近年來���,隨著大數據在Google��、Facebook等企業的成功應用��,很多傳統企業和初創公司都轉向應用大數據技術挖掘數據金礦?�,F有企業累計了大量的工業數據���,但是大數據的開發的復雜流程阻礙了企業快速從工業數據和商業數據中挖掘價值��。行業專家(算法研究者)精通行業數據分析����,卻受限于編程復雜度和缺乏快速部署算法的方法�,使很多創造性想法無法得到有效實施�。在這個技術飛躍的時代�,擁有大量工業數據的企業和技術專家們應該如何開展大數據技術的研發工作���?
大數據從業者在數據搜集�、數據探索��、開發和部署的每一個階段都會碰到各式各樣的難題�,不得不在不同的開發環境中進行切換����,并為此付出了大量額外的時間和人力成本���。在現有的數據資源上��,如何對數據進行清洗�����、整合以及探索性研究���,正是數據專家們發揮專長的地方���;而這個過程所耗費的時間往往是編程實現的好幾倍�����。今天多數的大數據方案都是依托Hadoop環境來做結構化和非結構化數據處理���,如何把自己的Hadoop算法快速部署到實際的生產環境當中去����,對很多企業的大數據部署也提出了挑戰��。
MathWorks公司的MATLAB軟件在科研和工業生產上擁有大量的用戶����,而且在數據分析領域�����,MATLAB作為傳統數據分析專業軟件獨樹一幟�。最近�����,針對大數據研發過程中關鍵點�,基于大家熟悉的 MATLAB 開發環境�����,該公司提出一個完整的解決方案����。下面我們就來看看他們關于大數據分析的流程���,來自MathWorks公司的資深應用工程師陳建平對記者做了相關介紹�。
從流程角度上看����,整個大數據處理可以分成4個主要步驟��。第一步是數據的搜集和存儲�;第二步是通過數據分析技術對數據進行探索性研究���,包括無關數據的剔除即數據清洗�����,和尋找數據的模式探索數據的價值所在; 第三步是在基本數據分析的基礎上�����,選擇和開發數據分析算法�,對數據進行建模�。從數據中提取有價值的信息���,這其實是真正的大數據的學習過程���。這其中會涉及很多算法和技術��,比如機器學習算法等; 最后一步是對模型的部署和應用����,即把研究出來的模型應用到生產環境之中�。
我們分別從流程和技術兩個角度來看一下MATLAB開發大數據應用的特點���。從流程上����,我們可以把大數據應用的過程分成四步��。
第一步�,數據的獲取和存儲和訪問��。MathWorks的產品是以工具箱的形式來組合的��,在現有MATLAB 平臺上已經有80多個專業工具箱和300多個第三方廠商工具箱��。 從數據搜集和訪問角度���,MATLAB 支持以下幾種搜集和訪問方式:
數據庫的訪問�����。數據庫是現有的大量數據�����,尤其是工業數據的默認存儲格式�����。目前最新版本的MATLAB即支持對結構化數據庫的訪問��,同時支持非結構數據庫的訪問�,比如Mango DB�,用戶無需學習SQL等專業語言�,即可通過MATLAB語言進行數據庫的訪問�����。另外��,MATLAB也支持從專業金融數據庫中直接抓取金融數據����。
分布式文件系統�����。從2014b版本開始�����,通過引入一個叫做datastore的數據結構���,MATLAB 已經能夠支持對Hadoop HDFS文件系統的訪問�����,并且統一了文件�、文件夾��、分布式數據庫的訪問接口���,使用者無需改動算法即可訪問不同的數據來源���。
硬件數據的采集���。MATLAB一直以來都硬件設備有著良好的支持���,從專業數據采集設備��,比如數據采集卡和測試儀器�����,到通用硬件�����,比如攝像機����,都有統一的訪問接口支持直接從MATLAB語言中抓取數據�����。結合不同的數據搜集����、存儲和訪問手段�,在一個平臺中就能夠完成大多數數據搜集和整理的工作�。
第二步�����,數據的組織和基礎分析�����。這一部分需要介入相應的統計手段�,也是行業專家最擅長的地方����。行業專家可以結合對行業的理解�,探尋數據的價值所在����。行業專家對自身工作領域非常熟悉��,了解自身行業數據特點��,但是未必對通用編程語言比如C或者Java充分熟悉���。
MATLAB作為工業普及的語言���,以其語法簡單和可視化功能強大而深受工業和研究人員的喜愛��。最新的MATLAB提供了大量圖形化傻瓜工具��,可以幫助行業專家進行諸如數據導入�����、數據清洗和數據可視化分析��。更重要的一個特點是�����,這些工具大部分支持通過搜集操作行為���,自動生成MATLAB腳本或者函數的能力����,輔助自動化開發�����。即使你不了解編程細節�����,也能夠得到高校的代碼��,大大提升了開發效率���。
MATLAB的工具箱覆蓋了各個不同的領域�,行業專家可以采用相應的工具箱�����,對數據進行初步處理和特征探索�����,比如通過濾波等信號處理手段濾去噪聲�,或者通過頻譜檢測����,尋找語音數據的囂叫����。這是通用數據分析工具無法替代的���。
第三步�����,數據建模�。經過數據清洗����、探索性分析�����,目的就是為了建立一個有效模型用于工業生產���。典型的手段是求助于統計分析方法和機器學習算法�,尋求合理的數學模型�����。一直以來��,MATLAB就是一個傳統的數據分析平臺��,最近幾年MathWorks結合最新的機器學習算法和深度學習算法�����,推出了升級了神經網絡和統計工具箱����。機器學習不再需要編寫大量的代碼了���,通過采用分類和聚類App���,可以對數據進行拖放就可以完成機器學習的過程����。直接從App分析結果中就可以得到最佳的預測模型�����。
最后一步�����,應用發布�。如何把計算模型發布到生產環境中�,是一件費事費力的工作��。傳統算法開發流程中�,算法工程師開發完算法后����,把算法通過文本或者偽代碼的方式提交給軟件工程師�����,軟件工程師再通過通用編程語言對算法進行實現��。這種分段式開發方法非常容易帶來錯誤�,而且開發效率也相對地下��。
現在�,行業專家可以在前一個階段得到的模型基礎上�,通過App和幾個鼠標點擊就可以把MATLAB代碼發布成可執行程序�、動態鏈接庫����、JAVA或者.NET包�����。部署工程師可以在這些結果上進行集成即可����,減少了重新開發潛在的錯誤���,加速了開發迭代的過程�����。
這4步構成了一個完整的大數據應用流程�,行業專家可以在一個熟悉的環境中完成整個復雜數據分析的過程�����。
從技術進展的角度����,MATLAB針對不同的數據規模和不同的數據復雜度��,也提供了不同的大數據支持��。下面的圖對從數據復雜度和數據規模角度對數據進行了一個簡單分類�����。
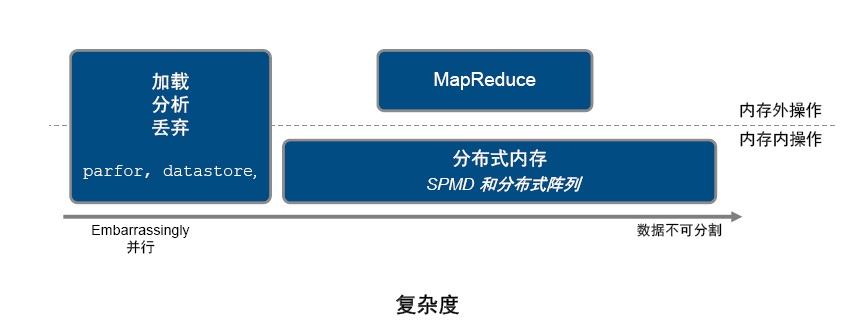 陳建平介紹說:“針對不同的數據類型和規模�����,我們應該有不同的處理方式��,才能夠達到處理和效率的最佳化�。根據數據規模�����,把數據劃分成能夠加載入集群內存中的數據�����,和無法加載到集群內存的數據; 根據數據的復雜度�����,我們把數據可以分成能夠分片并行處理的簡單數據和無法分片的復雜數據��。針對每一種組合�����,MATLAB都應該要有不同的解決方法�,并且應該提供足夠傻瓜的處理技術�����?����!?/span>
陳建平介紹說:“針對不同的數據類型和規模�����,我們應該有不同的處理方式��,才能夠達到處理和效率的最佳化�。根據數據規模�����,把數據劃分成能夠加載入集群內存中的數據�����,和無法加載到集群內存的數據; 根據數據的復雜度�����,我們把數據可以分成能夠分片并行處理的簡單數據和無法分片的復雜數據��。針對每一種組合�����,MATLAB都應該要有不同的解決方法�,并且應該提供足夠傻瓜的處理技術�����?����!?/span>
在上述的二維劃分中��,我們可以把數據類型總結為三大類: 第一類為簡單數據�����,即數據能夠被劃片���,能夠被多個節點同時處理���。第二類為能夠支持MapReduce操作的數據�����。第三類為復雜數據���,這一類數據傳統上屬于高性能計算的領域�����,需要專門的編程和環境才能夠處理�����。
第一類問題是最簡單的�,也是最容易被簡單編程實現的����。理論上����,我們通過手工或者自動化把數據劃分成單機能夠處理的數據片����,啟動足夠的計算資源即可�����。實際上�,對這類問題的處理���,在需要考慮計算效率的地方�����,還是需要一定的編程技巧要求的�����,比如如何做到負載均衡就是一個相對復雜的問題��。MATLAB中通過并行計算工具箱和分布式計算服務器�,可以用一個 ”parfor” 語句即可實現這類數據的并行化����。
第二類問題可以通過MapReduce算法框架可以解決的問題�����。一般這類問題的數據是存放在HDFS之中�,客戶已經有了Hadoop環境���,當時如何編寫MapReduce算法是一個難點�,需要一定的Java或者Python的相關編程經驗�����,并且熟悉相應的API��。在MATLAB中�����,你可以通過 “datastore” 直接訪問本地文件�、本地文件夾����、HDFS文件����、以及HDFS文件夾��。工程師只要書寫相應的MATLAB Map函數和 MATLAB語言的 Reduce 函數即可調用Hadoop環境進行MapReduce運算��。在完成計算后��,可以把相應的MATLAB代碼放到部署App中����,一鍵部署到MapReduce生產環境中�����。
最后一類問題最復雜�����,數據無法分割成片段���,也無法通過MapReduce模型建模�����。一個典型的應用是大規模矩陣的分析����。MATLAB中可以通過并行計算工具箱和MATLAB分布式計算服務器直接對陣列運算并行化�。這類運算可以在客戶端上對集群的計算過程進行交互式控制���,并行化編程就像單機串行運算一樣簡單���。
不管從大數據的處理流程上���,還是從數據規模上����,作為一個完整的開發平臺�,MATLAB提供了從數據搜集�、數據分析�、數據建模和應用部署等全面解決方案�����。用戶可以不用過多關注編程細節�����,只需把有限的時間和資源投入到有效的分析過程中����,讓大數據應用開發成為一件簡單輕松的事情����。
受訪人信息:

陳建平�����,MathWorks 中國資深技術專家�����,專注于工程大數據分析和高性能計算領域�����。擁有北京大學學士和碩士學位���,并于2008年加入MathWorks公司�����。之前�,他在NTT DoCoMo從事4G算法研究和無線系統設計���。加入MathWorks后�,專注于高性能計算和工程數據的分析和建模�,并深入探索工程數據在大數據領域的應用����。他擁有十余年數值算法設計����、實現�,以及對大規模工程數據分析和建模經驗�;尤其對MATLAB與不同編程語言����,以及Hadoop和Spark等大數據架構的結合有較為深入的研究�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
