美團是怎么通過優化搜索排序提高轉化率的
現在的人們對購物不在局限于實體店了���,更多的會選擇網上商城����,面對這樣一個巨大的蛋糕�,誰都想去分一杯羹�����,但是���,對于一些網店來說�����,沒有專業的數據分析團隊的幫助����,很難從中脫穎而出���。
美團的愿景是連接消費者和商家����,而搜索在其中起著非常重要的作用����。隨著業務的發展���,美團的商家和團購數正在飛速增長��。這一背景下���,搜索排序的重要性顯得更加突出:排序的優化能幫助用戶更便捷地找到滿足其需求的商家和團購����,改進用戶體驗����,提升轉化效果���。
和傳統網頁搜索問題相比��,美團的搜索排序有自身的特點——90%的交易發生在移動端��。一方面��,這對排序的個性化提出了更高的要求��,例如在“火鍋”查
詢下��,北京五道口的火鍋店A����,對在五道口的用戶U1來說是好的結果�����,對在望京的用戶U2來講不一定是好的結果;另一方面���,我們由此積累了用戶在客戶端上豐
富準確的行為����,經分析獲得用戶的地理位置�、品類和價格等偏好��,進而指導個性化排序���。
針對美團的O2O業務特點��,我們實現了一套搜索排序技術方案�����,相比規則排序有百分之幾十的提升�?�;谶@一方案��,我們又抽象了一套通用的O2O排序解
決方案�,只需1-2天就可以快速地部署到其他產品和子行業中��,目前在熱詞�����、Suggestion�、酒店���、KTV等多個產品和子行業中應用���。
我們將按線上和線下兩部分分別介紹這一通用O2O排序解決方案���,本文是線上篇�,主要介紹在線服務框架���、特征加載��、在線預估等模塊�����,下篇將會著重介紹離線流程�����。
排序系統
為了快速有效的進行搜索算法的迭代�,排序系統設計上支持靈活的A/B測試�����,滿足準確效果追蹤的需求�。

美團搜索排序系統如上圖所示���,主要包括離線數據處理�、線上服務和在線數據處理三個模塊�����。
離線數據處理
HDFS/Hive上存儲了搜索展示�、點擊��、下單和支付等日志�����。離線數據流程按天調度多個Map Reduce任務分析日志���,相關任務包括:
離線特征挖掘
產出Deal(團購單)/POI(商家)�����、用戶和Query等維度的特征供排序模型使用�。
數據清洗標注 & 模型訓練
數據清洗去掉爬蟲�、作弊等引入的臟數據;清洗完的數據經過標注后用作模型訓練�。
效果報表生成
統計生成算法效果指標�����,指導排序改進�。
特征監控
特征作為排序模型的輸入是排序系統的基礎�����。特征的錯誤異常變動會直接影響排序的效果��。特征監控主要監控特征覆蓋率和取值分布��,幫我們及時發現相關問題�。
在線數據處理
和離線流程相對應�����,在線流程通過Storm/Spark Streaming等工具對實時日志流進行分析處理�,產出實時特征����、實時報表和監控數據�����,更新在線排序模型����。
在線服務(Rank Service)
Rank Service接到搜索請求后����,會調用召回服務獲取候選POI/Deal集合�,根據A/B測試配置為用戶分配排序策略/模型����,應用策略/模型對候選集合進行排序��。
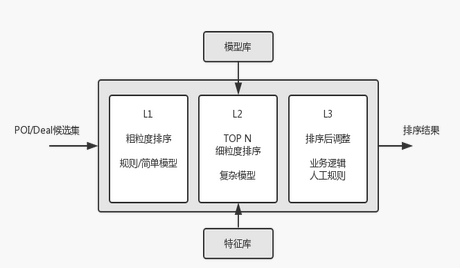
下圖是Rank Service內部的排序流程���。
L1 粗粒度排序(快速)
使用較少的特征���、簡單的模型或規則對候選集進行粗粒度排序���。
L2 細粒度排序(較慢)
對L1排序結果的前N個進行細粒度排序��。這一層會從特征庫加載特征(通過FeatureLoader)�����,應用模型(A/B測試配置分配)進行排序�����。
L3 業務規則干預
在L2排序的基礎上���,應用業務規則/人工干預對排序進行適當調整�����。
Rank Service會將展示日志記錄到日志收集系統�����,供在線/離線處理��。
A/B測試
A/B測試的流量切分是在Rank Server端完成的�����。我們根據UUID(用戶標識)將流量切分為多個桶(Bucket)�����,每個桶對應一種排序策略�����,桶內流量將使用相應的策略進行排序�����。使用UUID進行流量切分����,是為了保證用戶體驗的一致性���。
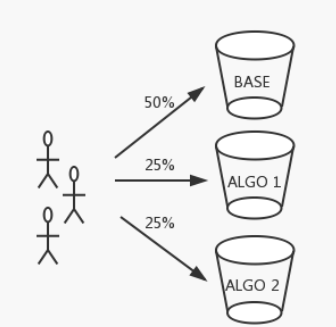
下面是A/B測試配置的一個簡單示例����。

對于不合法的UUID��,每次請求會隨機分配一個桶�,以保證效果對比不受影響�。白名單(White List)機制能保證配置用戶使用給定的策略����,以輔助相關的測試�。
除了A/B測試之外�����,我們還應用了Interleaving[7]方法�����,用于比較兩種排序算法�����。相較于A/B測試�����,Interleaving方法對
排序算法更靈敏[9]����,能通過更少的樣本來比較兩種排序算法之間的優劣�。Interleaving方法使用較小流量幫助我們快速淘汰較差算法�,提高策略迭
代效率���。
特征加載
搜索排序服務涉及多種類型的特征��,特征獲取和計算是Rank
Service響應速度的瓶頸����。我們設計了FeatureLoader模塊�,根據特征依賴關系�����,并行地獲取和計算特征��,有效地減少了特征加載時間���。實際業
務中���,并行特征加載平均響應時間比串行特征加載快約20毫秒��。
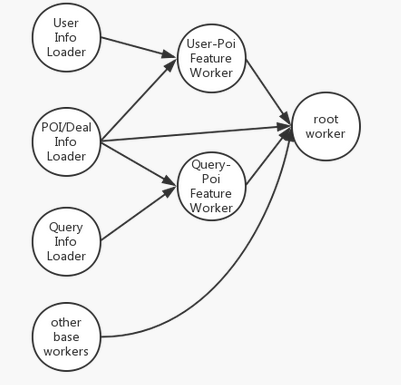
FeatureLoader的實現中我們使用了Akka[8]����。如上圖所示����,特征獲取和計算的被抽象和封裝為了若干個Akka actor����,由Akka調度��、并行執行�����。
特征和模型
美團從2013年9月開始在搜索排序上應用機器學習方法(Learning to
Rank[1])����,并且取得很大的收益�����。這得益于準確的數據標注:用戶的點擊下單支付等行為能有效地反映其偏好��。通過在特征挖掘和模型優化兩方面的工作�,
我們不斷地優化搜索排序�。下面將介紹我們在特征使用����、數據標注�����、排序算法��、Position Bias處理和冷啟動問題緩解等方面的工作��。
特征
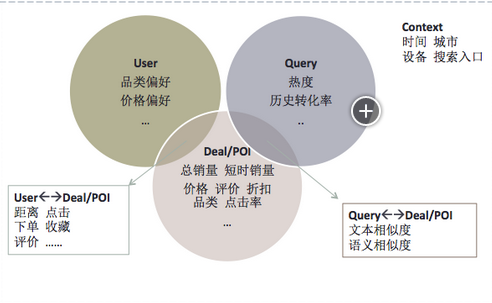
從美團業務出發����,特征選取著眼于用戶�����、Query�����、Deal/POI和搜索上下文四個維度��。
用戶維度
包括挖掘得到的品類偏好�、消費水平和地理位置等�����。
Query維度
包括Query長度����、歷史點擊率�����、轉化率和類型(商家詞/品類詞/地標詞)等��。
Deal/POI維度
包括Deal/POI銷量�、價格��、評價���、折扣率����、品類和歷史轉化率等����。
上下文維度
包括時間�、搜索入口等�����。
此外�,有的特征來自于幾個維度之間的相互關系:用戶對Deal/POI的點擊和下單等行為�、用戶與POI的距離等是決定排序的重要因素;Query和Deal/POI的文本相關性和語義相關性是模型的關鍵特征���。
模型
Learning to
Rank應用中����,我們主要采用了Pointwise方法����。采用用戶的點擊����、下單和支付等行為來進行正樣本的標注�����。從統計上看���,點擊�、下單和支付等行為分別
對應了該樣本對用戶需求的不同的匹配程度�����,因此對應的樣本會被當做正樣本��,且賦予不斷增大的權重����。
線上運行著多種不同類型模型�����,主要包括:
Gradient boosting decision/regression tree(GBDT/GBRT)[2]
GBDT是LTR中應用較多的非線性模型�����。我們開發了基于Spark的GBDT工具���,樹擬合梯度的時候運用了并行方法���,縮短訓練時間��。GBDT的樹被設計為三叉樹����,作為一種處理特征缺失的方法����。
選擇不同的損失函數�����,boosting tree方法可以處理回歸問題和分類問題����。應用中��,我們選用了效果更好的logistic likelihood loss�,將問題建模為二分類問題����。
Logistic Regression(LR)
參考Facebook的paper[3]���,我們利用GBDT進行部分LR特征的構建����。用FTRL[4]算法來在線訓練LR模型�。
對模型的評估分為離線和線上兩部分����。離線部分我們通過AUC(Area Under the ROC Curve)和MAP(Mean Average Precision)來評價模型���,線上則通過A/B測試來檢驗模型的實際效果���,兩項手段支撐著算法不斷的迭代優化��。
冷啟動
在我們的搜索排序系統中���,冷啟動問題[6]
表現為當新的商家��、新的團購單錄入或新的用戶使用美團時���,我們沒有足夠的數據用來推測用戶對產品的喜好����。商家冷啟動是主要問題�����,我們通過兩方面手段來進行
緩解���。一方面��,在模型中引入了文本相關性�、品類相似度���、距離和品類屬性等特征��,確保在沒有足夠展示和反饋的前提下能較為準確地預測;另一方面�����,我們引入了
Explore&Exploit機制����,對新商家和團單給予適度的曝光機會����,以收集反饋數據并改善預測��。
Position Bias
在手機端���,搜索結果的展現形式是列表頁���,結果的展示位置會對用戶行為產生很大的影響���。在特征挖掘和訓練數據標注當中��,我們考慮了展示位置因素引入的
偏差�����。例如CTR(click-through-rate)的統計中��,我們基于Examination Model[5]�����,去除展示位置帶來的影響���。
總結
本文主要介紹了美團搜索排序系統線上部分的結構���、算法和主要模塊����。在后續文章里�����,我們會著重介紹排序系統離線部分的工作��。
一個完善的線上線下系統是排序優化得以持續進行的基礎���?�;跇I務對數據和模型上的不斷挖掘是排序持續改善的動力���。我們仍在探索��。
參考文獻
Learning To Rank. Wikipedia
Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, 1189-1232.
He, X., Pan, J., Jin, O., Xu, T., Liu, B., Xu, T., ... & Candela,
J. Q. (2014, August). Practical lessons from predicting clicks on ads
at facebook. In Proceedings of 20th ACM SIGKDD Conference on Knowledge
Discovery and Data Mining (pp. 1-9). ACM.
McMahan, H. B., Holt, G., Sculley, D., Young, M., Ebner, D., Grady,
J., ... & Kubica, J. (2013, August). Ad click prediction: a view
from the trenches. In Proceedings of the 19th ACM SIGKDD international
conference on Knowledge discovery and data mining (pp. 1222-1230). ACM.
Craswell, N., Zoeter, O., Taylor, M., & Ramsey, B. (2008,
February). An experimental comparison of click position-bias models. In
Proceedings of the 2008 International Conference on Web Search and
Data Mining (pp. 87-94). ACM.
Cold Start. Wikipedia
Chapelle, O., Joachims, T., Radlinski, F., & Yue, Y. (2012).
Large-scale validation and analysis of interleaved search evaluation.
ACM Transactions on Information Systems (TOIS), 30(1), 6.
Akka: http://akka.io
Radlinski, F., & Craswell, N. (2010, July). Comparing the
sensitivity of information retrieval metrics. In Proceedings of the
33rd international ACM SIGIR conference on Research and development in
information retrieval (pp. 667-674). ACM.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
