對貝葉斯��、svm和神經網絡的入門級理解
在省略了不少計算�、優化的過程的情況下記錄了一些自己對一下三個算法整體思路和關鍵點的理解�,因此也只能說是“入門級理解”���。以下是目錄索引�。
貝葉斯
樸素貝葉斯
svm支持向量積
神經網絡
貝葉斯概率可以用來解決“逆概”問題��,“正向概率”問題是指比如說����,一個袋子中我們已知有2個白球���,3個黑球�,那么一次隨機摸球活動��,我們摸到黑球的概率是多少��。但是現實中我們更常見的情況是�,事先并不知道里面有多少個什么顏色的球���,只知道摸出的某一個球的顏色�����,由此來猜測的袋中球色分布��。這就是“逆概”問題��。
貝葉斯公式:P(B|A) = P(AB) / P(A)
P(B|A)后驗概率��,在已知A發生的情況下B發生的概率
P(AB)聯合概率�,兩件事一同發生的概率
P(A)A的邊緣概率����,也稱先驗概率�,求解時通過合并無關事件B的概率從而將其消去��,回顧一下概率論���,在離散函數就是求無關事件B的和��,連續函數中就是取B的積分�����。
就是在事件A發生的情況下�,B發生的概率為A���、B事件一同發生的概率與A事件單獨發生的概率的比值���。
貝葉斯公式看起來很簡單����,但是它是很有用的����。舉個輸入錯誤判斷的例子���,如果一個人輸入thew��,那么我們怎么判斷他到底是想輸入the還是thaw呢�����?
A:已近知道的情況�����,在這里是”輸入thew”
B1:猜測一�����,“想輸入的是the”
B2:猜測二���,“想輸入thaw”
顯然這里只需要比較P(AB)
但是P(AB)是什么呢����,不好理解���,我們再用一次貝葉斯P(AB)=P(B|A)*P(B) 代入��,得到P(B|A)=P(A|B)P(B)/P(A)
這里�, 關鍵就是P(B)和P(A|B)了�����。P(B)理解為這個單詞在詞庫中出現的概率�,P(A|B)為想打the卻打成thew的似然概率�。
顯然����,the的曝光率應該比thaw的高��,而第二個���,可以從thew的編輯距離來判斷���,鍵盤上��,e和w鄰近��,也就是說����,想打the�����,一不小心多敲一個w的概率非常高�,然而����,a與e的距離就遠了��,也就是說��,把thaw敲成thew的概率低一點�����。
樸素貝葉斯��,在貝葉斯定理的基礎上��,粗暴地加上一個非常簡單的假設:各屬性之間相互獨立����。舉個例子�,現在一個事物����,有很多特征n1���、n2���、n3……判斷它屬于A類還是B類或者CDF��,
假設它是A類
P(A|n1,n2,……) = P(n1, n2, ….|A)P(A) / P(n1, n2, …)
分子都是一樣的���, P(A)是該類的頻繁性(其實這里也好理解�,一般太特別的情況我們總是延遲考慮嘛)���,在樸素貝葉斯里面���,它覺得����,P(n1, n2,
..|A)
就等于P(n1|A)*P(n2|A)*P(n3|A)…..即各個屬性相互不影響�,這可是一個非常大膽的假設�����,我們都知道事物之間總是相互聯系的嘛��。
svm支持向量積
svm是建立在統計學習理論的vc維理論和結構風險最小原理基礎上的�,根據有限的樣本信息在模型復雜度和學習能力之間尋求最佳折中���。
下面來一一解釋上面這短話��。
vc維是對函數類的一種度量��,可以簡單地理解為問題的復雜程度����,vc維越高�,問題越復雜�。svm關注vc維��,也就是說svm解決問題時候也樣本維數無關���。
誤差的積累叫做風險����,分類器在樣本數據上的分類結果與真是數據的差距就是經驗風險����。經驗風險很低���,做其他數據分類是一塌糊涂的情況稱為推廣能力差���,或范化能力差��。
統計學習因此引入泛化誤差界的概念���,指真實風險應該由經驗風險和置信風險(代表我們多大程度可以信任分類器的真實分類能力)組成����。后者顯然無法真實測量���,因此只能給出一個區間��。置信風險與兩個量有關�,一是樣本數量����,量越大����,學習結果越可能正確��,二是分類函數的vc維�,此值越大����,推廣能力越差����。
泛化誤差界的公式為:R(w)≤Remp(w)+Ф(n/h)
R(w)為真實風險�,Remp(w)是經驗風險���,Ф(n/h) 是置信風險�����,統計學習的目標從經驗最小化變成了泛化風險最小化�����,也稱�����,結構風險最小����。
小樣本��,與問題的復雜度相比�,svm算法要求的樣本數量是比較少的
非線性:svm擅長樣本數據線性不可分的情況���,主要是通過松弛變量和核函數技術來實現���。
高維模式識別:可以處理樣本維數很高����。
svm從線性可分的最優分類面發展而來����,如果數據可以被一個線性模型完全正確地分開�,那么數據就是線性可分的�。
線性函數����,在一維空間是一個點��,二維空間是一條直線����,三維空間是一個平面��,如此想象寫去�,我們統稱為超平面����。
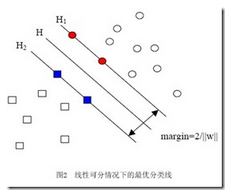
眾多的講解博客都會放類似的這個圖���,svm就是追求使所分成的類別之間能夠有最大的間距��。因此它也稱為最大邊緣分類器
svm是分類問題�,假定其分類結果�,不是1就是-1���,我們的線性方程是
g(x)=w*x+b�����。假設xi��,其類別為yi��,如果正確分類���,有w*xi+b > 0���,又yi>0�,則
yi(w*xi+b)>0�����,同樣的����,xi不屬于該類時����,正確判斷的情況下會有:
yi(w*xi+b)>0�。也就是說���,正確判斷的情況下���,yi(w*xi+b)一定大于0����,且其值越大��,表明分類效果越好(前面強調的�,svm尋求最大間距)�����。那么我們看不可以拿絕對值
|yi(w*xi+b)|
作為衡量依據呢�����?(在各種算法中����,我們總是需要尋找一個方法��,來衡量我們當前思路的準確性���,并通過對此的調整�����,以達到優化我們的函數的方法)
事實上我們還需要進一步歸一化����,在絕對值中���,如果我們同時放大w和b����,函數不會變化����,間距其實也沒有改變����,但是絕對值會變大����。因此��,我們讓w和b除以 ||w||����。得到
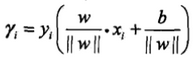
我們稱之前的這個為函數間隔:

歸一化后得到的成為幾何間隔:
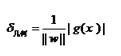
在前面那個圖中我們看到 maragin=2/||w||
小tip: ||w|| 是什么符號���?
||w||叫做向量w的范數�����,范數是對向量長度的一種度量����,我們常說的范數其實是指它的2-范數�����,范數最一般的表示形式為p-范數����,可以寫成如下表達式:
向量w=(w1, w2, w3,…wn)
它的p-范數為 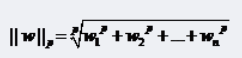
||w||與幾何間隔稱反比����,最大化幾何間隔其實也就是最小化這個 2/||w||
��,至于為什么不處理分母�����,我看了很多博客�,大抵解釋都是“我們常用的方法并不是固定||w||的大小而尋求最大幾何間隔�,而是固定間隔(例如固定為1)����,尋找最小的||w||�?!?,后來�,我在一本書上看到:
假定 b1 是類別一中離函數最近的點��,b2 屬于類別二中離線性函數最近的點��,簡言之�,這兩個點在兩個平行于決策面的超平面上
b1: w*x1+b=1
b2: w*x2 +b=-1
兩式相減���,得到 w(x1-x2)=2�,即 ||w||*d=2����,故間隔為 2 / ||w||
總之��,我們要尋找的分類面���,它必須使 2/||w|| 最小�����。之后各種最小化的方法這里就pass掉了����。�。����。����。����。這篇 有很詳細的講解�,反正每種算法的過程都總是看得我森森懷疑����,大一都干嘛去了�����,我的線代呢���?高數呢�?概率論呢�?微積分呢�����?���。�。����。��。���。
有很詳細的講解�,反正每種算法的過程都總是看得我森森懷疑����,大一都干嘛去了�����,我的線代呢���?高數呢�?概率論呢�?微積分呢�����?���。�。����。��。���。
這里寫的都只是入門的知識準備��,svm處理數據包括線性可分和線性不可分(給定一個數據集�,如果存在某個超平面能夠將它們完全正確地劃分到超平面的兩側�,則稱數據線性可分)��,當數據線性不可分時通過核函數使之可分�����,這些東西比較復雜�,有望寶寶日后深究����。���。��。���。���。���。
神經網絡
信息分為三大類:輸入信息��,隱含信息和輸出信息
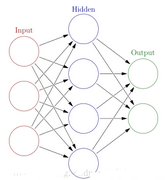
每個神經元����,通過某種特定的輸出函數�,也稱激勵函數�,計算處理來自其他相鄰神經元的加權輸入值
每個神經元之間信息傳遞的強度�����,用所謂加權值來定義����,算法會不斷自我學習���,調整這個加權值
分布式表征�����,是神經網絡研究的一個核心思想����。它的意思是���,當你表達一個概念時����,不是用單個神經元一對一地存儲�;概念與神經元是多對多的關系��,一個概念被分散在多個神經元里���,而一個神經元參與多個概念的表達�。與傳統的局部表征相比��,存儲效率高�,線性增加的神經元數目���,可以表達指數級增加的大量不同概念�。
此外���,它的另一個特點就是�,即使局部出現了故障����,信息的表達也不會受到根本性的影響�����。
根據神經元之間的互聯方式����,常見網絡結構有��,前饋神經網絡�,各神經元從輸入層開始�,接受前一層的輸入��,并輸入到下一級���,直到輸出層����。反饋神經網絡:從輸出到輸入都有反饋連接的神經網絡
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
