機器學習模型設計五要素
數據可能沒什么用�����,但是數據中包含的信息有用����,能夠減少不確定性��,數據中信息量決定了算法能達到的上限�。
數據環節是整個模型搭建過程中工作量最大的地方�,從埋點����,日志上報���,清洗��,存儲到特征工程����,用戶畫像���,物品畫像���,都是些搬磚的工作也被認為最沒有含金量同時也是最重要的地方����。這塊跟要解決的問題����,所選的模型有很大關系����,需要具體問題具體分析�����,以個性化為例講講特征工程中的信息損失:
我們搭模型的目的是預測未來 -“以往鑒來�����,未卜先知 ”����,進一步要預測每個人的未來���,實時預測每個人的未來�。要想做好這件事情����,對過去��、對用戶����、對物品越了解越好�����,首先需要采集用戶的行為(什么人在什么時間什么地點以什么方式對什么東西做了什么事情做到什么程度
)�,然后進行歸因找到影響用戶點擊的因素��,構建用戶興趣圖譜�,最后在此基礎上去做預測�����。
這個過程中��,每個環節都會有信息損失����,有些是因為采集不到�����,比如用戶當時所處的環境�����,心情等等���;有些是采集得到但是暫時沒有辦法用起來�,比如電商領域用戶直接感知到是一張圖片�,點或不點很大程度上取決于這張圖片����,深度學習火之前這部分信息很難利用起來���;還有些是采集得到��,也用的起來���,但是因為加工手段造成的損失��,比如時間窗口取多久����,特征離散成幾段等等����。
起步階段�,先搞“量”再搞“率”應該是出效果最快的方式��。
#2 f(x)
f(x)的設計主要圍繞參數量和結構兩個方向做創新����,這兩個參數決定了算法的學習能力����,從數據里面挖掘信息的能力(信息利用率)�����,類比到人身上就是“天賦”��、“潛質”類的東西���,衡量這個模型有多“聰明”��。相應地���,上面的{x,y}就是你經歷了多少事情����,經歷越多+越聰明就能悟出越多的道理����。
參數量表示模型復雜度����,一般用VC維衡量����。VC維越大���,模型就越復雜�,學習能力就越強�����。在數據量比較小的時候�,高
VC 維的模型比低 VC 維的模型效果要差����,但這只是故事的一部分�;有了更多數據以后�����,就會發現低 VC 維模型效果再也漲不上去了�,但高的 VC
維模型還在不斷上升����。這時候高VC維模型可以對低VC維模型說:你考90分是因為你的實力在那里����,我考100分是因為卷面只有100分���。
當然VC維并不是越高越好�����,要和問題復雜度匹配:
-- 如果模型設計的比實際簡單����,模型表達能力不夠����,產生 high bias���;
-- 如果模型設計的比實際復雜�����,模型容易over-fit����,產生 high variance��;而且模型越復雜�,需要的樣本量越大�,DL動輒上億樣本
模型結構要解決的是把參數以哪種方式結合起來��,可以搞成“平面的”��,“立體的”��,甚至還可以加上“時間軸”����。不同的模型結構有自身獨特的性質�����,能夠捕捉到數據中不同的模式�����,我們看看三種典型的:
LR:
只能學到線性信息����,靠人工特征工程來提高非線性擬合能力
MLR:
與lr相比表達能力更強�,lr不管什么用戶什么物品全部共用一套參數��,mlr可以做到每個分片擁有自己的參數:
-- 男生跟女生行為模式不一樣�,那就訓練兩個模型�����,男生一個女生一個�����,不共享參數
-- 服裝行業跟3C行業規律不一樣�����,那就訓練兩個模型����,服裝 一個3C一個����,不共享參數
沿著這條路走到盡頭可以給每個人訓練一個模型�����,這才是真正的“個性化”���!
FM:
自動做特征交叉��,挖掘非線性信息
DL:
能夠以任意精度逼近任意連續函數���,意思就是“都在里面了����,需要啥你自己找吧”����,不想花心思做假設推公式的時候就找它�����。
#3 objective
目標函數����,做事之前先定一個小目標���,它決定了接下來我們往哪個方向走�?��?偟膩碚f���,既要好又要簡單�����;已有很多標準方法可以選����,可創新的空間不大��,不過自己搞一個損失函數聽起來也不錯�����,坐等大牛����。
-
損失函數:rmse/logloss/hinge/...
-
懲罰項:L1/L2/L21/dropout/weight decay/...
P(model|data) = P(data|model) * P(model)/P(data) —> log(d|m) + log(m)

#4 optimization
目標有了���,模型設計的足夠聰明了����,不學習或者學習方法不對��,又是一個“傷仲永”式的悲劇����。 這里要解決的問題是如何更快更好的學習���。拋開貝葉斯派的方法��,大致分為兩類:
啟發式算法����,仿達爾文進化論��,通過適應度函數進行“物競天擇����,適者生存”式優化�����,比較有代表性的:遺傳算法GA���,粒子群算法PSO�����,蟻群算法AA����;適合解決復雜�,指數規模�����,高維度���,大空間等特征問題����,如物流路經問題����;問題是比較收斂慢����,工業界很少用����。
拉馬克進化論��,獲得性遺傳�����,直接修改基因(w)����;比較有代表性的分兩類:
-- sgd variants(sgd/Nesterov/Adagrad/RMSprop/Adam/...)
-- newton variants(newton/lbfgs/...)
#5 evaluation
怎么才算一個好的模型并沒有統一標準���,一個模型部署上線或多或少的都會牽扯到多方利益�。以個性化場景為例��,就牽扯到用戶����,供應商/內容生產方以及產品運營三者的博弈�����?���?偟膩碚f���,一個“三好模型”要滿足以下三個層面:
-
算法層面:準確率�����,覆蓋率����,auc��,logloss...
-
公司層面:revenue����,ctr�����,cvr...
-
用戶層面:用戶體驗����,滿意度�,驚喜度...
#0 模型調優思路
拆解之后����,模型調優的思路也很清晰了:
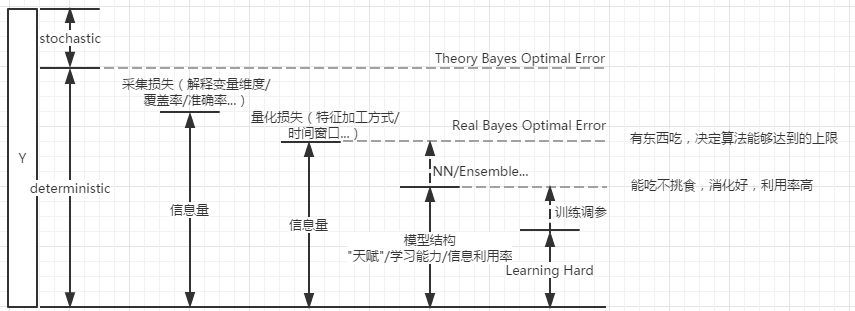
想長胖����,首先要有東西吃�����;其次要能吃�,啥都能吃不挑食���;最后消化要好
用一條公式來概括:模型效果 ∝ 數據信息量 x 算法信息利用率
-
一方面�����,擴充“信息量”�����,用戶畫像和物品畫像要做好����,把圖片/文本這類不好量化處理的數據利用起來����;
-
另一方面���,改進f(x)提高“信息利用率”��,挖到之前挖不到的規律�;
不過在大數據的初級階段��,效果主要來自于第一方面吧�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
