數據分析領域中最為人稱道的七種降維方法(1)
來由于數據記錄和屬性規模的急劇增長�,大數據處理平臺和并行數據分析算法也隨之出現�。
近來由于數據記錄和屬性規模的急劇增長����,大數據處理平臺和并行數據分析算法也隨之出現���。于此同時���,這也推動了數據降維處理的應用���。實際上��,數據量有時過猶不及��。有時在數據分析應用中大量的數據反而會產生更壞的性能����。
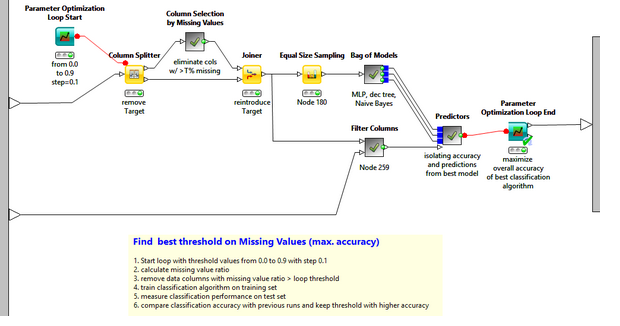
最新的一個例子是采用 2009 KDD Challenge 大數據集來預測客戶流失量��。 該數據集維度達到 15000 維���。 大多數數據挖掘算法都直接對數據逐列處理���,在數據數目一大時��,導致算法越來越慢����。該項目的最重要的就是在減少數據列數的同時保證丟失的數據信息盡可能少�����。
以該項目為例����,我們開始來探討在當前數據分析領域中最為數據分析人員稱道和接受的數據降維方法����。
缺失值比率 (Missing Values Ratio)
該方法的是基于包含太多缺失值的數據列包含有用信息的可能性較少���。因此�����,可以將數據列缺失值大于某個閾值的列去掉�。閾值越高�����,降維方法更為積極�,即降維越少�����。該方法示意圖如下:
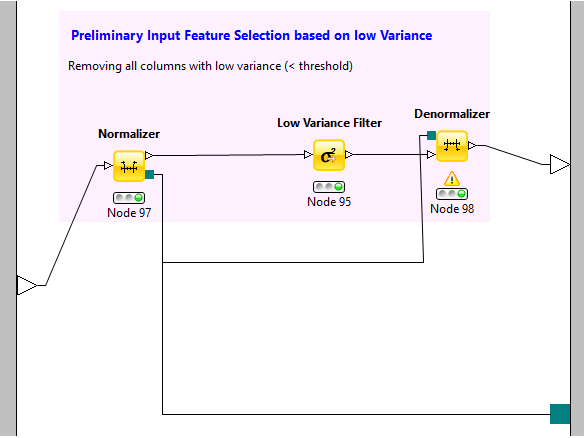
低方差濾波 (Low Variance Filter)
與上個方法相似��,該方法假設數據列變化非常小的列包含的信息量少�����。因此����,所有的數據列方差小的列被移除���。需要注意的一點是:方差與數據范圍相關的���,因此在采用該方法前需要對數據做歸一化處理�����。算法示意圖如下:
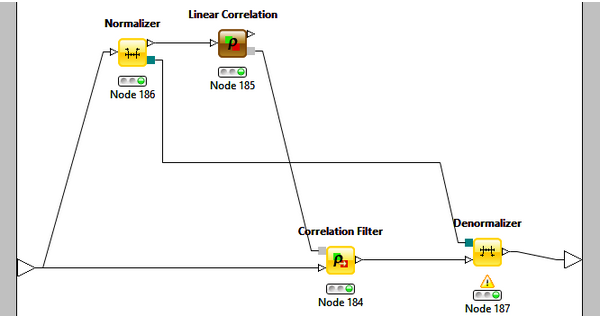
高相關濾波 (High Correlation Filter)
高相關濾波認為當兩列數據變化趨勢相似時����,它們包含的信息也顯示�。這樣��,使用相似列中的一列就可以滿足機器學習模型���。對于數值列之間的相似性通過計算相關系數來表示���,對于名詞類列的相關系數可以通過計算皮爾遜卡方值來表示�����。相關系數大于某個閾值的兩列只保留一列����。同樣要注意的是:相關系數對范圍敏感�����,所以在計算之前也需要對數據進行歸一化處理��。算法示意圖如下:
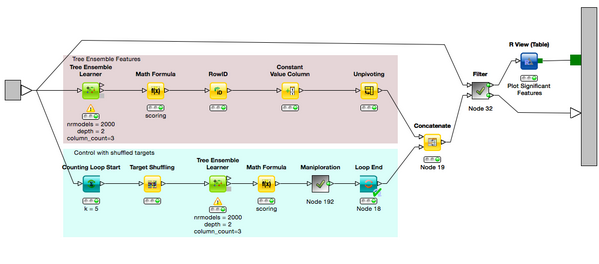
隨機森林/組合樹 (Random Forests)
組合決策樹通常又被成為隨機森林���,它在進行特征選擇與構建有效的分類器時非常有用��。一種常用的降維方法是對目標屬性產生許多巨大的樹�,然后根據對每個屬性的統計結果找到信息量最大的特征子集�����。例如��,我們能夠對一個非常巨大的數據集生成非常層次非常淺的樹����,每顆樹只訓練一小部分屬性��。如果一個屬性經常成為最佳分裂屬性���,那么它很有可能是需要保留的信息特征�����。對隨機森林數據屬性的統計評分會向我們揭示與其它屬性相比����,哪個屬性才是預測能力最好的屬性�。算法示意圖如下:
主成分分析是一個統計過程����,該過程通過正交變換將原始的 n 維數據集變換到一個新的被稱做主成分的數據集中���。變換后的結果中��,第一個主成分具有最大的方差值�,每個后續的成分在與前述主成分正交條件限制下與具有最大方差��。降維時僅保存前 m(m < n) 個主成分即可保持最大的數據信息量��。需要注意的是主成分變換對正交向量的尺度敏感���。數據在變換前需要進行歸一化處理���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
