在數據分析過程中最頭疼的應該是如何應付臟數據���,臟數據的存在將會對后期的建模���、挖掘等工作造成嚴重的錯誤���,所以必須謹慎的處理那些臟數據��。
臟數據的存在形式主要有如下幾種情況:
1)缺失值
2)異常值
3)數據的不一致性
下面就跟大家侃侃如何處理這些臟數據��。
一���、缺失值
缺失值����,顧名思義就是一種數據的遺漏����,根據CRM中常見的缺失值做一個匯總:
1)會員信息缺失�,如身份證號�����、手機號���、性別����、年齡等
2)消費數據缺失����,如消費次數�、消費金額�����、客單價����,卡余等
3)產品信息缺失��,如批次����、價格��、折扣�、所屬類別等
根據實際的業務需求不同��,可以對缺失值采用不同的處理辦法�,如需要給會員推送短信��,而某些會員恰好手機號不存在���,可以考慮剔除�����;如性別不知道����,可以使用眾數替代��;如年齡未知��,可以考慮用均值替換����。當然還有其他處理缺失值的辦法�����,如多重插補法�。下面以一個簡單的例子�����,來說明缺失值的處理�。
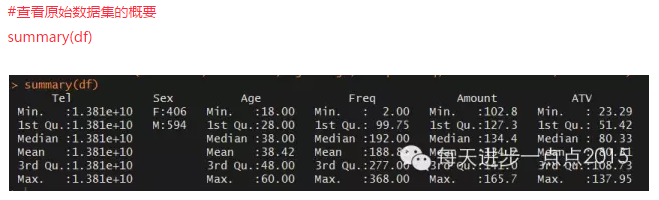
 上面的數據框是一個不含有任何缺失值的數據集�����,現在我想隨機產生100個缺失值�����,具體操作如下:
上面的數據框是一個不含有任何缺失值的數據集�����,現在我想隨機產生100個缺失值�����,具體操作如下:

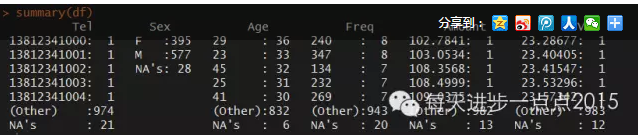 很明顯這里已經隨機產生100個缺失值了��,下面看看這100個缺失值的分布情況����。我們使用VIM包中的aggr()函數繪制缺失值的分布情況:
很明顯這里已經隨機產生100個缺失值了��,下面看看這100個缺失值的分布情況����。我們使用VIM包中的aggr()函數繪制缺失值的分布情況:
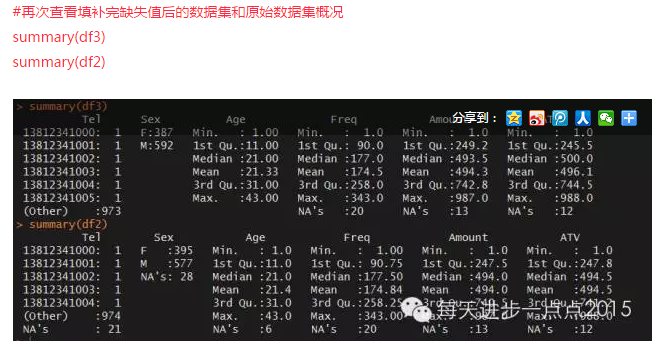
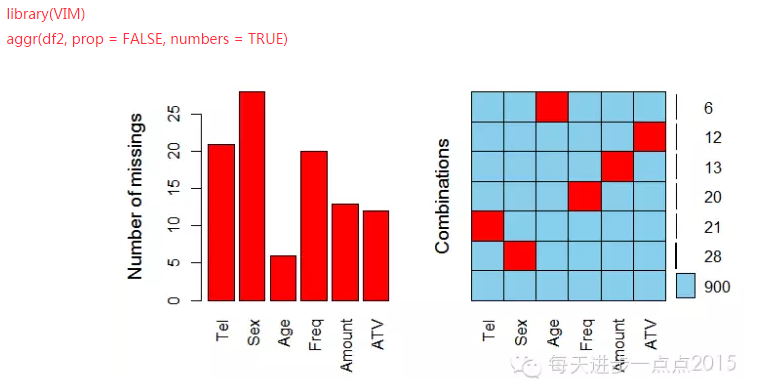 圖中顯示:Tel變量有21個缺失��,Sex變量有28個缺失�,Age變量有6個缺失���,Freq變量有20個缺失��,Amount變量有13個缺失����,ATV有12個缺失��。
為了演示�����,下面對Tel變量缺失的觀測進行剔除����;對Sex變量的缺失值用眾數替換�����;Age變量用平均值替換���;Freq變量�、Amount變量和ATV變量用多重插補法填充�����。
圖中顯示:Tel變量有21個缺失��,Sex變量有28個缺失�,Age變量有6個缺失���,Freq變量有20個缺失��,Amount變量有13個缺失����,ATV有12個缺失��。
為了演示�����,下面對Tel變量缺失的觀測進行剔除����;對Sex變量的缺失值用眾數替換�����;Age變量用平均值替換���;Freq變量�、Amount變量和ATV變量用多重插補法填充�����。
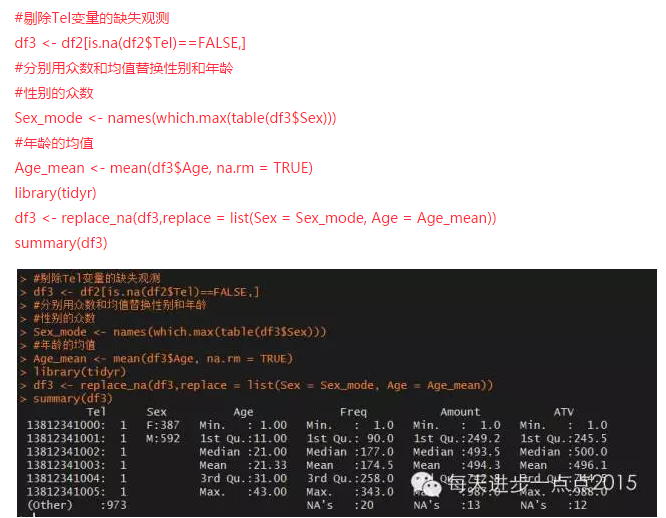 這個時候�����,Tel變量����、Sex變量和Age變量已不存在缺失值���,下面對Freq變量�、Amount變量和ATV變量使用多重插補法���。
可通過mice包實現多重插補法��,該包可以對數值型數據和因子型數據進行插補���。對于數值型數據����,默認使用隨機回歸添補法(pmm)��;對二元因子數據��,默認使用Logistic回歸添補法(logreg)����;對多元因子數據�,默認使用分類回歸添補法(polyreg)��。其他插補法��,可通過 mice查看相關文檔����。
這個時候�����,Tel變量����、Sex變量和Age變量已不存在缺失值���,下面對Freq變量�、Amount變量和ATV變量使用多重插補法���。
可通過mice包實現多重插補法��,該包可以對數值型數據和因子型數據進行插補���。對于數值型數據����,默認使用隨機回歸添補法(pmm)��;對二元因子數據��,默認使用Logistic回歸添補法(logreg)����;對多元因子數據�,默認使用分類回歸添補法(polyreg)��。其他插補法��,可通過 mice查看相關文檔����。

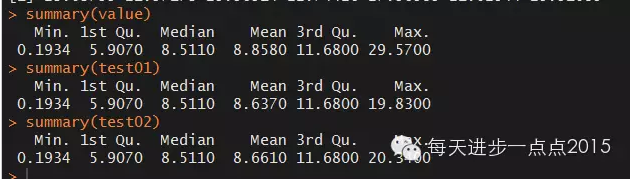
 通過不同的方法將缺失值數據進行處理�,從上圖可知���,通過填補后����,數據的概概覽情況基本與原始數據相近��,說明填補過程中��,基本保持了數據的總體特征���。
二�����、異常值
異常值也是非常痛恨的一類臟數據����,異常值往往會拉高或拉低數據的整體情況���,為克服異常值的影響��,我們需要對異常值進行處理�����。首先���,我們需要識別出哪些值是異常值或離群點�,其次如何處理這些異常值����。下面仍然以案例的形式����,給大家講講異常值的處理:
1.識別異常值
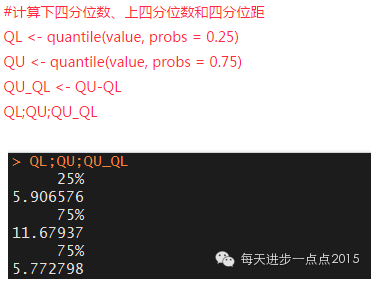
一般通過繪制盒形圖來查看哪些點是離群點�,而離群點的判斷標準是四分位數與四分位距為基礎����。即離群點超過上四分位數的1.5倍四分位距或低于下四分位數的1.5倍四分位距��。
例子:
通過不同的方法將缺失值數據進行處理�,從上圖可知���,通過填補后����,數據的概概覽情況基本與原始數據相近��,說明填補過程中��,基本保持了數據的總體特征���。
二�����、異常值
異常值也是非常痛恨的一類臟數據����,異常值往往會拉高或拉低數據的整體情況���,為克服異常值的影響��,我們需要對異常值進行處理�����。首先���,我們需要識別出哪些值是異常值或離群點�,其次如何處理這些異常值����。下面仍然以案例的形式����,給大家講講異常值的處理:
1.識別異常值
一般通過繪制盒形圖來查看哪些點是離群點�,而離群點的判斷標準是四分位數與四分位距為基礎����。即離群點超過上四分位數的1.5倍四分位距或低于下四分位數的1.5倍四分位距��。
例子:
 圖中可知��,有一部分數據落在上四分位數的1.5倍四分位距之上�����,即異常值���,下面通過編程�����,將異常值找出來:
圖中可知��,有一部分數據落在上四分位數的1.5倍四分位距之上�����,即異常值���,下面通過編程�����,將異常值找出來:
 2.找出異常點
2.找出異常點
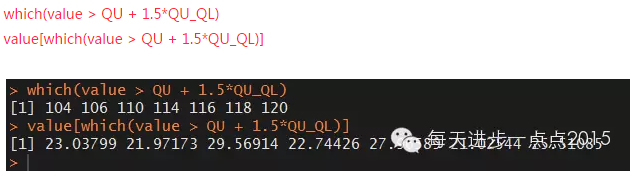 結果顯示���,分別是第104�、106���、110���、114�、116�����、118和120這6個點���。下面就要處理這些離群點��,一般有兩種方法����,即剔除或替補�。剔除很簡單�����,但有時剔除也會給后面的分析帶來錯誤的結果��,接下來就講講替補���。
結果顯示���,分別是第104�、106���、110���、114�、116�����、118和120這6個點���。下面就要處理這些離群點��,一般有兩種方法����,即剔除或替補�。剔除很簡單�����,但有時剔除也會給后面的分析帶來錯誤的結果��,接下來就講講替補���。

 三���、數據的不一致性
三���、數據的不一致性
數據的不一致性一般是由于不同的數據源導致�����。如有些數據源的數據單位是斤�,而有些數據源的數據單位為公斤�����;如有些數據源的數據單位是米�,而有些數據源的數據單位為厘米����;如兩個數據源的數據沒有同時更新等����。對于這種不一致性可以通過數據變換輕松得到一致的數據�,只有數據源的數據一致了���,才可以進行統計分析或數據挖掘�����。由于這類問題的處理比較簡單��,這里就不累述具體的處理辦法了����。
來源 | 先鋒的家園(51CTO博客)
http://jackwxh.blog.51cto.com/2850597/1742916
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
