文 | 譚政
來源 | 煉數成金
作者簡介
譚政����,Hulu 網大數據基礎平臺研發����。曾在新浪微博平臺工作過����。專注于大數據存儲和處理�����,對 Hadoop��、HBase 以及 Spark 等等均有深入的了解��。
Spark 最新的特性以及功能
2015 年中 Spark 版本從 1.2.1 升級到當前最新的 1.5.2�,1.6.0 版本也馬上要進行發布�����,每個版本都包含了許多的新特性以及重要的性能改進�����,我會按照時間順序列舉部分改進出來���,希望大家對 Spark 版本的演化有一個稍微直觀的認識����。
由于篇幅關系�,這次不能給大家一一講解其中每一項改進����,因此挑選了一些我認為比較重要的特性來給大家講解�。如有遺漏和錯誤�,還請幫忙指正����。
Spark 版本演化
首先還是先來看一下 Spark 對應版本的變化:
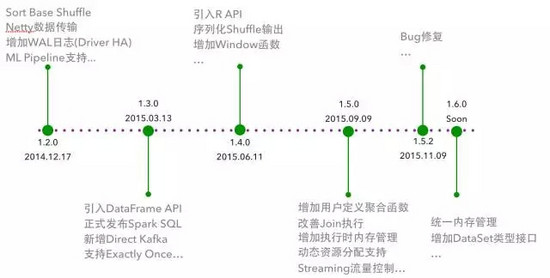
先來一個整體的介紹:1.2 版本主要集中于 Shuffle 優化�, 1.3 版本主要的貢獻是 DataFrame API�����, 1.4 版本引入 R API 并啟動 Tungsten 項目階段����,1.5 版本完成了 Tungsten 項目的第一階段���,1.6 版本將會繼續進行 Tungsten 項目的第二個階段��。而我下面則重點介紹 DataFrame API 以及 Tungsten 項目����。
DataFrame 介紹
DataFrame API 是在 1.3.0 中引入的��,其目的是為了統一 Spark 中對結構化數據的處理����。在引入 DataFrame 之前�,Spark 之有上針對結構化數據的 SQL 查詢以及 Hive 查詢���。
這些查詢的處理流程基本類似:查詢串先需要經過解析器生成邏輯查詢計劃�,然后經過優化器生成物理查詢計劃�����,最終被執行器調度執行�����。
而不同的查詢引擎有不同的優化器和執行器實現�����,并且使用了不同的中間數據結構���,這就導致很難將不同的引擎的優化合并到一起�,新增一個查詢語言也是非常艱難�。
為了解決這個問題�,Spark 對結構化數據表示進行了高層抽象���,產生了 DataFrame API��。簡單來說 DataFrame 可以看做是帶有 Schema 的 RDD(在1.3之前DataFrame 就叫做 SchemaRDD�����,受到 R 以及 Python 的啟發改為 DataFrame這個名字)�����。
在 DataFrame 上可以應用一系列的表達式�����,最終生成一個樹形的邏輯計劃����。這個邏輯計劃將會經歷 Analysis���, Logical Optimization��, Physical Planning 以及 Code Generation 階段最終變成可執行的 RDD���,如下圖所示:
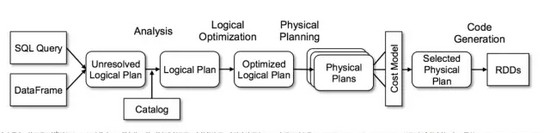
在上圖中���,除了最開始解析 SQL/HQL 查詢串不一樣之外�,剩下的部分都是同一套執行流程�,在這套流程上 Spark 實現了對上層 Spark SQL�����, Hive SQL��, DataFrame 以及 R 語言的支持�。
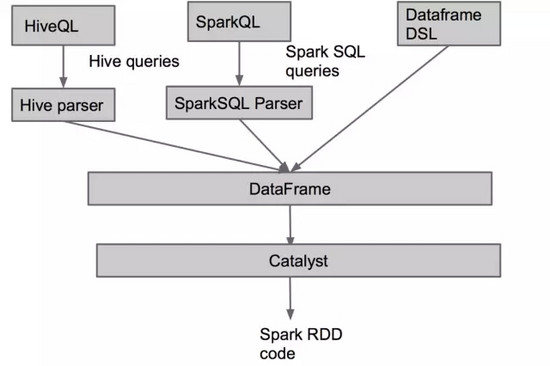
下面我們來看看這些語言的簡單示例:
Spark SQL : val count = sqlContext.sql("SELECT COUNT(*) FROM records").collect().head.getLong(0)



各個語言的使用方式都很類似�����。除了類 SQL 的表達式操作之外�����,DataFrame 也提供普通的類似于 RDD 的轉換����,例如可以寫如下代碼:

另外還值得一提的是����,和 DataFrame API 緊密相關的 API -- DataSource API�。如果說 DataFrame API 提供的是對結構化數據的高層抽象�����,那么 DataSource API 提供的則是對于結構化數據統一的讀寫接口�。
DataSource API 支持從 JSON���, JDBC�����, ORC�, parquet 中加載結構化數據 (SQLContext 類中的諸多讀取方法���,均會返回一個 DataFrame 對象)��,也同時支持將 DataFrame 的數據寫入到上述數據源中 (DataFrame 中的 save 系列方法 )�����。
這兩個 API 再加上層多種語言的支持���,使得 Spark 對結構化數據擁有強大的處理能力����,極大簡化了用戶編程工作��。
Tungsten 項目介紹
在官方介紹中 Tungsten 將會是對 Spark 執行引擎所做的最大的修改��,其主要目標是改進 Spark 內存和 CPU 的使用效率��,盡可能發揮出機器硬件的最大性能���。
之所以將優化的重點集中在內存和 CPU 而不是 IO 之上是社區實踐發現現在很多的大數據應用的瓶頸在 CPU ����。例如目前很多網絡 IO 鏈路的速度達到 10Gbps�,SSD 硬盤和 Striped HDD 陣列的使用也使得磁盤 IO 也有較大提升����。而 CPU 的主頻卻沒有多少提升����,CPU 核數的增長也不如前兩者迅速��。
此外在 Spark 已經對 IO 做過很多的優化(如列存儲以及 IO 剪枝可以減少 IO的數據量���,優化的 Shuffle 改善了 IO 和網絡的傳輸效率)���,再繼續進行優化提升空間并不大���。
而隨著序列化以及 Hash 的廣泛使用�,現在 CPU 反而成為了一個瓶頸�。
內存方面����,使用 Java 原生的堆內存管理方式很容易產生 OOM 問題���,并伴隨著較大的 GC 負擔�����,進一步降低了 CPU 的利用率���。
基于上述觀察 Spark 在 1.4 中啟動了 Tungsten 項目�,并在 1.5 中完成第一階段的優化
這些優化包括下面三個方面:
內存管理和二進制格式處理
緩存友好的計算
代碼生成
內存管理和二進制格式處理
避免以原生格式存儲 Java 對象(使用二進制的存儲格式)��,減少 GC 負擔
壓縮內存數據格式�,減少內存占用以及可能的溢寫���。使用更準確的內存的統計而不是依賴啟發規則管理內存���。
對于那些已知數據格式運算( DataFrame 和 SQL )����,直接使用二進制的運算����,避免序列化和反序列化開銷����。
緩存友好的計算
更加快的排序以及 Hash����,優化 Aggregation���, Join 以及 Shuffle 操作����。
代碼生成
更快的表達式計算以及 DataFrame/SQL 運算(這是代碼生成的主要應用場景��,主要是為了降低進行表達式評估中 JVM 的各種開銷�����,如虛函數調用��,分支預測�,原始類型的對象裝箱開銷以及內存消耗)更快的序列化�����。
相關的每個版本所做的優化如下:
Tungsten 項目并不是完全是一個通用的優化技術�,其中很多優化利用了 DataFrame 模型所提供的豐富的語義信息(因此 DataFrame 和 Spark SQL 查詢能夠享受該項目所來的大量的好處)���,同樣未來也會改進 RDD API 來為底層優化提供更多的信息支持����。
Spark 在 Hulu 的實踐
Hulu 是一家在線付費視頻網站�����,每天都有大量的用戶觀看行為數據產生���,這些數據會由 Hulu 的大數據平臺進行存儲以及處理��。推薦團隊需要從這些數據中挖掘出單個用戶感興趣的內容并推薦給對應的觀眾�,廣告團隊需要根據用戶的觀看記錄以及行為給其推薦的最合適廣告�,而數據團隊則需要分析所有數據的各個維度并為公司的策略制定提供有效支持����。
他們的所有工作都是在 Hulu 的大數據平臺上完成的����,該平臺由 HDFS/Yarn��, HBase�, Hive�, Cassandera 以及的 Presto���,Spark 等組成����。Spark 是運行在 Yarn上���,由 Yarn 來管理資源并進行任務調度����。
Spark 則主要有兩類應用:Streaming 應用以及短時 Job����。
Streaming 應用中各個設備前端將用戶的行為日志輸入到 Kafka 中��,然后由 Spark Streaming 來進行處理�����,輸出結果到 Cassandera���, HBase 以及 HDFS 中����。短時 Job 并不像 Streaming 應用一樣一直運行���,而是由用戶或者定時腳本觸發����,一般運行時間從幾分鐘到十幾個小時不等��。
此外為了方便 PM 類型的用戶更便捷的使用 Spark�,我們也搭建了 Apache Zeppelin 這種交互式可視化執行環境�����。對于非 Python/Scala/Java/R 用戶(例如某些用戶想在 NodeJS 中提交 Spark 任務)�,我們也提供 REST 的 Spark-JobServer 來方便用戶提交作業����。
Hulu 從 0.9 版本就開始將 Spark 應用于線上作業���,內部經歷了 1.1.1�����, 1.2.0�, 1.4.0 等諸多版本�,目前內部使用的最新版本是基于社區 1.5.1 進行改造的����。
在之前的版本中我們遇到的很多的問題也添加了不少新功能�����,大部分修改都已經包含在最新版本里面���,我就不再這里贅述了�。這節里我主要想講的是社區里所沒有的��,但是我們認為還比較重要的一些修改����。
較多的迭代觸發 StackOverflow 的問題
在某些機器學習算法里面需要進行比較多輪的迭代���,當迭代的次數超過一定次數時候應用程序就會發生 StackOverflow 而崩潰�。這個次數限制并不會很大�����,幾百次迭代就可能發生棧溢出���。大家可以利用一小段代碼來進行一個簡單的測試:

產生上述錯誤的原因在于 Driver 將 RDD 任務發送給 Executor 執行的時候需要將 RDD 的信息序列化后廣播到對應的 Executor 上�。而 RDD 在序列的時候需要遞歸將其依賴的 RDD 序列化�,這樣在出現長 lineage 的 RDD 的時候就可能因為線程的棧幀內存不夠�,拋出 StackOverflow 異常����。
解決方法也比較直接����,就是將遞歸改為迭代����,把原來需要遞歸保存在線程棧幀的序列化 RDD 挪到堆區進行保存��。具體的做法是將 RDD 的依賴關系分離出來���,變成兩個映射表: rddId->List of depId 以及depId -> Dependency���。Driver 端然后將 RDD 以及這些映射序列化為字節數組廣播出去��,Executor 端接收到廣播消息后重新將映射組裝成為原始的依賴���。
這個過程中要改動 RDD 核心 Task 接口�,需要經過嚴格的測試�����。但是在做這種優化之后����,迭代個一兩千次都沒有什么問題���。
Streaming 延遲數據接收機制( Receive-Base )
在 Receive-Base 的 Spark Streaming 的架構中�����, 主要有兩個角色 Driver 和 Executor��。
在 Executor 中運行著 Receiver���, Receiver 的主要作用是從外部接收數據并緩存到本地內存中��,同時 Receiver 回向 Driver 匯報自己所接收的數據塊��,Driver 定期產生新的任務并分發到各個 Executor 去處理這些數據����。
在應用啟動的時候�,Driver 會首先將 Receiver 處理程序調度到各個 Executor 上讓其初始化��。一旦 Receiver 初始化完畢���,它就開始源源不斷的接收數據�,并且需要 Driver 定期調度任務來消耗這些數據�����。
但是在某些場景下�, Executor 處理端還并沒有準備好��,無法開始處理數據���。
這時候在 Receiver 端就會發生內存積壓���,隨著積壓的數據越來越多�����,大部分數據都會撐過新生代回收年齡進入老年代���,進一步給 GC 帶來嚴重的壓力���,這個時候也就離應用程序崩潰不遠了���。
在 Hulu 的 Spark Streaming 處理中���,需要加載并初始化很多機器學習的模型��,這些模型的初始化非常費時間�����,長的可能需要半個小時才能初始化完畢����。在此期間 Receiver 不能接收數據����,否者內存將會被消耗殆盡��。
Hulu 中的解決方法是在每個 Executor 接收任何任務之前先進行執行一個用戶定義的初始化任務��,初始化任務中可以執行一些獨立的用戶代碼��。我們在新增了一個接口����,讓用戶可以設置自定義的初始化任務��。
如下代碼所示:
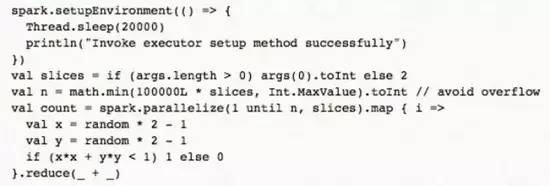
實現上需要更改 Spark 的任務調度器��,先將每個 Executor 設置為未初始化狀態���,除了初始化任務之外調度器不會給未初始化狀態的 Executor 分配其他任務��。等 Executor 運行完初始化任務���,調度器更新 Executor 的狀態為已初始化��,這樣的 Executor 就可以分配給其他正常任務了�����,包括初始化 Receiver 的任務���。
其他注意事項
Spark 允許用戶設置 spark.executor.userClassPathFirst���,這可以部分緩解用戶代碼庫和 Spark 系統代碼庫沖突的問題�。
但是在實踐過程中我們發現�����,大并發情況加載相同的類有可能發生死鎖的情況(我們的一個場景下有 1/10 幾率復現該問題)����。
其問題在于 Spark 所新增加的 ChildFirstURLClassLoader 的實現引入了并發死鎖的問題�。
Java 7 中的 ClassLoader 本身提供細粒度的類加載并發鎖���,可以做到為每個 classname 設置一個鎖�,但是使用該細粒度的類加載鎖有一個條件����,用戶自己實現的 ClassLoader 必須在自身靜態初始化方法中將自己注冊到 ClassLoader 中���。
然而在 Scala 語言中并沒有類的靜態初始化方法�,只有一個伴生對象的初始化方法��。但是伴生對象和類對象的類型并不完全一致�。
因此 Scala 在 ChildFirstURLClassLoader 中模仿 Java 的 ClassLoader 實現了自己的細粒度的類加載鎖����,然而這段代碼卻無法達到預期目的���,最終還是會降級到 ClassLoader 級別的鎖���,并且在某些場景下還會觸發死鎖�����,解決方法是去除對應的細粒度鎖代碼���。
Spark 未來的發展趨勢
Spark 1.6 即將發布�����,其中最重要的特性有兩個 [SPARK-10000] 統一內存管理以及 [SPARK-9999] DataSet API���。當然還有很多其他的改進����,由于篇幅關系�,下面主要介紹上兩個���。
統一內存管理
在 1.5 以及之前存在兩個獨立的內存管理:執行時內存管理以及存儲內存管理�����,前者是在對 Shuffle�����, Join��, Sort��, Aggregation 等計算的時候所用到的內存��,后者是緩存以及廣播變量時用的內存���。
可以通過 spark.storage.memoryFraction 來指定兩部分的大小���,默認存儲占據 60% 的堆內存��。這種方式分配的內存都是靜態的��,需要手動調優以避免 spill�����,且沒有一個合理的默認值可以覆蓋到所有的應用場景���。
在 1.6 中這兩個部分內存管理被統一起來了���,當執行時內存超過給自己分配的大小時可以臨時向存儲時內存借用空間��,臨時借用的內存可以在任何時候被回收�����,反之亦然�����。更進一步可以設置存儲內存的最低量���,系統保證這部分量不會被剔除��。
DataSet API
RDD API 存儲的是原始的 JVM 對象��,提供豐富的函數式運算符��,使用起來很靈活�����,但是由于缺乏類型信息很難對它的執行過程優化��。DataFrame API 存儲的是 Row 對象�����,提供了基于表達式的運算以及邏輯查詢計劃����,很方便做優化�,并且執行起來速度很快�,但是卻不如 RDD API 靈活�。
DataSet API 則充分結合了二者的優勢�����,既允許用戶很方便的操作領域對象又擁有 SQL 執行引擎的高性能表現�。
本質上來說 DataSet API 相當于 RDD + Encoder���, Encoder 可以將原始的 JVM對象高效的轉化為二進制格式���,使得可以后續對其進行更多的處理��。目前是實現為 Catalyst 的邏輯計劃����,這樣就能夠充分利用現有的 Tungsten 的優化成果���。
DataSet API 需要達到如下幾點目標:
快速:Encoder 需要至少和現有的 Kryo 或者 Java 序列一樣快����。
類型安全:在操作這些對象的時候需要盡可能提供編譯時的類型安全�����,如果編譯期無法知曉類型�����,在發生 Schema 不匹配的時候需要快速失敗��。
對象模型支持:默認需要提供原子類型��,case 類����,tuple�����, POJOs����, JavaBeans 的 Encoder��。
Java 兼容性:需要提供一個簡單的 API 來兼容 Scala 和 Java����,盡可能使用這些 API�,如果實在不能使用這些API也需要提供重載的版本��。
DataFrame 的互操作:用戶需要能夠無縫的在 DataSet API 和 DataFrame API之間做轉換���。
目前 DataSet API 和 DataFrame API 還是獨立的兩個 API��,未來 DataFrame 有可能繼承自 DataSet[Row]�。
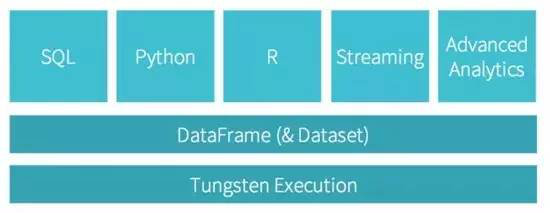
最后再來看一下整體的架構:
Q & A
1����、在 hulu��, streaming 跑在多少個節點上�����?Zeppelin 和 sparknotebook.io 各有什么優劣�����、是如何選型的����?
hulu 的 Spark Streaming 運行在 YARN 上�����,規模是幾百個節點��。我們當前主要用的是 Zeppelin���,sparknotebook.ion 目前還沒有試用
2���、我們用的是 hive on spark 模式��,因為 hive 是統一入口��,上面已經有 mr 和 tez����,請問對比 spark sql 各自優缺點�����?還有就到對比一下 spark shuffle 和 yarn自帶 shuffle(on yarn 模式)的優缺點��?
底層的存儲引擎不一樣��,相比于性能方面 spark 和 tez 不相上下�,但是穩定性方面 spark 更勝一籌�。spark shuffle 提供了三種實現���,分別是 hash-based�����,sort-based 和 tungsten-sort����, 而 mapreduce shuffle 知識 sort-based����,在靈活度上���,spark 更高����,且個別之處����,spark 有深度優化�����。
3��、能否簡單說說 spark 在圖片計算方面的應用���?
是指圖像處理方面嗎�����,這方面 Spark 并沒有專門的組件來處理���。圖片方面的應用比較少��,至少在 hulu 沒有�����。
4�、Tungsten 項目目前成熟嗎�?或者說貴司有線上應用沒�����?
Tungsten 項目還處于開發階段(階段二)�,不建議在線上使用����。
5�����、請問使用 Spark streaming 在 YARN 上和其他任務共同運行����,穩定性如何�?YARN 有沒有做 CPU 級別的隔離����?我們在 YARN 上運行的任務��,運行幾天就會掛掉����,通常都是 OOM��,但是從程序看�����,并沒有使用過多內存���。
如果 YARN 上還會混合運行 mapreduce 和 tez 等應用����,則會對 Spark streaming 存在資源競爭�����,造成性能不穩定�����,可以使用 label-based scheduling 對一些節點打標簽�,專門運行 Spark streaming����?��?傮w上說�����,spark streaming 在 YARN 上運行比較穩定�。YARN 對 CPU 有隔離�����,使用的 cgroups��。 如果是 OOM 掛掉�����,可能程序存在內存泄露���,不知道你們用的什么版本��,建議使用 jprofile 定位一下內存效率之處���。
6���、能否簡單對比下 Storm 和 Spark 的優劣�����?如何技術選型����?
Storm 是實時流式數據處理���,面向行處理����,單條延時比較低���。Spark 是近實時流式處理�,面向 vp 處理��,吞吐量比較高���。如果應用對實時性要求比較高建議試用 Storm��, 否則大家可以考慮利用 Spark 的豐富的數據操作能力���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
