大數據進入企業 應如何繼承傳統的數據處理方式-CDA數據分析師
當Hadoop進入企業����,必須面對一個問題����,那就是怎樣解決和應對傳統并成熟的IT信息架構�。業內部���,如何處理原有的結構化數據是企業進入大數據領域所面對的難題�����。
當Hadoop進入企業��,必須面對一個問題�,那就是怎樣解決和應對傳統并成熟的IT信息架構�。以往MapReduce主要用來解決日志文件分析��、互聯網點擊流���、互聯網索引�、機器學習�、金融分析���、科學模擬����、影像存儲����、矩陣計算等非結構化數據���。但在企業內部���,如何處理原有的結構化數據是企業進入大數據領域所面對的難題��。企業需要既能處理非結構化數據���,又能處理結構化數據的大數據技術����。
在大數據時代�����,Hadoop主要用來處理非結構化數據���,而如何處理傳統IOE架構的結構化數據則成為企業面臨的一個難題���。在此背景下���,既能處理結構化數據又能處理非結構化數據的SQL on Hadoop應運而生��。
SQL on Hadoop是2013年最熱門的話題����,它由Cloudera Impala的發布版推到熱議����。目前��,SQL on Hadoop正處于起步階段���,其技術實踐方式很多樣����。而企業由于已經適應了在小數據上的靈活處理方式�,轉到Hadoop一下子變得無所適從,所以對SQL on Hadoop的呼聲越來越大��。SQL on Hadoop既要保證Hadoop性能�,又要保證SQL的靈活性�����。關于SQL on Hadoop�,業界有不同的看法��,業內專業大數據公司也在積極的研究��。
1.傳統方式的DB on TOP
一些北美廠商采用傳統方式的DB on TOP來解決SQL on Hadoop�,即組合利用不同的計算框架面向不同的數據操作�����。其中以EMC Greenplum����、Hadapt����、Citus Data為代表��。Hadapt以PostgreSQL架接在Hadoop上,來完成對結構化數據的查詢���。它提供了統一的數據處理環境�����,利用Hadoop的高擴展性和關系數據庫的高速性�����,分開執行Hadoop和關系數據庫之間的查詢����。Citus Data通過把多種數據類型轉化成數據庫的原生類型����,運用分布式處理技術來完成查詢��。
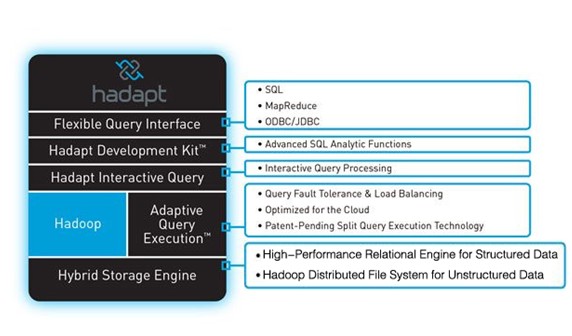
圖1���、Hadapt
DB on Top 方式是業內同事解決結構化與非結構化數據的最初嘗試�����,最早由Hadapt公司在2010年提出�����,也就緒了能夠跑在Amazon EMR上的社區版�。但是���,其本質是數據在兩種計算框架中分別存放���,如圖1所示��,結構化數據存儲于高性能關系型數據引擎(High-Performance Relational Engine for Structured Data),非結構化數據存儲于Hadoop分布文件系統(Hadoop Distributed File System for Unstructured Data)��,對兩種類型的數據交互依靠查詢的切片執行���,元數據的組織控制必然是系統擴展演變中的過度技術����。
2.原生態Hive的優化
在開源社區方面�����,以Hortonworks的Stinger�����、Apache Drill為例��。Hortonworks的Stinger通過對原生態Hive做改造�,優化SQL查詢速度�����,使其達到5-30秒��,完成對SQL查詢�����。Apache Drill通過對原生態的Hive做優化�,完成對SQL的查詢��。
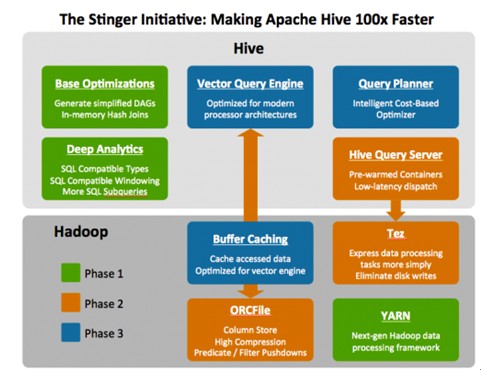
圖2�����、Hortonworks Stinger
開源社區原生態的改造��,目標是建立共同的計算框架和接口�����,目前各個開源項目雖然還只是孵化階段��,也還是獲得了業內的支持����,例如Apache的Drill項目�����,因開放的數據格式和查詢語言���,就獲得了專業的Hadoop商業發行版供應商MapR的支持��。
開源社區的發展和貢獻��,將成為推動SQL on Hadoop大規模落地行業的主要力量��。
3.人機流程交互
在國內���,對于SQL on Hadoop�,主要是從SQL的數據處理流程和即席分析兩方面來進行��。在SQL的數據處理流程方面�����,很多操作是可以通過對數據處理流程進行預定義��,然后對MapReduce作業進行批處理�����。例如ETL流程處理���。ETL流程處理是對數據進行抽取�����、清洗��、轉換����、加載的階段����。在此階段����,通過對數據流程進行預定義���,在一個人機交互的友好界面上把MapReduce作業預先組裝好�����,進行拖拽等操作形成工作流�,來解決傳統的SQL���。
4.多級索引結構的即席查詢
大數據的即席查詢是大數據所面臨的一個難題��。在PB級別的數據���,其查詢效率和查詢性能都不盡如意����。在傳統DW環境下�,企業多采用OLAP cube��。OLAP cube通過對數據進行預處理��,將數據根據維度進行最大限度的聚類運算����,通過對維度的配置�,可以完成對小數據即席分析�����。但是對于PB級別的大數據環境��,如何建立大數據的cube來兼顧前端應用的靈活性和查詢效率呢? HBase自帶的哈?����?焖俣ㄎ还δ芸梢詫崿F即席查詢的毫秒級響應和高并發����。天云大數據通過在HBase上構建多級索引以及引用MPP方式基于統計分析的分區設計�,不僅解決了HBase查詢不靈活的特點�����,還能滿足對PB級別大數據的即席查詢�。
5.操作型SQL on Hadoop
對于操作型Hadoop�,其對SQL on Hadoop 數據查詢��、響應等已經由存儲磁盤級轉移到內存上�����。由于其分布內存一致性要求����,使得其發展比較緩慢���,目前還不能達到企業應用級別����。目前�����,分布式內存計算已漸趨繁榮����,比較有代表的技術先鋒如Splice Machine��、SQLstream等�����。目前對于操作型Hadoop����,業界正在積極探索中����。
面對企業多年運營所積累的大量結構化數據����,SQL on Hadoop無疑成為了分布式計算框架進入企業傳統計算市場的敲門磚����,但我們更清楚的認識到�����,Hadoop等主流分布式計算的舞臺遠不如此�����,它為企業計算定義了一個更為廣闊的零消費市場(White Space)解決SQL之外的計算����。
紛繁復雜的世界不可能簡單地由平面展開的表結構來描述���,SQL能夠勝任查詢和數值計算工作�。但大量碎片的文字信息����、影像圖片如何計算?“買入”+“大漲”等于什么?“女性”+“Dior”等于“優雅”還是“性感”?能否用Sum�����、Group By�����、Join SQL來做非結構化信息的主題縮略�、分類���、聚類�,我們將在后續文章中探討這些話題����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
