):
errCnt += 1
print '計算值:',v,' 原值',test_label[i]
print '錯誤率:',errCnt/trow
if __name__=='__main__':
#dataMat,labelMat=loadDataSet()
#weights=gradAscent(dataMat,labelMat)
##print 'dataMat:\n',dataMat
##print 'labelMat:\n',labelMat
#print '回歸系數:\n',weights
#plotBestFit(weights)
testClassify0()
分類器的實現很簡單����。我們使用之前的樣本數據中的70條數據作為我們測試的樣本數據����,計算出回歸系數�����。然后用分類器對剩下的30條記錄進行分類�,然后將結果和樣本數據進行對比��。最后打印出錯誤率��。我們可以看到�����,錯誤率是0��,近乎完美�����!我們可以修改測試樣本在原樣本空間的比例多測試幾遍�����。那么�����,結論是我們的算法的準確率還不錯��!
那么���,到這里問題就解決了嗎�?好像還差一點什么��。我們來仔細研究一下我們計算回歸系數的方法����,不難發現��,這個過程中我們用樣本數據組成的矩陣進行了矩陣乘法����。也就是說����,為了計算回歸系數����,我們遍歷了整個樣本數據����。
我們的問題又來了��,我們例子中的樣本數據只有100條�,如果處理成千上萬的樣本數據�,我們的計算回歸系數的函數的計算復雜度會直線上升�。下面我們來看看如何優化這個算法�����。
四�、優化梯度上升算法——隨機梯度上升法
我們在理解了回歸系數迭代計算的公式

和我們實現的程序之后��。我們將計算回歸系數的方法進行如下改進:
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones((n,1)) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * mat(dataMatrix[i]).transpose()
return weights
每一次迭代計算回歸系數時����,只使用樣本空間中的一個樣本點來計算���。我們通過程序生成一個樣本散點和擬合曲線的圖來看一下這個算法的準確程度:
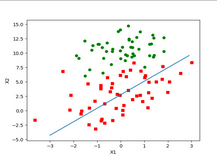
不難看出跟之前的算法相差還是比較大的���。原因是之前的算法是通過500次迭代算出的結果����,后者只經過了100次迭代�����。那么這里要說明的問題是���,回歸系數在隨著迭代次數的增加是趨于收斂的��,并且收斂的過程是存在波動的����。說白了�����,就是迭代的次數越多��,越接近我們想要的那個值�,但是由于樣本的數據是非線性的��,這個過程也會有一定的誤差�����。具體的回歸系數和迭代次數的關系大家可以參考一些教材���,例如《機器學習實戰》中的描述�����,這里就不做詳細介紹了��。
我們這里只介紹一下如何改進我們的算法���,使我們的算法能夠快速的收斂并減小波動���。方法如下:
每次迭代隨機的抽取一個樣本點來計算回歸向量
迭代的步長隨著迭代次數增大而不斷減少���,但是永遠不等于0
改進代碼���,并打印出擬合曲線和樣本散點圖:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones((n,1)) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * mat(dataMatrix[randIndex]).transpose()
del(dataIndex[randIndex])
return weights
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
#weights=stocGradAscent0(dataMat,labelMat)
weights=stocGradAscent1(dataMat,labelMat)
#weights=gradAscent(dataMat,labelMat)
#print 'dataMat:\n',dataMat
#print 'labelMat:\n',labelMat
#print '回歸系數:\n',weights
plotBestFit(weights)
#testClassify0()
默認是150迭代的樣本散點圖和擬合曲線圖:
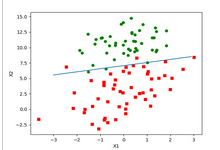
不難看出準確程度與第一個算法很接近了���!
五����、總結
Logistic回歸算法主要是利用了Sgimoid函數來為數據分類���,分類的準確的關鍵取決于從樣本空間中計算出的回歸系數�����。我們使用梯度上升法來計算回歸系數�,并采用隨機梯度上升法來改進了算法的性能�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
