深度學習防止過擬合的方法
過擬合即在訓練誤差很小,而泛化誤差很大,因為模型可能過于的復雜,使其”記住”了訓練樣本,然而其泛化誤差卻很高,在傳統的機器學習方法中有很大防止過擬合的方法,同樣這些方法很多也適合用于深度學習中,同時深度學習中又有一些獨特的防止過擬合的方法,下面對其進行簡單的梳理.
1. 參數范數懲罰
范數正則化是一種非常普遍的方法,也是最常用的方法,假如優化:
minObj(θ)=L(y,f(x))+αG(θ)
其中L為經驗風險,其為在訓練樣本上的誤差,而G為對參數的懲罰,也叫結構風險.α是平衡兩者,如果太大則對應的懲罰越大,如過太小,甚至接近與0,則沒有懲罰.
最常用的范數懲罰為L1,L2正則化,L1又被成為Lasso:
||w||1=|w1|+|w2|+...
即絕對值相加,其趨向于是一些參數為0.可以起到特征選擇的作用.
L2正則化為:
||w||2=w12+w22+...????????????√
其趨向與,使權重很小.其又成為ridge.
2. 數據增強
讓模型泛化的能力更好的最好辦法就是使用更多的訓練數據進行訓練,但是在實踐中,我們擁有的數據是有限的,解決這一問題可以人為的創造一些假數據添加到訓練集中.
一個具體的例子:
在AlexNet中,將256*256圖像隨機的截取224*224大小,增加了許多的訓練樣本,同時可以對圖像進行左右翻轉,增加樣本的個數,實驗的結果可以可降低1%的誤差.
在神經網絡中輸入噪聲也可以看做是數據增強的一種方式.
3. 提前終止
如下圖所示(圖片來源deep learning),當隨著模型的能力提升,訓練集的誤差會先減小再增大,這樣可以提前終止算法減緩過擬合現象.關于算法的具體流程參考deep learning.
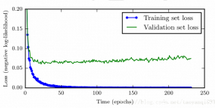
提前終止是一種很常用的緩解過擬合的方法,如在決策樹的先剪枝的算法,提前終止算法,使得樹的深度降低,防止其過擬合.
4. 參數綁定與參數共享
在卷積神經網絡CNN中(計算機視覺與卷積神經網絡 ),卷積層就是其中權值共享的方式,一個卷積核通過在圖像上滑動從而實現共享參數,大幅度減少參數的個數,用卷積的形式是合理的,因為對于一副貓的圖片來說,右移一個像素同樣還是貓,其具有局部的特征.這是一種很好的緩解過擬合現象的方法.
同樣在RNN中用到的參數共享,在其整條時間鏈上可以進行參數的共享,這樣才使得其能夠被訓練.
5. bagging 和其他集成方法
其實bagging的方法是可以起到正則化的作用,因為正則化就是要減少泛化誤差,而bagging的方法可以組合多個模型起到減少泛化誤差的作用.
在深度學習中同樣可以使用此方法,但是其會增加計算和存儲的成本.
6. Dropout
Dropout提供了一種廉價的Bagging集成近似,能夠訓練和評估指數級數量的神經網絡��。dropout可以隨機的讓一部分神經元失活,這樣仿佛是bagging的采樣過程,因此可以看做是bagging的廉價的實現.
但是它們訓練不太一樣,因為bagging,所有的模型都是獨立的,而dropout下所有模型的參數是共享的.
通?����?梢赃@樣理解dropout:假設我們要判別一只貓,有一個神經元說看到有毛就是貓,但是如果我讓這個神經元失活,它還能判斷出來是貓的話,這樣就比較具有泛化的能力,減輕了過擬合的風險.
7. 輔助分類節點(auxiliary classifiers)
在Google Inception V1中,采用了輔助分類節點的策略,即將中間某一層的輸出用作分類,并按一個較小的權重加到最終的分類結果中,這樣相當于做了模型的融合,同時給網絡增加了反向傳播的梯度信號,提供了額外的正則化的思想.
8. Batch Normalization
在Google Inception V2中所采用,是一種非常有用的正則化方法,可以讓大型的卷積網絡訓練速度加快很多倍,同事收斂后分類的準確率也可以大幅度的提高.
BN在訓練某層時,會對每一個mini-batch數據進行標準化(normalization)處理,使輸出規范到N(0,1)的正太分布,減少了Internal
convariate
shift(內部神經元分布的改變),傳統的深度神經網絡在訓練是,每一層的輸入的分布都在改變,因此訓練困難,只能選擇用一個很小的學習速率,但是每一層用了BN后,可以有效的解決這個問題,學習速率可以增大很多倍.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
