Python機器學習算法之k均值聚類(k-means)
一開始的目的是學習十大挖掘算法(機器學習算法),并用編碼實現一遍����,但越往后學習����,越往后實現編碼����,越發現自己的編碼水平低下���,學習能力低��。這一個k-means算法用Python實現竟用了三天時間��,可見編碼水平之低�,而且在編碼的過程中看了別人的編碼����,才發現自己對numpy認識和運用的不足��,在自己的代碼中有很多可以優化的地方�,比如求均值的地方可以用mean直接對數組求均值��,再比如去最小值的下標�,我用的是argsort排序再取列表第一個���,但是有argmin可以直接用啊�����。下面的代碼中這些可以優化的并沒有改��,這么做的原因是希望做到拋磚引玉�����,歡迎大家丟玉�,如果能給出優化方法就更好了
一.k-means算法
人以類聚�����,物以群分����,k-means聚類算法就是體現���。數學公式不要����,直接用白話描述的步驟就是:
1.隨機選取k個質心(k值取決于你想聚成幾類)
2.計算樣本到質心的距離�����,距離質心距離近的歸為一類�����,分為k類
3.求出分類后的每類的新質心
4.判斷新舊質心是否相同�,如果相同就代表已經聚類成功�,如果沒有就循環2-3直到相同
用程序的語言描述就是:
1.輸入樣本
2.隨機去k個質心
3.重復下面過程知道算法收斂:
計算樣本到質心距離(歐幾里得距離)
樣本距離哪個質心近�����,就記為那一類
計算每個類別的新質心(平均值)
二.需求分析
數據來源:從國際統計局down的數據�����,數據為城鄉居民家庭人均收入及恩格爾系數(點擊這里下載)
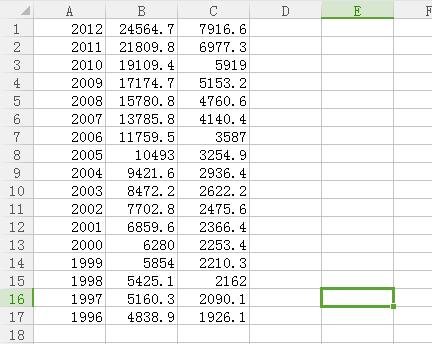
數據描述:
1.橫軸:城鎮居民家庭人均可支配收入和農村居民家庭人均純收入�,
2.縱軸:1996-2012年�����。
3.數據為年度數據
需求說明:我想把這數據做個聚類分析�,看人民的收入大概經歷幾個階段(感覺我好高大上?��。?
需求分析:
1.由于樣本數據有限��,就兩列���,用k-means聚類有很大的準確性
2.用文本的形式導入數據����,結果輸出聚類后的質心��,這樣就能看出人民的收入經歷了哪幾個階段
三.Python實現
引入numpy模塊���,借用其中的一些方法進行數據處理�����,上代碼:
# -*- coding=utf-8 -*-
"""
authon:xuwf
created:2017-02-07
purpose:實現k-means算法
"""
importrandom
'''裝載數據'''
defload():
data=np.loadtxt('data\k-means.csv',delimiter=',')
returndata
'''計算距離'''
defcalcDis(data,clu,k):
clalist=[]#存放計算距離后的list
data=data.tolist()#轉化為列表
clu=clu.tolist()
foriinrange(len(data)):
clalist.append([])
forjinrange(k):
dist=round(((data[i][1]-clu[j][0])**2+(data[i][2]-clu[j][1])**2)*0.05,1)
clalist[i].append(dist)
clalist=np.array(clalist)#轉化為數組
returnclalist
'''分組'''
defgroup(data,clalist,k):
claList=clalist.tolist()
data=data.tolist()
foriinrange(k):
#確定要分組的個數���,以空列表的形式��,方便下面進行數據的插入
grouplist.append([])
forjinrange(len(clalist)):
sortNum=np.argsort(clalist[j])
grouplist[sortNum[0]].append(data[j][1:])
grouplist=np.array(grouplist)
returngrouplist
'''計算質心'''
defcalcCen(data,grouplist,k):
clunew=[]
data=data.tolist()
grouplist=grouplist.tolist()
templist=[]
#templist=np.array(templist)
foriinrange(k):
#計算每個組的新質心
sumx=0
sumy=0
forjinrange(len(grouplist[i])):
sumx+=grouplist[i][j][0]
sumy+=grouplist[i][j][1]
clunew.append([round(sumx/len(grouplist[i]),1),round(sumy/len(grouplist[i]),1)])
clunew=np.array(clunew)
#clunew=np.mean(grouplist,axis=1)
returnclunew
'''優化質心'''
defclassify(data,clu,k):
clalist=calcDis(data,clu,k)#計算樣本到質心的距離
grouplist=group(data,clalist,k)#分組
foriinrange(k):
#替換空值
ifgrouplist[i]==[]:
grouplist[i]=[4838.9,1926.1]
clunew=calcCen(data,grouplist,k)
sse=clunew-clu
#print "the clu is :%r\nthe group is :%r\nthe clunew is :%r\nthe sse is :%r" %(clu,grouplist,clunew,sse)
returnsse,clunew,data,k
if__name__=='__main__':
k=3#給出要分類的個數的k值
data=load()#裝載數據
clu=random.sample(data[:,1:].tolist(),k)#隨機取質心
clu=np.array(clu)
sse,clunew,data,k=classify(data,clu,k)
whilenp.any(sse!=0):
sse,clunew,data,k=classify(data,clunew,k)
clunew=np.sort(clunew,axis=0)
print"the best cluster is %r"%clunew
四.測試
直接運行程序就可以�,k值可以自己設置���,會發現k=3的時候結果數據是最穩定的�����,這里我就不貼圖了
需要注意的是上面的代碼里面主函數里的數據結構都是array�,但是在每個小函數里就有可能轉化成了list��,主要原因是需要進行array的一下方法進行計算�,而轉化為list的原因是需要向數組中插入數據��,但是array做不到?。ㄖ辽傥覜]找到怎么做)����。于是這里就出現了一個問題���,那就是數據結構混亂����,到最后我調試了半天����,干脆將主函數的數據結構都轉化成array��,在小函數中輸入的array�,輸出的時候也轉化成了array���,這樣就清晰多了
五.算法分析
單看這個算法還是較好理解的����,但是算法的目的是聚類����,那就要考慮到聚類的準確性�,這里聚類的準確性取決于k值�、初始質心和距離的計算方式�����。
k值就要看個人經驗和多次試驗了�,算法結果在哪個k值的時候更穩定就證明這個分類更加具有可信度�,其中算法結果的穩定也取決于初始質心的選擇
初始質心一般都是隨機選取的����,怎么更準確的選擇初始質心呢�����?有種較難實現的方法是將樣本中所有點組合起來都取一遍��,然后計算算法收斂后的所有質心到樣本的距離之和�,哪個距離最小��,哪個的聚類就最為成功�����,相對應的初始質心就選取的最為準確��。但是這種方法有很大的計算量�,如果樣本很大���,維度很多�,那就是讓電腦干到死的節奏
距離的計算方式取決于樣本的特征�����,有很多的選擇����,入歐式距離����,夾角余弦距離��,曼哈頓距離等���,具體的數據特性用具體的距離計算方式
六.項目評測
1.項目總結數據源的數據很干凈�,不需要進行過多的數據清洗和數據降噪�����,數據預處理的工作成本接近為0����。需求基本實現
2.還能做什么:可以用計算最小距離之和的方法求出最佳k值�����,這樣就可以得到穩定的收入階梯���;可以引入畫圖模塊�����,將數據結果進行數據可視化�,顯得更加直觀����;如果可能應該引入更多的維度或更多的數據�����,這樣得到的聚類才更有說服力�����。
以上就是本文的全部內容���,希望對大家的學習有所幫助
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
