數據科學中的陷阱:變量的數學運算合理嗎
數據科學中有各種各樣的模型����,有的聽起來很簡單��,比如線性回歸;有點呢���,聽起來就很嚇人����,比如深度學習�����。但是不管什么樣的模型����,從本質上來講���,模型都是對訓練數據做數學運算��,并以此求得模型參數的估計值��。
所以我們需要保證兩點:
第一��,訓練數據能進行數學運算;
第二�����,對變量所做的數學運算是合理的�����。
對于第一點�����,通常只在一些特定的應用場景里才需要比較復雜的處理�,比如自然語言處理��、圖像識別等�。
但對于第二點���,幾乎所有的場景都會遇到��。
這里將注重研究第二點“對變量所做的數學運算是合理的”����,它表示的內涵是:對于變量�,數字的運算有相應的實際意義�,包括以下兩個方面:
? 數字的大小關系��。
? 數字的四則運算�����。
為了更好地討論問題�,將模型的自變量分類�����。正如前面章節所提到的���,在模型里使用的變量可以分為兩類:數值型變量和類別型變量��。如圖1所示�����。
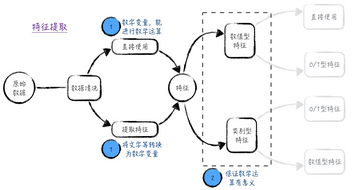
圖1
數值型變量�,在學術上也被稱為定量變量(quantitative
variable)��,如長度���、收入�����、重量等�����。它們的數值表示具體的測量或計數�����。事實上�����,定量變量按是否連續可進一步細分為連續型變量和離散型變量�。在一定區間內可以任意取值的變量叫連續型變量���,比如人的身高���、體重等;反之則是離散型變量��,比如公司員工人數等�����。對于這類變量��,數字間的不等關系是有實際意義的�����。比如對于收入�����,在數學上�����,100小于1000;在實際生活中���,100元也小于1000元���。數字間的四則運算也同理�����,這里就不贅述了����。當然由于數字的等于關系和四則運算��,數值型變量常常隱含著邊際效應恒定的假設����,正如我們在第5章里討論的那樣�。在某些場景下��,這個隱含假設與現實不符��,直接使用變量會影響模型的效果�����。
類別型變量�,也被稱為定性變量(categorical
variable)�����。它并不是表示數量上的變化���,而是表示類別���。比如性別�����、省份����、學歷�、產品等級等��。這類變量的取值通常是用文字而非數字來表示�。比如對于性別這個變量����,可能的取值為男�、女���。因此要將文字變量轉換為數字變量����,并且保證對于轉換之后的變量�,數學運算是有意義的�,這并不是一件容易的事情���。通常針對一個類別型變量���,我們會用一個數字去表示其中的一個類別���,但這樣的轉換方法并不能滿足要求:
對于有序的類別型變量���,比如產品等級����,0表示合格��、1表示良好����、2表示優秀�����。這種情況下�����,0小于1的確對應著合格等級次于良好等級����,但數字間的四則運算就沒有對應意義了�。數學上2減1等于1����,但對于產品等級���,優秀減去良好還等于良好嗎?
對于無序的類別型變量�����,比如對于省份����,0表示北京�����、1表示上海��、2表示深圳等�。數字間的大小關系和四則運算都是沒有實際意義的��。
因此�,在模型里直接使用類別型變量是沒有任何道理的��,也會嚴重影響模型的效果�。由此可見����,不管是數值型變量還是類別型變量�,通常都需要根據問題場景做相應變換后�,再放到模型中使用��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
