從線性回歸到無監督學習��,數據科學家需要掌握的十大統
不管你對數據科學持什么態度����,都不可能忽略分析�、組織和梳理數據的重要性�。Glassdoor 網站根據大量雇主和員工的反饋數據制作了「美國最好的
25
個職位」榜單����,其中第一名就是數據科學家�����。盡管排名已經頂尖了�,但數據科學家的工作內容一定不會就此止步�。隨著深度學習等技術越來越普遍���、深度學習等熱門領域越來越受到研究者和工程師以及雇傭他們的企業的關注����,數據科學家繼續走在創新和技術進步的前沿��。
盡管具備強大的編程能力非常重要��,但數據科學不全關于軟件工程(實際上�,只要熟悉 Python
就足以滿足編程的需求)����。數據科學家需要同時具備編程����、統計學和批判思維能力��。正如 Josh Wills
所說:「數據科學家比程序員擅長統計學����,比統計學家擅長編程�?!刮易约赫J識很多軟件工程師希望轉型成為數據科學家����,但是他們盲目地使用
TensorFlow 或 Apache Spark
等機器學習框架處理數據���,而沒有全面理解其背后的統計學理論知識����。因此他們需要系統地研究統計機器學習��,該學科脫胎于統計學和泛函分析�����,并結合了信息論���、最優化理論和線性代數等多門學科����。
為什么學習統計學習���?理解不同技術背后的理念非常重要���,它可以幫助你了解如何使用以及什么時候使用����。同時�,準確評估一種方法的性能也非常重要�,因為它能告訴我們某種方法在特定問題上的表現����。此外���,統計學習也是一個很有意思的研究領域���,在科學���、工業和金融領域都有重要的應用����。最后�,統計學習是訓練現代數據科學家的基礎組成部分��。統計學習方法的經典研究主題包括:
線性回歸模型
感知機
k 近鄰法
樸素貝葉斯法
決策樹
Logistic 回歸于最大熵模型
支持向量機
提升方法
EM 算法
隱馬爾可夫模型
條件隨機場
之后我將介紹 10 項統計技術���,幫助數據科學家更加高效地處理大數據集的統計技術�。在此之前��,我想先厘清統計學習和機器學習的區別:
機器學習是偏向人工智能的分支�。
統計學習方法是偏向統計學的分支�。
機器學習更側重大規模應用和預測準確率�。
統計學系側重模型及其可解釋性��,以及精度和不確定性����。
二者之間的區別越來越模糊���。
1. 線性回歸
在統計學中��,線性回歸通過擬合因變量和自變量之間的最佳線性關系來預測目標變量�。最佳擬合通過盡量縮小預測的線性表達式和實際觀察結果間的距離總和來實現����。沒有其他位置比該形狀生成的錯誤更少���,從這個角度來看��,該形狀的擬合是「最佳」�����。線性回歸的兩個主要類型是簡單線性回歸和多元線性回歸�。
簡單線性回歸使用一個自變量通過擬合最佳線性關系來預測因變量的變化情況��。多元線性回歸使用多個自變量通過擬合最佳線性關系來預測因變量的變化趨勢���。
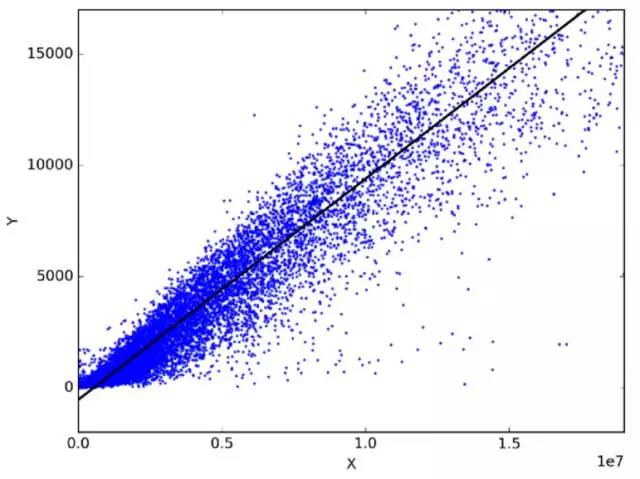
任意選擇兩個日常使用且相關的物體����。比如����,我有過去三年月支出�����、月收入和每月旅行次數的數據?,F在我需要回答以下問題:
我下一年月支出是多少����?
哪個因素(月收入或每月旅行次數)在決定月支出方面更重要���?
月收入和每月旅行次數與月支出之間是什么關系�����?
2. 分類
分類是一種數據挖掘技術����,為數據分配類別以幫助進行更準確的預測和分析���。分類是一種高效分析大型數據集的方法�,兩種主要的分類技術是:logistic 回歸和判別分析(Discriminant Analysis)�。
logistic 回歸是適合在因變量為二元類別的回歸分析��。和所有回歸分析一樣����,logistic 回歸是一種預測性分析��。logistic
回歸用于描述數據��,并解釋二元因變量和一或多個描述事物特征的自變量之間的關系���。logistic 回歸可以檢測的問題類型如下:
體重每超出標準體重一磅或每天每抽一包煙對得肺癌概率(是或否)的影響���。
卡路里攝入�、脂肪攝入和年齡對心臟病是否有影響(是或否)��?
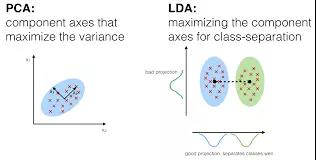
在判別分析中��,兩個或多個集合和簇等可作為先驗類別��,然后根據度量的特征把一個或多個新的觀察結果分類成已知的類別����。判別分析對每個對應類中的預測器分布
X 分別進行建模����,然后使用貝葉斯定理將其轉換成根據 X 的值評估對應類別的概率�����。此類模型可以是線性判別分析(Linear
Discriminant Analysis)��,也可以是二次判別分析(Quadratic Discriminant Analysis)����。
線性判別分析(LDA):為每個觀察結果計算「判別值」來對它所處的響應變量類進行分類����。這些分值可以通過找到自變量的線性連接來獲得�。它假設每個類別的觀察結果都從多變量高斯分布中獲取���,預測器變量的協方差在響應變量 Y 的所有 k 級別中都很普遍�����。
二次判別分析(QDA):提供另外一種方法�����。和 LDA 類似��,QDA 假設 Y 每個類別的觀察結果都從高斯分布中獲取�。但是���,與 LDA 不同的是�,QDA 假設每個類別具備自己的協方差矩陣�。也就是說�,預測器變量在 Y 的所有 k 級別中不是普遍的��。
3. 重采樣方法
重采樣方法(Resampling)包括從原始數據樣本中提取重復樣本����。這是一種統計推斷的非參數方法�。即�����,重采樣不使用通用分布來逼近地計算概率 p 的值�。
重采樣基于實際數據生成一個獨特的采樣分布����。它使用經驗性方法�,而不是分析方法�����,來生成該采樣分布����。重采樣基于數據所有可能結果的無偏樣本獲取無偏估計����。為了理解重采樣的概念�����,你應該先了解自助法(Bootstrapping)和交叉驗證(Cross-Validation):
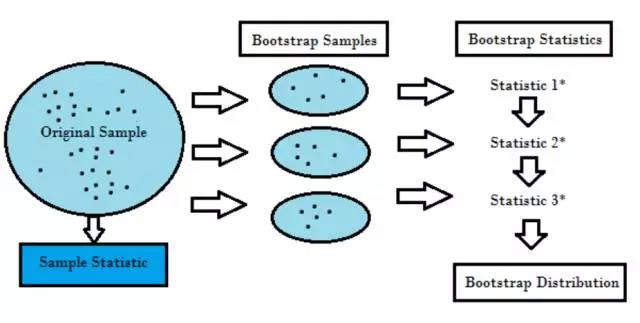
自助法(Bootstrapping)適用于多種情況�����,如驗證預測性模型的性能�����、集成方法�����、偏差估計和模型方差�����。它通過在原始數據中執行有放回取樣而進行數據采樣��,使用「未被選中」的數據點作為測試樣例���。我們可以多次執行該操作���,然后計算平均值作為模型性能的估計�。
交叉驗證用于驗證模型性能��,通過將訓練數據分成 k 部分來執行����。我們將 k-1 部分作為訓練集�����,「留出」的部分作為測試集���。將該步驟重復 k 次��,最后取 k 次分值的平均值作為性能估計�。
通常對于線性模型而言�����,普通最小二乘法是擬合數據時主要的標準�����。下面 3 個方法可以提供更好的預測準確率和模型可解釋性��。
4. 子集選擇
該方法將挑選 p 個預測因子的一個子集�����,并且我們相信該子集和所需要解決的問題十分相關�����,然后我們就能使用該子集特征和最小二乘法擬合模型����。
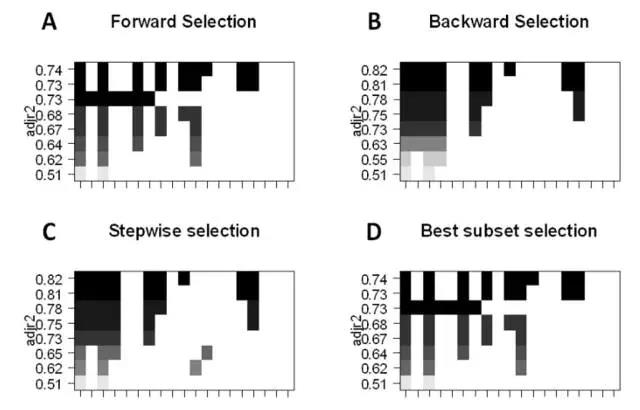
最佳子集的選擇:我們可以為 p 個預測因子的每個組合擬合單獨的 OLS 回歸����,然后再考察各模型擬合的情況��。該算法分為兩個階段:(1)擬合包含
k 個預測因子的所有模型��,其中 k
為模型的最大長度�;(2)使用交叉驗證預測損失選擇單個模型����。使用驗證或測試誤差十分重要�����,且不能簡單地使用訓練誤差評估模型的擬合情況�����,這因為 RSS
和 R^2 隨變量的增加而單調遞增�����。最好的方法就是通過測試集中最高的 R^2 和最低的 RSS 來交叉驗證地選擇模型��。
前向逐步地選擇會考慮 p
個預測因子的一個較小子集���。它從不含預測因子的模型開始���,逐步地添加預測因子到模型中���,直到所有預測因子都包含在模型����。添加預測因子的順序是根據不同變量對模型擬合性能提升的程度來確定的���,我們會添加變量直到再沒有預測因子能在交叉驗證誤差中提升模型����。
后向逐步選擇先從模型中所有 p 預測器開始�,然后迭代地移除用處最小的預測器���,每次移除一個�����。
混合法遵循前向逐步方法���,但是在添加每個新變量之后�����,該方法可能還會移除對模型擬合無用的變量��。
5. Shrinkage
這種方法涉及到使用所有 p
個預測因子進行建模�,然而�����,估計預測因子重要性的系數將根據最小二乘誤差向零收縮����。這種收縮也稱之為正則化��,它旨在減少方差以防止模型的過擬合���。由于我們使用不同的收縮方法���,有一些變量的估計將歸零��。因此這種方法也能執行變量的選擇��,將變量收縮為零最常見的技術就是
Ridge 回歸和 Lasso 回歸���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
