數據預處理的一些方法
現實世界中�,數據集存在著不完整���、包含噪聲和不一致等特點����,無法直接用來挖掘知識�。收集數據的設備可能出故障�����,人為輸入數據時出錯或缺失�����,數據傳輸中引起的錯誤都將造成數據集含有不正確的屬性值�����。數據中各個屬性的單位不同����,也可能造成分析過程以及預測模型的不精確����?��?梢允褂靡韵路椒A處理數據集��。
(1)刪除缺失值�����。
(2)箱線圖
R語言使用boxplot()命令繪制箱線圖�����,箱線圖也是我們常說的五數分布���,通過計算 IQR=Q3-Q1�,即第三個四分位數減去第一個四分位數�。常用經驗是剔除至少高于第三個四分位數或低于第一個四分位數1.5*IQR處的值����。但在實際生產過程中�����,1.5只是經驗帶給人們的參考值��,具體情況應修改這個數值����。例如本次試驗中�����,如果使用1.5這個數字��,將會剔除大部分數據點����,使得數據集失去意義�。部分屬性甚至高達10才可達到既剔除無用數據又最大限度的保留原本數據的目的�����。如圖1所示���。圖中用o代替的點即為需要剔除的離群點�。
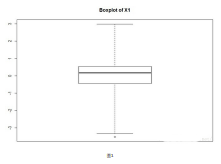
圖1
(3)數據標準化/歸一化
數據中心化是指講每一項數據減去該數據集的均值���。值得注意的是�,標準化會對原始數據產生改變�,需要保存所使用的標準化方法的參數�,以便對后續的數據進行統一的標準化��。數據標準化有幾種不同的方法:
1. min-max標準化公式:新數據=(原數據-極小值)/(極大值-極小值)�����。這樣能將原始值映射在[0,1]區間中的某值���。
2. z-score法:將中心化后的數據除以數據集的標準差�����,這樣做的意義是消除量綱對數據結構的影響��。R語言中使用scale(x,center = T,scale =T)命令進行z-score標準化�����。
3. 小數定標標準化
4. 對數Logistic模式公式:新數據=1/(1+e^(-原數據))
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
