最流行的4個機器學習數據集
機器學習算法需要作用于數據����,而數據的本質則決定了應用的機器學習算法是否合適���,而數據的質量也會決定算法表現的好壞程度�。所以會研究數據�����,會分析數據很重要�����。本文作為學習研究數據系列博文的開篇����,列舉了4個最流行的機器學習數據集���。
Iris
Iris也稱鳶尾花卉數據集����,是一類多重變量分析的數據集�。通過花萼長度�����,花萼寬度��,花瓣長度���,花瓣寬度4個屬性預測鳶尾花卉屬于(Setosa�����,Versicolour�����,Virginica)三個種類中的哪一類��。

Adult
該數據從美國1994年人口普查數據庫抽取而來���,可以用來預測居民收入是否超過50K$/year���。該數據集類變量為年收入是否超過50k$�,屬性變量包含年齡�����,工種����,學歷�����,職業����,人種等重要信息�,值得一提的是��,14個屬性變量中有7個類別型變量����。

Wine
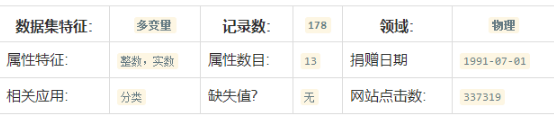
這份數據集包含來自3種不同起源的葡萄酒的共178條記錄����。13個屬性是葡萄酒的13種化學成分�����。通過化學分析可以來推斷葡萄酒的起源�。值得一提的是所有屬性變量都是連續變量���。
Car Evaluation
這是一個關于汽車測評的數據集����,類別變量為汽車的測評�,(unacc��,ACC��,good���,vgood)分別代表(不可接受�,可接受����,好�����,非常好)���,而6個屬性變量分別為「買入價」���,「維護費」�,「車門數」����,「可容納人數」�����,「后備箱大小」����,「安全性」�����。值得一提的是6個屬性變量全部是有序類別變量���,比如「可容納人數」值可為「2���,4��,more」����,「安全性」值可為「low,
med, high」��。

小結
通過比較以上4個數據集的差異�,簡單地總結:當需要試驗較大量的數據時��,我們可以想到「Adult」�����;當想研究變量之間的相關性時�,我們可以選擇變量值只為整數或實數的「Iris」和「Wine」��;當想研究logistic回歸時�,我們可以選擇類變量值只有兩種的「Adult」��;當想研究類別變量轉換時��,我們可以選擇屬性變量為有序類別的「Car
Evaluation」����。更多的嘗試還需要對這些數據集了解更多才行��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
