引言:數據分析師的角色猶如一位大廚���,原料有問題�����,大廚肯定烹飪不出色香味俱佳的大菜�,數據有問題���,數據分析師得出的結論自然也就不可靠���。
 如果一位大廚�,剛剛眉飛色舞地給客人描繪了如何搭配一道色香味俱佳的大菜�,甚至連炒菜的手法都一一交代了��,當大廚備好了各種調料準備烹飪時�����,才發現所需的主要原料有問題�����。我們能清晰地看到大廚的臉上的囧字�。
數據分析師的角色猶如一位大廚�����,原料有問題�����,大廚肯定烹飪不出色香味俱佳的大菜�����,數據有問題�,數據分析師得出的結論自然也就不可靠��,再好的數據分析方法論也只是建立在失真的數據基礎上���,苦心構建的數據體系當然也被白白浪費了��。
過往的項目中���,筆者也時常遇到這樣的情況����,客戶用永洪科技的產品做了一些精美專業的數據報告�,卻因數據不準而影響了報告的使用價值���。
如果一位大廚�,剛剛眉飛色舞地給客人描繪了如何搭配一道色香味俱佳的大菜�,甚至連炒菜的手法都一一交代了��,當大廚備好了各種調料準備烹飪時�����,才發現所需的主要原料有問題�����。我們能清晰地看到大廚的臉上的囧字�。
數據分析師的角色猶如一位大廚�����,原料有問題�����,大廚肯定烹飪不出色香味俱佳的大菜�����,數據有問題�,數據分析師得出的結論自然也就不可靠��,再好的數據分析方法論也只是建立在失真的數據基礎上���,苦心構建的數據體系當然也被白白浪費了��。
過往的項目中���,筆者也時常遇到這樣的情況����,客戶用永洪科技的產品做了一些精美專業的數據報告�,卻因數據不準而影響了報告的使用價值���。
 前兩篇文章筆者分別探討了面對數據指標如何分析��,以及如何構建系統化的數據體系��,本文是“數據化運營方法論系列”文章的第三篇�����,重點探討的核心話題是——數據治理�����。
往期回顧
“數據化運營方法論系列”文章第一篇《大道至簡的數據分析方法論》鏈接:
http://yonghongtech.com/html/news/company/2016/0129/460.html�����。
“數據化運營方法論系列”文章第二篇《大道至簡的數據體系構建方法論》鏈接:http://yonghongtech.com/html/news/media/2016/0308/466.html
數據治理是一項基礎工作�����,在很多人眼中是一項苦活兒累活兒����,但是越是這樣的工作越是不能忽視���,基礎打扎實了��,上層建筑才會更穩固����。下面��,筆者先從臟數據的種類及處理方法談起���。
1.臟數據的種類及處理方法
首先���,我們來了解一下臟數據的種類�����,明白我們可能會面對哪些問題����。
前兩篇文章筆者分別探討了面對數據指標如何分析��,以及如何構建系統化的數據體系��,本文是“數據化運營方法論系列”文章的第三篇�����,重點探討的核心話題是——數據治理�����。
往期回顧
“數據化運營方法論系列”文章第一篇《大道至簡的數據分析方法論》鏈接:
http://yonghongtech.com/html/news/company/2016/0129/460.html�����。
“數據化運營方法論系列”文章第二篇《大道至簡的數據體系構建方法論》鏈接:http://yonghongtech.com/html/news/media/2016/0308/466.html
數據治理是一項基礎工作�����,在很多人眼中是一項苦活兒累活兒����,但是越是這樣的工作越是不能忽視���,基礎打扎實了��,上層建筑才會更穩固����。下面��,筆者先從臟數據的種類及處理方法談起���。
1.臟數據的種類及處理方法
首先���,我們來了解一下臟數據的種類�����,明白我們可能會面對哪些問題����。
 1. 數據缺失:缺一些記錄或一條記錄里缺一些值(空值)�����,或者兩者都缺����。原因可能有很多種��,系統導致的或人為導致的可能性都存在�。如果有空值����,為了不影響分析的準確性���,要么不將空值納入分析范圍����,要么進行補值��。前者會減少分析的樣本量��,后者需要根據分析的計算邏輯���,選擇用平均數�、零���、或者等比例隨機數等來填補��。如果是缺一些記錄����,若業務系統中還有這些記錄����,則通過系統再次導入��,若業務系統也沒有這些記錄了��,只能手工補錄或者放棄�����。
2. 數據重復:相同記錄出現多條�,這種情況相對好處理���,去掉重復記錄即可�����。但是怕就怕不完全重復����,比如兩條會員記錄�����,其余值都一樣��,就是住址不一樣��,這就麻煩了��,有時間屬性的還能判斷以新值為準����,沒有時間屬性的就無從下手了��,只能人工判斷處理�。
3. 數據錯誤:數據沒有嚴格按照規范記錄����。比如異常值����,價格區間明明是100以內���,偏偏有價格=200的記錄����;比如格式錯誤�����,日期格式錄成了字符串���;比如數據不統一���,有的記錄叫北京��,有的叫BJ����,有的叫beijing����。對于異常值����,可以通過區間限定來發現并排除��;對于格式錯誤����,需要從系統級別找原因�����;對于數據不統一����,系統無能為力�����,因為它并不是真正的“錯誤”�����,系統并不知道BJ和beijing是同一事物���,只能人工干預����,做一張清洗規則表�����,給出匹配關系��,第一列是原始值���,第二列是清洗值���,用規則表去關聯原始表�����,用清洗值做分析�����,再好一些的通過近似值算法自動發現可能不統一的數據�。
4. 數據不可用:數據正確�����,但不可用�。比如地址寫成“北京海淀中關村”�����,想分析“區”級別的區域時還要把“海淀”拆出來才能用�。這種情況最好從源頭解決�,即數據治理��。事后補救只能通過關鍵詞匹配�,且不一定能全部解決����。
2.BI對數據的要求
接下來�����,我們了解一下BI對數據的要求����,結合上面臟數據的種類�����,中間的規避手段就是數據治理���。
1. 數據缺失:缺一些記錄或一條記錄里缺一些值(空值)�����,或者兩者都缺����。原因可能有很多種��,系統導致的或人為導致的可能性都存在�。如果有空值����,為了不影響分析的準確性���,要么不將空值納入分析范圍����,要么進行補值��。前者會減少分析的樣本量��,后者需要根據分析的計算邏輯���,選擇用平均數�、零���、或者等比例隨機數等來填補��。如果是缺一些記錄����,若業務系統中還有這些記錄����,則通過系統再次導入��,若業務系統也沒有這些記錄了��,只能手工補錄或者放棄�����。
2. 數據重復:相同記錄出現多條�,這種情況相對好處理���,去掉重復記錄即可�����。但是怕就怕不完全重復����,比如兩條會員記錄�����,其余值都一樣��,就是住址不一樣��,這就麻煩了��,有時間屬性的還能判斷以新值為準����,沒有時間屬性的就無從下手了��,只能人工判斷處理�。
3. 數據錯誤:數據沒有嚴格按照規范記錄����。比如異常值����,價格區間明明是100以內���,偏偏有價格=200的記錄����;比如格式錯誤�����,日期格式錄成了字符串���;比如數據不統一���,有的記錄叫北京��,有的叫BJ����,有的叫beijing����。對于異常值����,可以通過區間限定來發現并排除��;對于格式錯誤����,需要從系統級別找原因�����;對于數據不統一����,系統無能為力�����,因為它并不是真正的“錯誤”�����,系統并不知道BJ和beijing是同一事物���,只能人工干預����,做一張清洗規則表�����,給出匹配關系��,第一列是原始值���,第二列是清洗值���,用規則表去關聯原始表�����,用清洗值做分析�����,再好一些的通過近似值算法自動發現可能不統一的數據�。
4. 數據不可用:數據正確�����,但不可用�。比如地址寫成“北京海淀中關村”�����,想分析“區”級別的區域時還要把“海淀”拆出來才能用�。這種情況最好從源頭解決�,即數據治理��。事后補救只能通過關鍵詞匹配�,且不一定能全部解決����。
2.BI對數據的要求
接下來�����,我們了解一下BI對數據的要求����,結合上面臟數據的種類�����,中間的規避手段就是數據治理���。
 1. 結構化:數據必須是結構化的���。這可能是句廢話���,如果數據是大段的文本���,比如微博�����,那就不能用BI做量化的分析��,而是用分詞技術做語義的分析�,比如常說的輿情分析�。語義分析不像BI的量化分析一樣百分百計算準確��,而是有概率的����,人的語言千變萬化�,人自己都不能保證完全理解到位����,系統就更不可能了�,只能盡可能提高準確率�����。
2. 規范性:數據足夠規范�����。這么說比較含糊�,簡單來講就是解決了上述各類臟數據的問題�,把所有臟數據洗成“干凈數據”�。
3. 可關聯:如果想將兩個維度/指標做關聯分析��,這兩個維度/指標必須能關聯上�,要么在同一張表里�����,要么在兩張有可關聯字段的表里��。
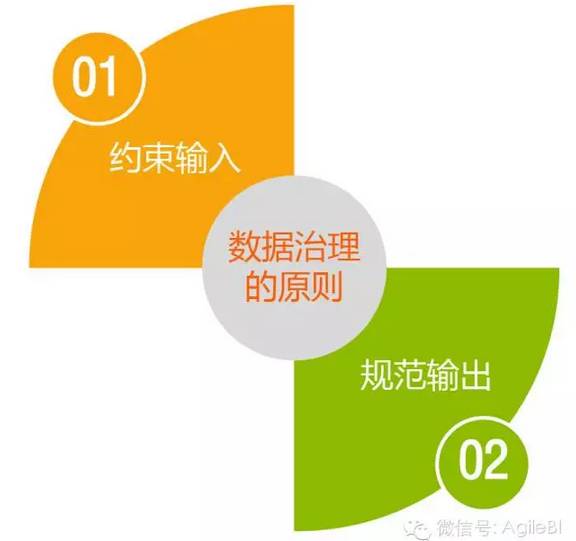
3.數據治理的原則
前面講了臟數據的處理方法��,但那些都是治標不治本的應對方法����,且需要長期耗費大量時間和人力來做這種痛苦的工作��。要想從根本上改善臟數據的問題���,還是需要做好數據治理的規范工作���。
簡單來講�����,數據治理就是要約束輸入�����,規范輸出�。
1. 結構化:數據必須是結構化的���。這可能是句廢話���,如果數據是大段的文本���,比如微博�����,那就不能用BI做量化的分析��,而是用分詞技術做語義的分析�,比如常說的輿情分析�。語義分析不像BI的量化分析一樣百分百計算準確��,而是有概率的����,人的語言千變萬化�,人自己都不能保證完全理解到位����,系統就更不可能了�,只能盡可能提高準確率�����。
2. 規范性:數據足夠規范�����。這么說比較含糊�,簡單來講就是解決了上述各類臟數據的問題�,把所有臟數據洗成“干凈數據”�。
3. 可關聯:如果想將兩個維度/指標做關聯分析��,這兩個維度/指標必須能關聯上�,要么在同一張表里�����,要么在兩張有可關聯字段的表里��。
3.數據治理的原則
前面講了臟數據的處理方法��,但那些都是治標不治本的應對方法����,且需要長期耗費大量時間和人力來做這種痛苦的工作��。要想從根本上改善臟數據的問題���,還是需要做好數據治理的規范工作���。
簡單來講�����,數據治理就是要約束輸入�����,規范輸出�。
 1. 約束輸入:你永遠想不到用戶會輸入哪些值����,所以別給用戶太多發揮的空間�����,做好約束工作��。該用戶填寫的�����,系統必須設置為“必填”��;值有固定選項的����,一定用列表讓用戶選��,別再手工輸入��;系統在錄入提交時就做好檢查����,格式不對����,值不在正常范圍內��,直接報錯的情況必須讓用戶重新輸入����;設計錄入表單時盡量原子化字段��,比如上面說的地址�����,設計時就分成國家�����、省����、市���、區����、詳細地址等多個字段���,避免事后拆分�;錄入數據保存的數據表也盡量統一�����,不要產生有大量相同數據的表���,造成數據重復隱患��。
2. 規范輸出:老板看不同人做的報表�,同一個“收益率”指標���,每張報表的值都不一樣��,老板的內心一定是崩潰的�,不知該罵誰�,只能全罵��。排除計算錯誤的情況���,一般都是統計口徑不一致造成的�。所以要統一語義�����,做一個公司級別的語義字典(不是數據庫的數據字典)�。所有給人看的報告上的指標名稱��,都要在語義字典中備案�,語義字典明確定義其統計口徑和含義��。不同統計口徑的指標必須用不同的名詞����。如果發現一個詞已經在語義字典中有了����,就必須走流程申請注冊一個新詞到語義字典���。
4.數據治理的落地
臟數據的處理需要ETL工具��,語義字典不一定要借助系統���。事實上�����,由于這類系統過于復雜��,國內鮮見實施成功的案例���,用Excel加制度就能達到很好的效果�。
關于落地推廣策略��,說來也簡單���,老大拍板說必須實行�����,再用優先話語權吸引一個部門試點����,再橫向擴展���。哪個部門先落地�,哪個部門就能按最符合自己習慣的用詞來命名指標�����,相當于占坑�����。后面的部門都要遵從前人的標準��,重名但意義不同的指標需要另外找詞兒命名�。這樣就不怕沒人積極主動�。
以上����,就是精煉版的數據治理方法論����。大家都知道這是個苦活�,但是筆者還要提醒的是��,越晚動手越苦�����。有了經驗以后����,做新業務系統設計時�����,大家就可以充分考慮數據治理的規范了����。
1. 約束輸入:你永遠想不到用戶會輸入哪些值����,所以別給用戶太多發揮的空間�����,做好約束工作��。該用戶填寫的�����,系統必須設置為“必填”��;值有固定選項的����,一定用列表讓用戶選��,別再手工輸入��;系統在錄入提交時就做好檢查����,格式不對����,值不在正常范圍內��,直接報錯的情況必須讓用戶重新輸入����;設計錄入表單時盡量原子化字段��,比如上面說的地址�����,設計時就分成國家�����、省����、市���、區����、詳細地址等多個字段���,避免事后拆分�;錄入數據保存的數據表也盡量統一�����,不要產生有大量相同數據的表���,造成數據重復隱患��。
2. 規范輸出:老板看不同人做的報表�,同一個“收益率”指標���,每張報表的值都不一樣��,老板的內心一定是崩潰的�,不知該罵誰�,只能全罵��。排除計算錯誤的情況���,一般都是統計口徑不一致造成的�。所以要統一語義�����,做一個公司級別的語義字典(不是數據庫的數據字典)�。所有給人看的報告上的指標名稱��,都要在語義字典中備案�,語義字典明確定義其統計口徑和含義��。不同統計口徑的指標必須用不同的名詞����。如果發現一個詞已經在語義字典中有了����,就必須走流程申請注冊一個新詞到語義字典���。
4.數據治理的落地
臟數據的處理需要ETL工具��,語義字典不一定要借助系統���。事實上�����,由于這類系統過于復雜��,國內鮮見實施成功的案例���,用Excel加制度就能達到很好的效果�。
關于落地推廣策略��,說來也簡單���,老大拍板說必須實行�����,再用優先話語權吸引一個部門試點����,再橫向擴展���。哪個部門先落地�,哪個部門就能按最符合自己習慣的用詞來命名指標�����,相當于占坑�����。后面的部門都要遵從前人的標準��,重名但意義不同的指標需要另外找詞兒命名�。這樣就不怕沒人積極主動�。
以上����,就是精煉版的數據治理方法論����。大家都知道這是個苦活�,但是筆者還要提醒的是��,越晚動手越苦�����。有了經驗以后����,做新業務系統設計時�����,大家就可以充分考慮數據治理的規范了����。
本文為永洪科技副總裁王桐原創���,CDA已獲作者授權轉載
作者敬告
由于時間關系和水平有限���,文中或有不妥之處還請讀者多多諒解�。如果希望一起探討數據分析方法論和數據體系構建方法論等相關話題����,歡迎讀者通過tylerwang@yonghongtech.com或微信號tyler_wangtong與本文作者永洪科技副總裁王桐取得聯絡�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
