案例:考拉FM的個性化數據挖掘和處理_數據分析師
提起FM類APP�,你都會想起哪些應用程序����?來自易觀智庫數據顯示����,2014年3月電臺類應用月度活躍人數最高的APP仍是考拉FM��。上線不到一年的考拉FM�����,為何發展如此之猛��?
與其他移動端電臺不同的是��,考拉FM采用個性化推薦音頻流的播放邏輯���,在用戶未進行主動選擇的情況下依舊能夠收聽到心儀的節目�。移動音頻娛樂與大數據挖掘的結合會是怎樣的爆發�?幾天前�����,在中國電子學會主辦的“云計算大會”上�����,考拉FM的CTO崔義超發表主題演講�,闡述考拉FM的數據挖掘和處理方法�����。小編在聽完崔義超的發言后趕腳很有價值����,為了讓咱的粉絲們也能分享到這份干貨�,小編放棄休息時間把速記文本整理成文���。

大數據在數字娛樂行業應用�����,音頻媒體特點分析
1�����、音頻伴隨性高于視頻�、文字內容:
崔義超:現在大家上網可以看圖文����、視頻�,為什么還要“聽”呢���?因為“聽”有其獨特性����,其目的是滿足用戶情感或資訊的需求����,但最重要的一點:“聽”是一種伴隨狀態����,即在做重要事情時的伴隨效應:比如開車時不能看視頻����,工作學習時不能上網閱讀文章����,唯獨音頻是可以在這些情況下進行伴隨和消費的媒介�����。
2�����、移動互聯網時代�����,音頻將成為主流
崔義超:2000年前后���,已經有先驅嘗試在互聯網上做音頻內容�,就是所謂的互聯網電臺�,比如糖蒜廣播到現在已經做了十來年��,有上百萬的粉絲���,但這些嘗試一直沒有形成網絡媒介的主流����。隨著移動互聯網時代到來�����,手機的普及��,以及今年開始的車聯網普及�����,使音頻與移動互聯網高度結合�,聲音以一種新的形式重新呈現在大家面前���,這就是我們現在做的考拉FM�。另外還有電臺匯總類APP���,比如蜻蜓FM�����,或點播聽書類APP等��。
3���、考拉FM是真正的移動電臺——源源不斷的音頻流
崔義超:考拉FM是一個什么樣的產品��?我們把它叫做個性化的手機電臺��。這是什么含義�����?首先我們是一個電臺�。傳統電臺大家可能都聽過����,電臺的特性是一個源源不斷的流���,只要不手動停止��,它就一直播下去;另外具有聲音不期而遇的特點���,聽眾可以突然聽到一段非常打動人心的聲音�,而不像聽CD�。我們做的手機電臺也想堅持這樣的特點����,給聽眾帶來不期而遇的驚喜和觸動����。
考拉FM個性化大數據挖掘和處理
1�����、考拉FM定義的個性化
崔義超:什么是個性化����?考拉FM將其定義為“每一個人聽到的都是自己愛聽的��,或至少是我不討厭的��?�!边@叫個性化�。為什么在手機電臺上需要個性化呢����?音頻的特性是伴隨���,試想一個場景:比如在家里做家務�����、做飯�,用戶打開考拉FM丟到旁邊����,讓它自動播放��。這種狀態下�,如果你聽到的不是你想聽的就需要操作����,這就失去了伴隨的意義����,所以只有你聽到是你愛聽的才會實現伴隨����,丟到旁邊不用管��。
2�����、音頻個性化體驗重在專業編排�����,仿照傳統電臺
崔義超:音頻個性化推薦����,不是考拉FM先提出來的����,之前有很多先驅做這方面的事情����。在互聯網或移動互聯網之前��,傳統電臺是怎么做的����?經常聽電臺的人可能覺得傳統電臺做得很好����,很直觀的感受��,但為什么好聽�����,怎么樣做到好聽��?聽眾可能說不出來����。其實這就是編排�����,即通過專家把節目串成音頻流����,這是一個經驗工種�����。比如一檔節目播幾分鐘的音樂�����,插一個主持人的幾句話��,然后可能插播一段廣告�����,接著每個話題聊5分鐘����、7分鐘……這些都是需要經驗的��。我們希望比照傳統電臺聽起來不累�����,可以一直聽下去���,達到伴隨的效果�����。
進入互聯網時代���,每個人聽到的內容不一樣���,不可能靠專家預先給每個人編排好節目�����。于是就需要算法�����,美國的PANDORA和豆瓣FM都做了嘗試����。對考拉FM��,與其他音頻APP最大的不同即是我們比照傳統電臺����,通過獨特的算法編排把聲音串起來��,努力讓音頻流達到既讓用戶想聽又好聽的效果��,這就是音頻個性化推薦要做的事情�。
3��、分類�、標簽等輔助推薦
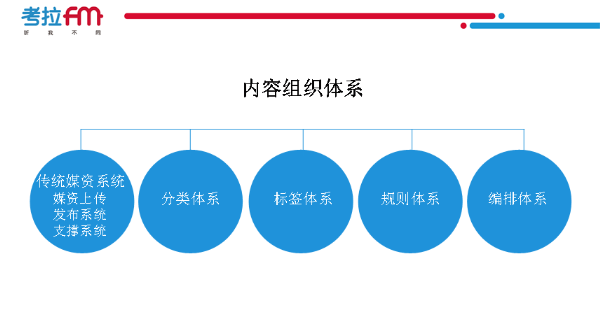
崔義超:在后臺內容組織體系里�����,為了完成個性化推薦,傳統視頻網站都建立了媒資系統���,比如上傳���、發布�、版權����、編解碼等��,但在與個性化推薦有關的獨特地方���,就需要更精確的內容分類�����,這需要有專家經驗推薦���,還有標簽體系�����。像PANDORA����,從2004年開始把每首歌打了400多個不同維度的標簽���。所以考拉FM要做到個性化推薦必須要有強大的標簽體系�,對不同維度進行管理����,建立規則體系�。
4���、建立用戶模型

崔義超:每個用戶的用戶行為非常多且復雜��,對于考拉FM就有喜歡��、不喜歡����、跳過等等�����。我們了解用戶���,可能要收集上傳很多用戶數據�����,比如地域�����、收集時間�����,瀏覽路徑����,收聽順序��、時間�,是否使用快進�����、快退等�����,所有這些數據都是具體了解用戶對節目的需求或用戶的使用場景狀況的基礎�。
上報以后��,我們用什么方式把這些數據進行存儲����?大家都很熟悉大數據用Hadoop存日志��,怎樣做到在線進行推薦����,這和存儲結構相關�。這些數據要能夠用來做推薦�����,數據清晰肯定也是很重要的���。比如測試機打開以后24小時播放���,每一個節目都不做操作�,這種數據對實際分析來說應該去掉���,因為沒有提供任何價值���。還有同樣測試時����,每個節目快速滑過��,看到底能夠出現多少節目�����,下面是什么樣的�,可能每個節目聽了都不到2秒鐘���,這種數據在做預處理時刪掉��。在拿到有效數據后�,考拉FM會分析用戶行為特征���,比如通過聚類��,看用戶到底有哪些特征�,比如聚成30多類用戶�����,有些用戶特征明顯��,早上起來就聽新聞��,放其他都滑過��;還有用戶中午就喜歡聽音樂����,放其他的都不喜歡聽���,最終建立用戶模型�。
5�、興趣圖譜分析
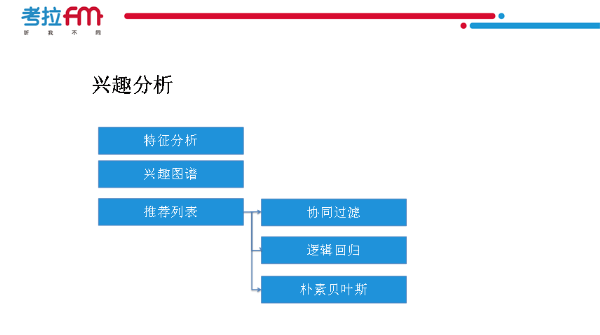
崔義超:接下來做興趣分析�����。用興趣圖譜的分析�,首先進行用戶分析��,建立興趣圖譜�,針對每個用戶建立一個推薦節目的列表���,也就是給他一個排序����,我們有幾萬期節目可能分成幾百上千檔�,每個用戶興趣點不同��,如果他非常喜歡某節目���,這檔節目的排名就靠前����,有些不喜歡的節目排名就非常低�����,甚至通過一些過濾條件把不喜歡的節目排除掉��,除了用數據做分析���,我們也可以用到數據挖掘�����,同樣類型的用戶通過使用協同過濾��、邏輯回歸���、樸素貝葉斯等方法協助生成每一個用戶節目的排名��。哪些用戶喜歡這個節目的小池子����,就放到他的喜歡池里��。
接著這些池子是不是按順序播放���?如果這樣做���,可能有些用戶喜歡�����,但每天都聽到的是固定的��,其實聽起來并不好聽���,這時候就要用到電臺獨特的編排���。我們在做考拉FM初期����,在不了解用戶時���,考拉FM先做一個普世的人工電臺播法��,比如先播昨天所有新聞掃描����,然后放國內新聞��、國際新聞�����,但實際用戶操作以后��,這個預先編排就不成立了���;比如我放體育新聞�����,一個女生對新聞完全不感興趣����,她聽到的新聞就會減少�。這種情況下�����,我們怎么樣完成編排��,就要說到一些規則���,通過規則體系逐漸形成用算法代替人工����,同時還要結合音頻獨特的時段分析�,比如很多用戶早晨喜歡聽新聞��,晚上女生可能會聽一些情感類的����,當然也有一些用戶喜歡聽鬼故事睡覺�����。
編排確定以后���,再把用戶興趣圖譜結合起來���,就知道了用戶某時段想聽情感類節目����,這類節目可能有上百檔��,再根據剛才的排名按順序給大家進行推送����。這是整個推薦的體系架構��,但實際執行中我們碰到很多技術上的難點����,比如存儲的體系���,用戶數據是海量的��,在收集了大概三四個月時間用戶數據就上了T����,這些數據如果都參加實時計算���,效率肯定非常低���,所以我們怎么樣區分活躍用戶和冷用戶����,用不同方式存起來就是個問題����?�?祭璅M的解決方案是把不常用數據用文件存起來�����,有些則用其他手段存儲結構性數據����,把不同存儲的數據抓過來進行計算���,同時計算效率�。我們把內容以及用戶數據結合起來����,選擇參與計算的數據和離線數據��。
考拉FM的大數據分析到底效果好不好��?這不是憑空決定的�����,既然都用數據說話����,就要有數據來評估效果�?��?祭璅M是不是用收聽人數增長來考慮���,這很難考量����,因為人數有很多其他因素決定�,比如推廣渠道�、節假日因素等等�。比如我做了一個算法改進之后���,用戶總收聽時長是否增加�����,或者完整收聽率����,即每一個節目是否聽了�,聽了90%���,還是聽了85%�����,可以判斷這個算法到底是不是改進了�����,或者是不是還有改進的空間�,這就是我們現在正在做的事情�。
Q:對于考拉來說����,用戶需要花多長時間進行操作學習��?
崔義超:這是好問題�����,對所有數據挖掘來說���,訓練時間都是很重要的�。但我不能籠統回答���,這個用戶只要使用了�����,可以說一直在訓練���,而且他的提升都是一直在改進����。比如完整收聽率���,可能之前完全是收聽的專家編排的節目��,這時候完整收聽率平均30%多�,現在完整收聽率達到60%�����、70%��,這是一個持續不斷改進的過程���。對于一個新用戶來說��,你用到“訓練”這個詞�,有一個最大的問題其實不是訓練�����,在用戶還沒有感受到你的個性化好處的時候��,他可能不再使用了����,所以預設的規則非常重要���。我們會對大多數人進行簡單的了解�����,然后給出預設電臺�,這個電臺聽起來至少不討厭���,然后才會參與到所謂的訓練中��。用戶使用時間越長�,推送內容越精確�����,我很難答需要多長時間�,但如果用戶一周使用兩三次�����,基本上推送精確性就有明顯提升����,使用時間越長�,效果越好���。
Q:作為一個新用戶����,能否利用我的一些社交數據�,比如微博或豆瓣閱讀之類的個人信息來提供這樣的幫助�?
崔義超:你這個問題非常好�����,這是我們去年一直在做的事情�。先講我們的思路和你的問題非常接近���,之前用戶進來以后先不讓他收聽��,希望用戶用微博登陸�����,如果用戶不用微博登陸我們有一個選項是“隨便聽聽”����,為什么用微博登陸�,因為我們有一套成熟的通過微博數據分析方法���,從而得出用戶興趣圖譜��。但現在雖然還提供微博登陸入口�����,但不是強制登陸���,因為兩點:強制登陸提高了用戶使用門檻�,導致部分用戶直接走掉了����;第二和去年大環境有關��,當時微博活躍度一直在下降�����,所以我們覺得微博這樣一個入口并不能提供很好的解決冷啟動的渠道���,所以我們后來換用其他方式��。你說的非常重要��,我們非常希望能通過社交數據的引入來部分解決冷啟動的問題��。
Q:我剛剛下載的考拉�����,因為我以前用其他的�,如果偶爾誤操作�����,比如點紅心或垃圾筒會不會影響到數據分析����?
崔義超:我們最重要參考指標是從大量的數據來得出的用戶行為模型��,這個模型肯定不是一兩次操作的數據得出的�����,但我們也會體現“快速反應”的效果����,如果用戶總是操作以后推送不給反饋����,用戶也不會愿意�。怎么樣解決兩者之間的矛盾��?考拉FM總體上的推送是通過大量數據分析給出的���,但用戶的實時操作我們亦會提供一些實時反饋�,這不影響到總體數據分析��,但會讓用戶感覺到操作是有反饋的�。
Q:您剛剛說并不是所有數據都會參加實時的計算�����,大概是多少比例會參加�?
崔義超:數據分成離線還是在線的�����,基本所有的在線數據都參加計算����,實時的是按照音頻特性��,比如新聞�,只有最近兩天的新聞的數據才參加計算�����。從用戶屬性����,我們最近一個月活躍的用戶才參與計算����,用戶兩個月前下載了聽了幾次����,大概一個半月沒來過����,他的數據我們不參與計算�,他再來了我們才參與計算�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
