來源 | 雪晴數據網
利用機器學習可以很方便的做情感分析��。本篇文章將介紹在R語言中如何利用機器學習方法來做情感分析��。在R語言中��,由Timothy P.Jurka開發的情感分析以及更一般的文本挖掘包已經得到了很好的發展�����。你可以查看下sentiment包以及夢幻般的RTextTools包�。實際上���,Timothy還寫了一個針對低內存下多元Logistic回歸(也稱最大熵)的R包maxtent���。
然而��,RTextTools包中不包含樸素貝葉斯方法�。e1071包可以很好的執行樸素貝葉斯方法�。e1071是TU Wien(維也納科技大學)統計系的一門課程�����。這個包的主要開發者是David Meyer�。
我們仍然有必要了解文本分析方面的知識�。用R語言來處理文本分析已經是公認的事實(詳見R語言中的自然語言處理)����。tm包算是其中成功的一部分:它是R語言在文本挖掘應用中的一個框架���。它在文本清洗(詞干提取��,刪除停用詞等)以及將文本轉換為詞條-文檔矩陣(dtm)方面做得很好����。這里是對它的一個介紹�����。文本分析最重要的部分就是得到每個文檔的特征向量��,其中詞語特征最重要的���。當然���,你也可以將單個詞語特征擴展為雙詞組��,三連詞��,n-連詞等�����。在本篇文章����,我們以單個詞語特征為例做演示���。
注意�,在R中用ngram包來處理n-連詞����。在過去����,Rweka包提供了函數來處理它�,感興趣的可以查看這個案例?����,F在�����,你可以設置RTextTools包中create_matrix函數的參數ngramLength來實現它�。
第一步是讀取數據:

創建詞條-文檔矩陣:

現在��,我們可以用這個數據集來訓練樸素貝葉斯模型���。注意�����,e1071要求響應變量是數值型或因子型的���。我們用下面的方法將字符串型數據轉換成因子型:
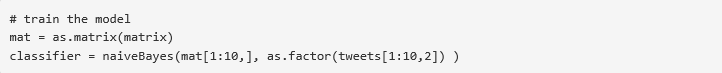
測試結果準確度:

顯然�����,這個結果跟python得到的結果是相同的(這篇文章是用python得到的結果)�����。
其它機器學習方法怎樣呢��?
下面我們使用RTextTools包來處理它����。
首先����,指定相應的數據:

其次��,用多種機器學習算法訓練模型:
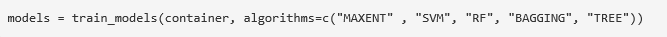
現在�����,我們可以使用訓練過的模型做測試集分類:

準確性如何呢���?

得到模型的結果摘要(特別是結果的有效性):

結果的交叉驗證:

結果可在我的Rpub頁面找到�??梢钥吹?��,maxent的準確性跟樸素貝葉斯是一樣的�����,其它方法的結果準確性更差���。這是可以理解的���,因為我們給的是一個非常小的數據集�����。擴大訓練集后��,利用更復雜的方法我們對推文做的情感分析可以得到一個更好的結果�。示例演示如下:
推文情感分析
數據來自victornep�。victorneo展示的是用python對推文做情感分析�。這里���,我們用R來處理它:
讀取數據:

首先�,嘗試下樸素貝葉斯

然后���,嘗試其他方法:

這里�,我們也希望得到正式的測試結果����。包括:
1.analytics@algorithm_summary:包括精確度����,召回率�����,準確率����,F-scores的摘要
2.analytics@label_summary:類標簽摘要
3.analytics@document_summary:所有數據和得分的原摘要
4.analytics@ensemble_summary:所有 精確度/覆蓋度 比值的摘要
現在讓我們看看結果:

與樸素貝葉斯方法相比��,其它算法的結果更好���,召回精度高于0.95�。結果可在Rpub查看
原文鏈接:http://www.xueqing.cc/cms/article/107
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
