數據科學目標��、挑戰以及門派
隨著云計算和人工智能的發展���,數據科學這門新的綜合學科被越來越多的人所熟知����,業界也普遍看好其在未來的發展前景����。體現在就業市場上��,與這個行業相關的數據科學家和數據工程師成為了“21世紀最吸引人的職業”��。
就像“一千個人眼里有一千個哈姆雷特”一樣���,對于什么是數據科學也有很多種不同的解讀��,并由此衍生出很多相關概念��,比如數據驅動(data
driven)�、大數據(big data)���、分布式計算(distributed
computing)等�。但這些概念都沒能全面地描述數據科學的內涵�����,本文將從目標��、挑戰和門派三個方面來闡述什么是數據科學�。
一��、目標
數據科學是一門最近大火的新興學科�。這門學科的目標十分簡單����,就是如何從實際的生活中提取出數據���,然后利用計算機的運算能力和模型算法從這些數據中找出一些有價值的內容�����,為商業決策提供支持���。
傳統的數據分析手段是所謂的商業智能(business
intelligence)����。這種方法通常將數據按不同的維度交叉分組����,并在此基礎上�,利用統計方法分析每個組別里的信息�����。比如商業智能中最常見的問題是:“過去3個月�����,通過搜索引擎進入網站并成功完成注冊的新用戶里��,年齡分布情況如何?若將上面的用戶群按年齡段分組�����,各組中有多大比例的用戶在完成注冊后��,完成了至少一次消費?”
這樣的分析是非常有用的���,能揭示一些數據的直觀信息���。但這樣的方法如同盲人摸象��,只能告訴我們數據在某個局部的情況���,而不能給出數據的全貌��。而且對于某些問題���,這樣的結果顯得有些不夠用�����。比如用戶注冊之后完成消費的比例與哪些因素相關?又比如對于某個客戶���,他對某一產品的估計是多少?在這些場景下����,我們就需要更加精細的數據分析工具—機器學習和統計模型����。這些內容正是數據科學的核心內容���。
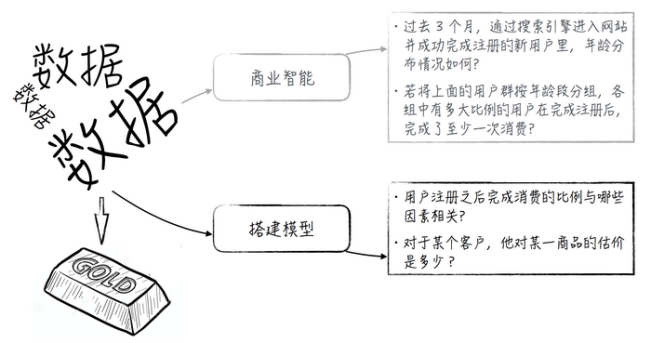
圖1
二�����、挑戰
在數據科學實踐中��,我們將使用較為復雜的機器學習或統計模型對數據做精細化的分析和預測���。這在工程實現和模型搭建兩方面都提出了挑戰���,如圖2所示�。
工程實現的挑戰
數據科學在工程上的挑戰可以大致分為3類:特征提取����、矩陣運算和分布式機器學習����。
(1)一個建模項目的成功在很大程度上依賴于建模前期的特征提取�����。它包含數據清洗����、數據整合�、變量歸一化等����。經過處理后�����,原本攪作一團的原始數據將被轉換為能被模型使用的特征�。這些工作需要大量的自動化程序來處理��,特別是面對大數據時�����,因為這些大數據無法靠“人眼”來檢查����。在一個典型的建模項目中����,這部分花費的時間遠遠大于選擇和編寫模型算法的時間�。
(2)對于一個復雜的數學模型���,計算機通常需要使用類似隨機梯度下降法的最優化算法來估算它的模型參數���。這個過程需要大量的循環�����,才能使參數到達收斂值附近�����。因此即使面對的是很小的數據集�,復雜的模型也需要很長時間才能得到正確的參數估計�����。而且模型在結構上越復雜�����,需要估計的參數也就越多�。對這些大量的模型參數同時做更新���,在數學上對應著矩陣運算���。但傳統的CPU架構并不擅長做這樣的運算����,這導致模型訓練需要耗費大量的時間��。為了提高模型的訓練速度�,需要將相應的矩陣運算(模型參數的估算過程)移植到GPU或者特制的計算芯片上����,比如TPU����。
(3)近年來����,隨著分布式系統的流行和普及��,存儲海量數據成為了業界的標配��。為了能在這海量的數據上使用復雜模型����,需要將原本在一臺機器上運行的模型算法改寫成能在多臺機器上并行運行�����,這也是分布式機器學習的核心內容��。
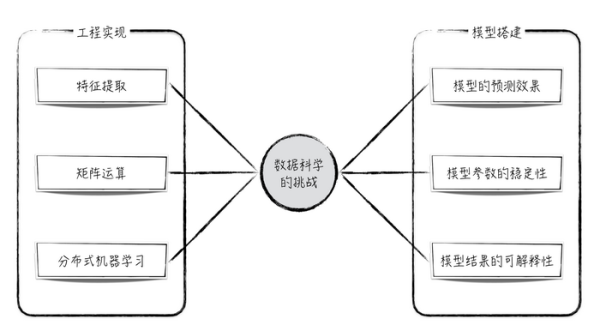
圖2
模型搭建的挑戰
數據科學對模型搭建的要求也可以總結為3點:模型預測效果好�����、模型參數是穩定且“正確”的��、模型結果容易解釋�。
(1)模型的預測效果好�,這是數據科學成功的關鍵����。而一個模型的預測效果取決于它的假設是否被滿足����。從數學上來看����,任何一個模型除去假設部分�,它的其他推導都是嚴謹的數學演算��,是無懈可擊的���。因此模型假設就像模型的阿喀琉斯之踵�����,是它唯一的薄弱環節����。當問題場景或數據滿足模型假設時��,模型的效果一定不會差��,反之��,則預測效果就無法保證了����。但在實際生產中�����,針對一個具體的問題����,幾乎不可能找到一個模型����,它的假設被百分之百地滿足�����。這時就需要避重就輕�����,通過特征提取等手段�,盡量避免違反那些對結果影響很大的假設�。這就是為什么說“所有模型都是錯的�,但是���,其中有一些是有用的”����。
(2)除了被用來對未知數據做預測外�����,模型另一個重要的功能就是對已有數據做分析�,比如哪個變量對結果的影響最大或者某個變量對結果到底是正向影響還是負向影響等�����。這些分析結果在很大程度上依賴于模型參數的估計值��,后者的準確與否直接決定分析結果的質量�����。但問題是�,模型參數的估計值是不太“可靠”的�����。例如從訓練數據中隨機抽取兩個不完全一樣的數據子集A和B�����,然后用這兩個數據集分別訓練同一個模型��。得到的參數估計值幾乎不可能完全一樣�。從數學的角度來看�����,這說明模型參數的估計值其實是一個隨機變量�����,具體的值取決于訓練模型時使用的數據��。于是我們要求這些估計值是“正確”的:圍繞參數真實值上下波動(也就是說它們的期望等于參數真實值)����。我們還要求這些估計值是穩定的:波動的幅度不能太大(也就是說它們的方法比較小)�����。這樣就可以把參數估計值的“不可靠性”控制在可接受的范圍內����。
(3)數據科學家將模型搭建好�,并不是一個數據科學項目的終點�。為了充分發揮數據的價值�����,需要將模型結果應用到實際的生產中�����,比如為手機銀行APP架設實時反欺詐系統��,或者將利用新搭建的車禍風險模型為汽車保險定價等�。參與這個過程的不僅有懂模型的數據科學家�,還有更多非技術的業務人員��。而后者往往是使用模型的主力�,比如根據反欺詐系統的結果����,對可疑用戶進行人工審核�����,又或者向客戶解釋為什么他的車險比別人貴��。為了幫助他們更好地理解模型結果�,需要將復雜深奧的模型翻譯成直觀的普通語言���。這要求模型是能被解釋的�����,而且是容易被解釋的��。
三����、兩大門派
和武俠世界里有少林和武當兩大門派一樣�,數據科學領域也有兩個不同的學派:以統計分析為基礎的統計學派�����,以及以機器學習為基礎的人工智能派��。雖然這兩個學派的目的都是從數據中挖掘價值�,但彼此“都不服氣”�。注重模型預測效果的人工智能派認為統計學派“固步自封”����,研究和使用的模型都只是一些線性模型���,太過簡單���,根本無法處理復雜的現實數據���。而注重假設和模型解釋的統計學派則認為人工智能派搭建的模型缺乏理論依據��、無法解釋����,很難幫助我們通過模型去理解數據����。
在學術上���,通常將統計學派的模型稱為數據模型(data model)�����,將人工智能派的模型稱為算法模型(algorithm model)�����,如圖3所示���。
數據模型的建模思路是假設數據的產生過程是已知的(或者是可以假設的)��,可以通過模型去理解整個過程��。因此��,這類模型通常具有很好的可解釋性���,分析其穩定性的數學工具也很多����,能很好地滿足上面提到的后兩點����。但是在實際生產中��,這些模型的預測效果并不好�,或者更準確地說����,單獨使用時��,預測效果并不理想���。
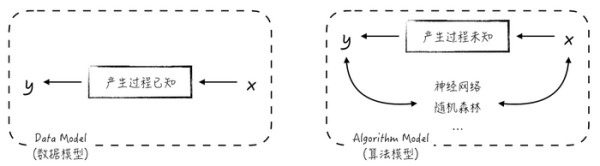
圖3
上圖算法模型����,也就是人工智能的核心內容����,它們假設數據的產生過程是復雜且未知的�。建模的目的是盡可能地從結構上“模仿”數據的產生過程���,從而達到較好的預測效果�����。但代價是模型的可解釋性很差���,而且模型穩定性的分析方法也不多���。
事實上����,統計學和機器學習在某些方面具有極好的互補性��。因此在實際的生產中�����,為了將一個數據科學項目做得盡可能完美�����,我們需要將這兩種思路結合起來使用����。比如使用機器學習的模型對數據建模�����,然后借鑒數據模型的分析工具�,分析模型的穩定性和給出模型結果的直觀解釋�。
四�、模型幻覺
雖然數據科學領域兩大門派的模型很多�����,但它們都特別依賴所使用的數據��。但是數據就百分之百可靠嗎?下面就來看兩個數據“說謊”的例子���。
如圖4所示���,我們將某APP每月的用戶注冊數表示在圖中����。圖4a給人的直觀印象是每月的安裝數是大致差不多的����,沒有明顯的增長���。而圖4b給人不同的印象��,從3月份開始�,用戶注冊數大幅度增長����。但其實兩幅圖的數據是一模一樣的��,給人不同的感覺是因為圖4a中縱軸的起點是0���,而且使用了對數尺度;而圖4b的縱軸是從17
000開始的�����,而且使用的是線性尺度��。
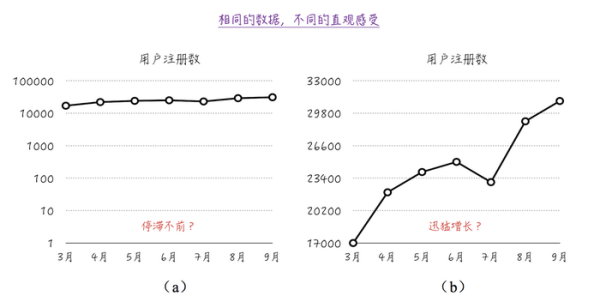
圖4
讀者可能會覺得上面這個例子太過簡單了���,只需要使用一些簡單的統計指標��,比如平均值或每個月的增長率���,就可以避免錯誤的結論���。那么下面來看一個復雜一點的例子�����。
當得到如圖所示的兩組數據時���,我們應該如何用模型去描述數據的變化規律呢?
對于圖5a����,數據的圖形有點像拋物線�����,因此選擇二次多項式擬合是一個比較合理的選擇����。于是假設模型的形式為y = (x - a)(x - b)����。然后使用數據去估計模型中的未知參數a, b���。得到的結果還不錯�,模型的預測值與真實值的差異并不大����。
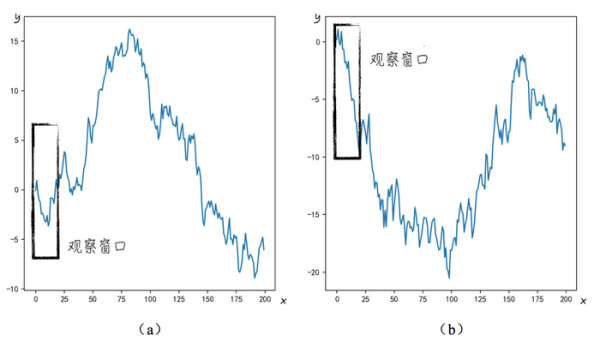
圖5
對于圖5b��,數據之間有明顯的線性關系�,所以使用線性回歸對其建模����,即y = ax + b�。與上面類似���,得到的模型結果也不錯��。
根據上面的分析結果�,可以得出如下的結論���,圖5a中的x與y之間是二次函數關系�,而圖5b的x與y之間是線性關系���。但其實兩幅圖中的變量y都是與x無關的隨機變量��,只是因為觀察窗口較小��,收集的數據樣本太少��,讓我們誤以為它們之間存在某種關系����。如果增大觀察窗口�,收集更多的數據�,則可以得到完全不同的結論�����。如圖6所示��,如果將收集的樣本數從20增加到200�����,會發現圖6a中的數據圖形更像是一個向下開口的拋物線����,這與圖5a中的結論完全相反��。而圖6b中也不再是向下的直線����,而與開口向上的拋物線更加相似�。
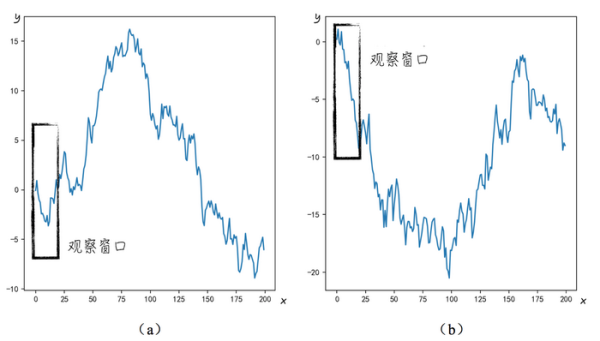
圖6
圖6上面的例子就是所謂的模型幻覺:表面上找到了數據變動的規律�����,但其實只是由隨機擾動引起的數字巧合��。因此在對搭建模型時�,必須時刻保持警惕����,不然很容易掉進數據的“陷阱”里�����,被數據給騙了���,而這正是數據科學的研究重點�����。這門學科會“小心翼翼”地處理它的各種模型�,以確保模型能擺脫數據中隨機因素的干擾�����,得到穩定且正確的結論���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
