Spark和Hadoop作業之間的區別_數據分析師
Spark目前被越來越多的企業使用��,和Hadoop一樣�����,Spark也是以作業的形式向集群提交任務�,那么在內部實現Spark和Hadoop作業模型都一樣嗎?答案是不對的�����。
熟悉Hadoop的人應該都知道�����,用戶先編寫好一個程序��,我們稱為Mapreduce程序�,一個Mapreduce程序就是一個Job�����,而一個Job里面可以有一個或多個Task����,Task又可以區分為Map Task和Reduce Task���,如下圖所示:

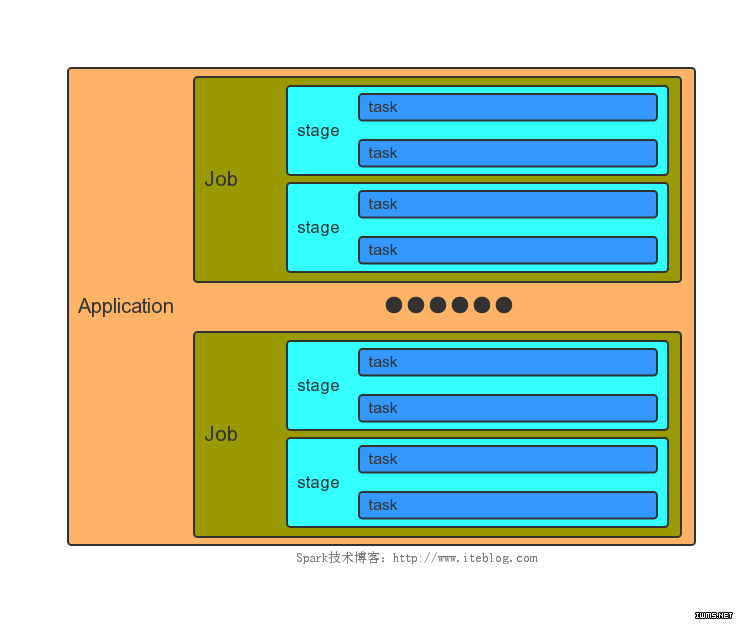
而在Spark中�����,也有Job概念����,但是這里的Job和Mapreduce中的Job不一樣�����,它不是作業的最高級別的粒度���,在它只上還有Application的概念����。我們先來看看Spark文檔是怎么定義Application�����,Task ���,Job和Stage的:

一個Application和一個SparkContext相關聯��,每個Application中可以有一個或多個Job�,可以并行或者串行運行 Job�����。Spark中的一個Action可以觸發一個Job的運行����。在Job里面又包含了多個Stage�,Stage是以Shuffle進行劃分的����。在 Stage中又包含了多個Task�,多個Task構成了Task Set��。他們之間的關系如下圖所示:
Mapreduce中的每個Task分別在自己的進程中運行�,當該Task運行完的時候�����,該進程也就結束了�����。和Mapreduce不一樣的 是���,Spark中多個Task可以運行在一個進程里面����,而且這個進程的生命周期和Application一樣���,即使沒有Job在運行���。
這個模型有什么好處呢?可以加快Spark的運行速度!Tasks可以快速地啟動�����,并且處理內存中的數據����。但是這個模型有的缺點就是粗粒度的資源管理�,每個Application擁有固定數量的executor和固定數量的內存���。 本文來源:CDA數據分析師
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
