如何讓你的數據直覺更敏銳
每當人工智能和機器學習取得一些進展時��,這些進展一定占據著各大媒體的頭版頭條����。
媒體對其有如此高的關注度��,這意味著��,現在科技界主流的興趣領域是數據科學�����。
對于有大局意識的人來說�,這無疑是一個很好的創業機會和職業選擇����。要想抓住職業機會����,你需要超強的“碼力”和深入的專業知識�����。
然而�����,每個想在數據領域有所成就的數據科學家應該非常熟悉�����,在吸睛的神經網絡和分布式計算名詞背后是一些基本的統計實踐��。
你可以為特定的項目去學習最新的代碼框架或者閱讀該領域最新成果的科研論文��。但是���,沒有捷徑可以獲得數據科學家所需的基礎統計知識���。
所以����,只有不停地耐心練習�����,再加上一些學習過程中的挫折��,才能真正提高你的“數據直覺”���。
簡約原則
簡約原則在介紹性的統計課程中反復強調����,但英國統計學家喬治·博克斯今天說的話可能比之前更有意義:
“所有模型都錯了��,但有些模型很有用”
這句話想說明什么����?
它的意思是說:在尋求對現實世界進行系統建模時����,必須以犧牲易理解性為代價來簡化和概括�����。

現實世界紛亂嘈雜����,我們無法理解每一個細節���。因此�,統計建模并不是為了獲得完美的預測能力���,而是用最小的必要的模型來實現最大的預測能力����。
對于那些剛接觸數據世界的人來說���,這個概念看起來可能違反直覺�����。但為什么不在模型中包含盡可能多的條件項呢���?多余的條件項僅僅只能為模型增加說服力嗎�?
嗯��,是的......不可以�����。你只需關心那些會顯著增加模型解釋力的條件項��。
考慮將給定的數據集擬合不同類型的模型���。
最基本的是null模型�,它只有一個參數—響應變量的總體平均值(加上一些隨機分布的錯誤)�。
該模型假定響應變量不依賴于任何解釋變量��。相反�,它的值完全由關于整體均值的隨機波動來解釋��。這顯然限制了模型的解釋力��。
在完全相反的飽和模型中�����,每個數據點都有一個參數�����。這樣��,你會有一個完美的模型����,但是如果你試圖將新的數據用于模型��,它沒有任何解釋力���。
每個數據點包括一個特征的同時也忽略了任何有意義的簡化方式��。實際上用處并不大��。
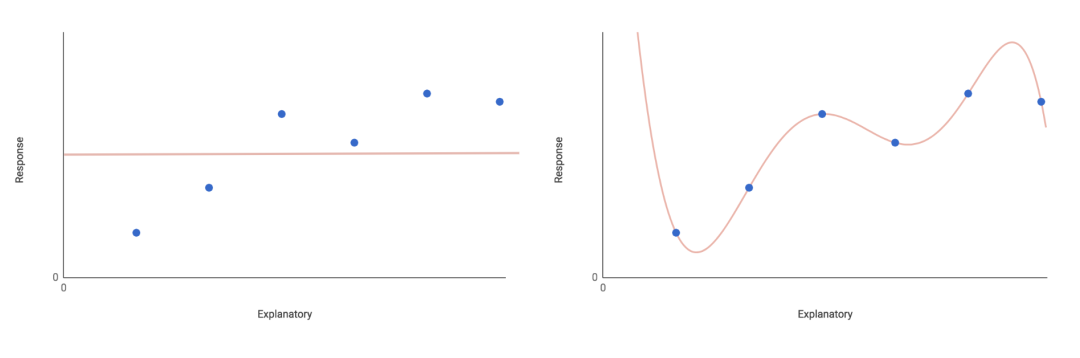
如上圖左邊是一個空模型����,右邊是一個飽和模型�。兩種模型都不會提供有力的說服力��。
顯然��,這些是極端的情況��。你應該在兩者之間尋找一個模型—一個能很好地擬合數據并具有良好解釋力的模型���。 您可以嘗試擬合最大模型��。 該模型包括所考慮的所有因素和制約條件�。
例如�����,假設您有一個響應變量y����,您希望將其作為解釋變量x 1和x 2的函數進行建模���,乘以系數β���。 最大模型看起來像這樣:
y = intercept + β?x? + β?x? + β?(x?x?) + error
這個最大模型可以很好地擬合數據����,并提供良好的解釋力�。它包括每個解釋變量項和一個交互項x?x?���。
從模型中刪除條件項將增加整體剩余偏差��,或者觀察到的預測模型未能將自身的變化考慮進來��。
但是���,并非所有條件項都一樣重要�����。 您可以刪除一個(或多個)條件項���,但并不會發現統計結果上的顯著偏差���。
這些條件項可以被認為是無關緊要的����,并從模型中刪除����。 您可以逐個刪除無關緊要的項(記住重新計算每一步的剩余偏差)���。 重復此操作���,直到所有項保持良好的統計性�。
現在你已經達到了最小的合適模型���。每一項的系數β的估計值明顯不同于0���。得出此模型的逐步消除方法稱為“逐步”回歸����。
支持這種簡化模型的哲學原理被稱為簡約原則��。
它與中世紀哲學家威廉的奧卡姆著名的啟發式奧卡姆的剃刀有一些相似之處�����。 這個原則是這樣的:“給出兩個或多個同樣可接受的現象解釋��,選擇引入假設最少的那一個�����?�!?
換句話說:你能以最簡單的方式解釋一些復雜的東西嗎���? 可以說�����,這是數據科學的決定性追求 - 有效地將復雜性轉化為可見性����。
永遠持懷疑態度

假設檢驗(如A / B檢驗)是一個重要的數據科學概念�。
簡單地說�,假設檢驗將問題轉化為兩個相互排斥的假設�,并且在哪個假設下詢問檢驗統計量的觀察值是最可能的�。當然����,檢驗統計量是從一組適當的實驗或觀察數據中計算出來的�。
當涉及到假設檢驗時��,通常會詢問你是接受還是拒絕零假設�。
通常����,你會聽到人們將零假設描述為令人失望的東西��,甚至是實驗失敗的證據��。
也許它源于如何向初學者普及假設檢驗�,但似乎許多研究人員和數據科學家對零假設有潛意識偏見���。他們試圖拒絕它�,支持所謂更令人興奮���,更有趣���,另類的假設�。
這不僅僅是一個奇聞樂事�����。目前已經有人撰寫了完整的論文去研究科學文獻中公開的學術偏見問題�。人們僅僅想知道一點:這種傾向在商業環境下有什么影響��。
然而事實是:對于任何設計合理的實驗或完整的數據集�,接受零假設應該與接受替代方案一樣有趣����。
實際上����,零假設是推論統計的基石���。它定義了我們作為數據科學家所做的工作�����,即將數據轉化為洞察力�����。如果我們沒有過多地地干涉統計結果的可能性��,那么洞察力是沒有價值的�,正是由于這個原因��,在任何時候都持懷疑態度是值得的��。
特別是考慮到“意外地”拒絕零假設(至少在天真地應用頻率論方法時)是多么容易時���,懷疑態度更是不可缺少���。
數據挖掘(或“p-hacking”)可以拋出各種無意義的結果����,但這些結果有著非常重要的統計學意義���。在無法避免多次比較的情況下���,有必要采取措施減少I型錯誤(誤報���,或者說“看不到真正存在的效果”)���。
首先���,在統計測試方面�,選擇一個本質上謹慎的測試�����。檢查是否正確滿足了測試對數據的假設����。
研究校正方法也很重要����,例如Bonferroni校正�。 然而��,這些方法有時因過于謹慎而受到批評���。 它們可能產生太多的II型錯誤(假陰性����,或者說“忽略實際存在的效應”)從而降低統計的效果�。
查找結果的“null”解釋��。 您的數據采集程序是否滿足假設條件����? 你能排除任何系統錯誤嗎���? 幸存者偏差���,自相關或趨中心回歸會有什么影響嗎��?
最后���,您發現的任何潛在關系有多可信���? 無論正確率多低�,都不要拿看起來好看的數據來糊弄�。
懷疑主義是有益的�,一般來說��,始終注意對數據的空解釋是一種好習慣��。
但要避免偏執����! 如果您已經很好地設計了實驗�����,并謹慎地分析了您的數據��,那么請將你的發現視為是真實的�����!
了解你的方法

最近技術和理論的進步為數據科學家提供了一系列強大的新工具��,用于解決十年前甚至是兩年前還無法解決的復雜問題��。
機器學習的這些進步有理由讓人萬分激動��。但是����,當將其應用于特定問題時可能存在的限制很容易被忽略��。
例如�,神經網絡在圖像分類和手寫識別方面可能非常出色�,但它絕不是解決所有問題的完美解決方案�。首先���,神經網絡很容易過擬合—即對訓練數據過度擬合��,無法推廣到新數據中�。
如神經網絡的不透明性���。神經網絡的預測能力通常以犧牲模型透明度為代價��。由于特征選擇的內化��,即使網絡進行了準確預測�����,你也不一定理解它是如何得出答案的�。
在許多業務和商業應用中��,理解“為什么和怎么做”通常是分析項目最重要的�。為了預測準確性而放棄可理解性或許是值得做出的權衡����。
同樣�����,依靠復雜機器學習算法的準確性很吸引人���,但它們絕不是百分百可靠的����。
例如����, 令人深刻的Google Cloud Vision API 也很容易被圖像中的少量噪音欺騙����。相反地����,另一篇有趣的論文展示了深度神經網絡如何“看到”那些根本不存在的圖像��。

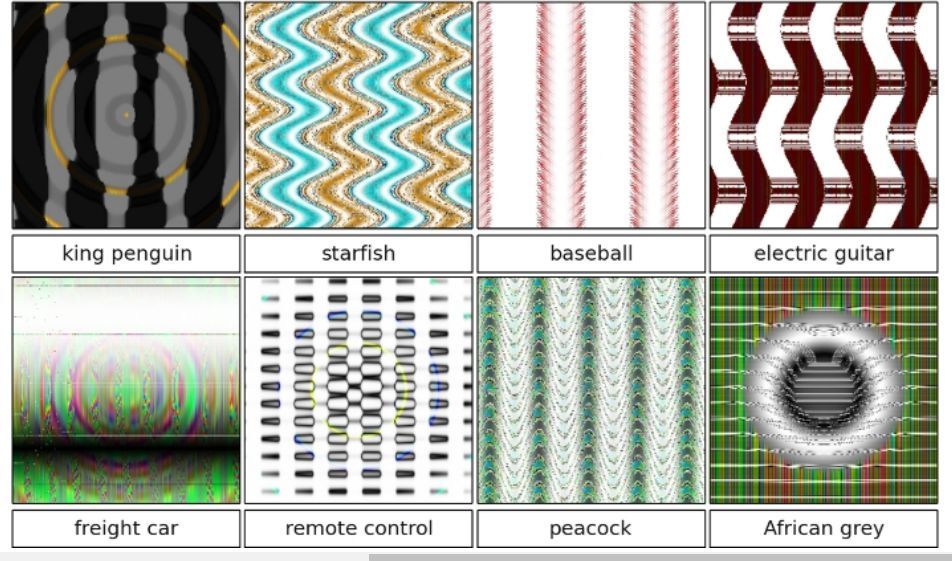
這不僅僅是需要謹慎使用的前沿機器學習方法�。
即使采用更傳統的建模方法�����,也需要注意滿足關鍵假設��。每次都注意使用到訓練數據以為的數據時���,如不懷疑也至少要謹慎使用�。每次得到的結論都需要檢驗方法是否合理���。
這并不是說根本不相信任何方法—只是要知道在任何時候為什么使用這種方法而不是另一種方法��,以及其相對利弊���。
一般地�����,如果你不能想出至少一個正考慮使用方法的缺點���,那么在進行下一步之前深入研究它�����。始終使用最簡單的工具來完成工作�����。
了解何時適合使用給定方法是否適合數據科學是一項關鍵技能���。 這是一種隨著經驗和對方法的真正理解而提高的技能���。
溝通

溝通是數據科學的精華���。不同于學校的科目�,你的目標受眾將是你研究領域中受過專業訓練的專家���,商業數據科學家的觀眾可能會成為其他領域的專家�。
如果溝通不暢�,即使是世界上最好的洞察力也沒什么價值�����。許多來自學術/研究領域有抱負的數據科學家會與技術專業的受眾進行溝通���。
然而�����,在商業環境中����,不能過分強調以一般受眾能理解和可使用的方式來解釋你的調查結果是多么重要��。
例如�����,你的調查結果可能與機構內的一系列不同的部門(從營銷���,運營到產品開發)都相關��。其中每個成員都將成為各自工作領域的專家����,并將從簡明扼要的相關調查結果的總結中受益���。
與實際結果一樣重要的是知道調查結果的局限性�。確保你的受眾了解工作流程中的任何關鍵假設�����、缺失數據或不確定程度���。
老生常談的“一張圖片勝過千言萬語”在數據科學中尤其如此�����。因此��,數據可視化工具非常重要�。
應用軟件例如Tableau��、程序庫ggplot2 for R和D3.js等都是有效表達復雜數據的好方法�,與任何技術概念一樣值得掌握��。
適當了解圖形設計原則將大大有助于讓你的圖表看起來更加專業和出彩����。
寫作一定要清晰�。生物進化已經將我們塑造成充滿潛意識偏見的和易受影響的生物����,我們固有地傾向于相信更好的展示和寫得好的資料���。
有時�����,理解概念的最好方式是互動—因此學習一些前端網絡技術來制作觀眾可以玩的交互可視化特效是值得的�。我們沒有必要重新造輪子�����,像D3.js和R's Shiny這樣的庫和工具可使任務變得更加容易���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
