深度學習損失函數
在利用深度學習模型解決有監督問題時�,比如分類����、回歸�、去噪等��,我們一般的思路如下:
1���、信息流forward propagation��,直到輸出端���;
2��、定義損失函數L(x, y | theta)�����;
3��、誤差信號back propagation���。采用數學理論中的“鏈式法則”����,求L(x, y | theta)關于參數theta的梯度�����;
4����、利用最優化方法(比如隨機梯度下降法)�,進行參數更新��;
5��、重復步驟3����、4����,直到收斂為止����;
在第2步中�,我們通常會見到多種損失函數的定義方法����,常見的有均方誤差(error of mean
square)�����、最大似然誤差(maximum likelihood estimate)��、最大后驗概率(maximum posterior
probability)�、交叉熵損失函數(cross entropy
loss)�����,下面我們就來理清他們的區別和聯系���。一般地�����,一個機器學習模型選擇哪種損失函數��,是憑借經驗而定的���,沒有什么特定的標準�����。具體來說���,
(1)均方誤差是一種較早的損失函數定義方法����,它衡量的是兩個分布對應維度的差異性之和�。說點題外話�����,與之非常接近的一種相似性度量標準“余弦角”����,則衡量的是兩個分布整體的相似性�,也即把兩個向量分別作為一個整體���,計算出的夾角作為其相似性大小的判斷依據���,讀者可以認真體會這兩種相似性判斷標準的差異�;
(2)最大似然誤差是從概率的角度���,求解出能完美擬合訓練樣例的模型參數theta�,使得概率p(y | x, theta)最大化�;
(3)最大化后驗概率����,即使得概率p(theta | x,
y)最大化�,實際上也等價于帶正則化項的最大似然概率(詳細的數學推導可以參見Bishop 的Pattern Recognition And
Machine Learning)�,它考慮了先驗信息���,通過對參數值的大小進行約束來防止“過擬合”���;
(4)交叉熵損失函數�,衡量的是兩個分布p�、q的相似性���。在給定集合上兩個分布p和q的cross entropy定義如下:
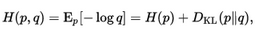
其中�����,H(p)是p的熵����,Dkl(p||q)表示KL-divergence���。對于離散化的分布p和q���,
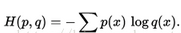
在機器學習應用中��,p一般表示樣例的標簽的真實分布��,為確定值�,故最小化交叉熵和最小化KL-devergence是等價的����,只不過之間相差了一個常數�����。
值得一提的是�����,在分類問題中��,交叉熵的本質就是似然函數的最大化�。證明如下:
記帶標簽的樣例為(x, y)���, 其中x表示輸入特征向量�����,y=[y1, y2, …, yc]表示真實標簽的one-hot表示��,y_=[y1, y2, …, yc]表示模型輸出的分布�,c表示樣例輸出的類別數����,那么��。
(1)對于二分類問題����,p(x)=[1����, 0]�,q(x)=[y1�, y2]���,y1=p(y=1|x)表示模型輸出的真實概率�����,交叉熵H(p, q)=-(1*y1+0*y2)=-y1���,顯然此時交叉熵的最小化等價于似然函數的最大化��;
(2)對于多分類問題�, 假設p(x)=[0, 0, 0, …, 1, 0, 0]���,q(x)=[y1, y2, y3, …, yk, y(k+1), y(k+2)]����,即表示真實樣例標簽為第k類���,yk=p(y=k|x)表示模型輸出為第k類的概率�,交叉熵H(p,q)=-(0*y1+0*y2+0*y3+…+1*yk+0*y(k+1)+0*y(k+2)) = -yk�, 此時同上���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
