數據挖掘問答精選收藏
1. 現在有大數據����、精準挖掘�、人工智能等這么多概念及技術��,它們之間的關系以及企業大數據實施的路線圖應該是怎樣的��?
來自用戶 SmartMining 的回答:
大數據�、數據挖掘��、人工智能三者的關系可以簡單的理解為:大數據是原材料����,數據挖掘是加工廠��,而人工智能是數據產品尤其是基于數據挖掘技術建立的專家系統的設計理念��。
通過使用數據挖掘技術對大數據進行價值提取����、加工����,進而設計成可以服務于用戶的數據產品����,并基于人工智能的思想對該產品做自動優化和人機交互學習���,讓產品越用越好���,最終達到具有生產力的目的�。
企業要想開展大數據的實踐主要完成以下幾件事情:
第一���,進行數據采集�����。除了傳統的ETL之外����,還可以從互聯網采集可用的數據����,甚至增加采集數據的設備���。進而豐富數據的來源��;
第二���,對這些數據進行清洗�����、轉換并融合到一起��,建立大數據管理平臺���,即PAAS平臺����。實現數據資源���、計算資源等的共享��;
第三��,大數據價值探索��,基于業務痛點設計可行方案�����,使用數據挖掘的技術對挖掘數據的價值�,并生產出有助于解決企業實際的問題的信息�����。
以上三者其實互為補充����、不可分割又可同步進行�����。原因如下:
1���、數據的應用可以更好的知道大數據平臺的建設��,知道數據用來干什么�、怎么用才能更好的設計管理平臺���,才能知道哪些數據有用����、知道采集哪些數據�;
2�、大數據管理平臺建設周期比較長�����,因此可以先選擇一個主題先做數據挖掘�����,培養團隊的同時也做了技術驗證�;
3��、做數據挖掘應用�,也可以反過來驗證平臺是建設完善�,驗證大數據管理平臺是否可以支撐應用���。
2. 決策樹樹算法目前的應用場景有哪些�?像 C4.5,CART,SLIQ,SPRINT,PUBLIC��,RainForest 等這些算法���,目前都用在哪些行業領域里�?
來自用戶 Philbert 的回答:
樓主的這個問題感覺范圍比較廣,個人的一點看法如下:
1. 就決策樹的這個算法而言����,在非常多的行業都會有應用����,是不是使用決策樹進行挖掘分析個人認為還是要看具體的應用分析目標�,廣義點說任何一個行業都可能出現適合決策樹的應用分析目標����,比如:在用決策樹進行用戶分級評估的時候�����,凡是積累了一定量的客戶資源和數據�,涉及對自己行業客戶進行深入分析的企業和分析者都可能具備使用決策樹的條件�����。
2 一般來說決策樹的應用用往往都是和某一應用分析目標和場景相關的��,比如:金融行業可以用決策樹做貸款風險評估��,保險行業可以用決策樹做險種推廣預測���,醫療行業可以用決策樹生成輔助診斷處置模型等等�����,當一個決策樹的應用分析目標和場景確定��,那該應用分析目標和場景所處的行業也就自然成為了決策樹的應用領域�����。
注:決策樹作為一種數據分析挖掘的方法���,可以為任何適合其分析思路和處理方式的應用分析目標和數據服務����,所以關注其應用領域的同時����,可以考慮更重點的關注適合其使用的應用分析目標和場景�����。
3. 想學習數據挖掘��,該如何構建學習路徑呢�����? 因為學校里好像沒有老師比較擅長這方面�����。該如何自學呢�����?
來自用戶 Elationquy 的回答:
數據挖掘的重點是“從大量數據中��,提取有價值的信息”��,這就說明了數據挖掘需要兩個方面的知識�����。
第一�����、處理數據���,建立數據挖掘模型的能力�,稱之為“技術能力”�;
第二�����、在所有的數據中��,哪些可以展示出有價值的信息���,這就需要結合業務���,只有結合業務���,才能發現有價值的東西�����。第一個好學���,也是大部分人眼中的數據挖掘��;第二個才是難點�����,學生的話��,接觸的業務不多�����,可能體會不深刻���,這個只能在生活中�,多想想如果有什么數據���、可以得到什么有價值的東西���,訓練自己的這方面的思維能力���。
關于技術與業務能力���,這個回答很不錯��,可以參考:http://www.flybi.net/question/14511
數據挖掘分成兩個方面�,一是數據挖掘技術的掌握��,在學校教的比較多的也是這個方面�,另一個是數據挖掘的應用��,這個方面主要是結合業務��,發現數據的價值���,只有能夠有效的利用好數據�����,才能成為一個合格的數據挖掘方面的專家�����。
4. 數據挖掘專業編程能力要到什么水平才算及格�����?
來自用戶 SmartMining 的回答:
只要你能夠熟練掌握一款數據挖掘工具���,能夠使用工具實現數據處理和挖掘算法����,懂得挖掘的用途和價值�,這就算及格了���。但是要變得優秀就難了���,學習數據挖掘真正的核心是幫助企業解決實際的業務問題�。簡單的講��,就是面對企業的痛點�����,你有解決的想法���,然后使用工具實現你的想法或者驗證你的想法�。
補充:做數據挖掘不一定要會編程�,這個并不是最重要的技能���,核心技能是應用數據的能力����。只要你能實現����,不管是使用會編程的工具還是無需編程的工具還是兩者混用都可以����。
5. 如何理解 SPSS 方差分析中的殘差圖
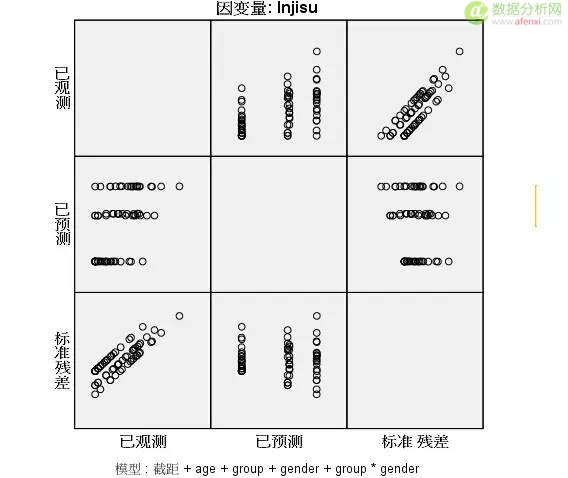
來自用戶 盧育峰 的回答:
首先你要了解怎么看這個圖��,這個是殘差圖哦����,要理解橫軸縱軸的含義�����。
以第二行第一列來看����,橫坐標是已觀測值�,縱坐標是已預測值 很明顯觀測值與預測值是成分類展示��。
以第三行第一列來看���,橫坐標是已觀測值��,縱坐標是標準差���,殘差分布規律太明顯了���?���?雌饋硐裆Ⅻc分布接近一條直線說明是滿足齊方差性但并不一定����,做好是做齊方差檢驗��。
從上圖來看��,有幾個原因可能導致這種情況:
1�����、缺少自變量���,導致模型的解釋變量被放在誤差里面��。
2�����、輸入值未做處理��,age��、group�、gender有可能需要做歸一化����。
3����、是否模型過度擬合���。
總的來說���,你用的方法不對���,或者缺少因子��,多了解一下理論吧����。
6. 在機器學習方面最經常用的算法有哪些�����?
來自用戶 盧育峰 的回答:
簡單說一下�,目前的算法都有各種應用�����,只是行業不同而已哦��。
按照機器學習的分法��,最常見的分類就是有監督學習��、無監督學習�、半監督學習����、強化學習�����。
有監督學習主要有:邏輯回歸(Logistic Regression)��、BP神經網絡(Back Propagation Neural Network)
無監督學習主要有:Apriori��、k-means.
半監督學習主要是分類和回歸��,有:推理算法(Graph Inference)����、拉普拉斯支持向量機(Laplacian SVM)
強化學習有:Q-learning�、時間差學習(Tempral difference learning)
如果按照數據挖掘來分:
分類與回歸:決策樹���、貝葉斯���、人工神經網絡���、K-近鄰�、支持向量機��、邏輯回歸等����。
關聯:Apriori����、FP-樹頻集等
聚類:k-means����、k-medoids等
簡單就這么看看吧�����,功能這一塊不好說���,不同算法的應用真的不一樣����,回頭我整理一下寫到博客里面���。
7. 數據挖掘 分類 和 回歸 是不是一回事����?哪一部分 機器學習和神經網絡應用的比較多�? 拜求大神賜教
來自用戶 Philbert 的回答:
樓主這個問題涉及的方面比較多����,我簡單說兩句���,供參考:
1 分類和回歸本質上都是通過對已有數據的訓練結果形成決策知識為預測型的應用目標服務的�。
2 回歸往往面對的是連續型數據的趨勢預測��,比如企業根據歷史銷售數據預測下一個月的銷售額����,這種情況下訓練出的決策知識往往以一個函數的形式來存在�����。
3 分類往往面對的是離散性數據的預測分析�,比如企業同樣根據歷史銷售數據預測下一個月的銷售額是上升����?持平�?下降�����?����,這種情況下訓練出的決策知識往往以一些規則的集合形式存在�����,我們常稱之為模型�����。
4 機器學習和神經網絡的應用方面這個問題比較大�,因為任何行業都可能出現合適這兩種技術的應用方向���,主要在于面向的數據類型和應用目標是不是適合這兩種技術 的分析方式�����,只要適合就可以去使用它們���,而且建議不要把它們分割開來看�����,很多應用目標的達成是綜合使用它們的結果����,很火的阿爾法狗����!就是目前綜合使用他們的最典型的案例�。
8. 私有云和公有云有什么區別�����?各有哪些優缺點�����,目前企業在具體使用時該怎么選擇�����?
來自用戶 SmartMining 的回答:
兩者區別主要在于建設成本和安全性上���。
私有云更安全���,因為建設在企業內部的局域網內����,不會把數據放到別人的平臺上�����,企業自己更可控更安全���。但是相對建設成本比公有云高一些�。但是畢竟數據的安全更重要��。而使用公有云的話��,需要把數據放到別人的公有云平臺上����,自然不安全���。因此���,選擇公有云還是私有云���,關鍵點就在于您對數據安全性的重視程度以及數據的重要性�����。
如果您公司的數據量不大�����,單一機器就可以搞定�,這樣不需要考慮使用公有云��;
如果數據量比較大���,但是不重要�����,比如都是從互聯網采集的數據�,這樣的話可以使用公有云�;
如果您的數據量比較大�,且比較重要���。暫且建議使用私有云的解決方案���。
9. 如果做風險模型如何通過機器學習自動化所實現�����?比如建風險模型����,可以通過機器學習自動化的變量篩選�,自動化計算評分�,實現每日自動化計算��,不需要經過人工參與
來自用戶 Philbert 的回答:
個人感覺這個問題的需要明確幾個細節才能考慮如何實現:
1 你說的自動化變量篩選是指建模前的數據預處理過程���?
2 一般情況下這種類型的建模要涉及訓練����,評估��,應用三個方面的工作�����,你說的自動化過程是指哪個方面�?
3 一般確定一個風險預測模型后確實需要根據應用的實際效果不斷對該模型進行調整���,但這個調整周期都是需要一定時間和新的應用數據積累的�����,每日的地自動化如果是指模型調整而言好像不是很合適��。
4 建議明確該風險模型的應用場景和目標����,不同的應用場景和目標對于訓練出的模型準確度的具體要求是不同的����,進而也會影響模型的評估標準�。
10. 傳統通過多維建模以后進行各個維度進行種分析����,與現在流行的“數據挖掘”的概念有什么不同��?
來自用戶 SmartMining 的回答:
其實��,可以簡單的理解�,多維分析是數據的多維度視圖����,是數據的一種探索分析手段��,和圖形化可視化探索數據異曲同工���,你可以把多維分析作為數據挖掘可視化探索的一部分�。
數據挖掘除了也可以使用圖形或多維表做數據探索分析外���,核心是通過一些手段(算法)總結數據中的規律����,這是對潛在規律的量化實現(規則��、數學公式等)���,如您可以根據歷史的銷售信息建立預測模型����,得到數學公式后��,只要輸入影響因素的值就可以預測銷量����,這一類屬于分類預測問題�,還可以使用用戶的信息對用戶進行分群�����,把相似的人歸為一類����,把不相似的人歸到不同的類中�,這是使用聚類模型量化用戶相似性的問題����,又比如�,可以使用時間序列算法預測未來每個月的用戶增量�、客運量等���。您可以發現�,這些都是一種推斷�,基于歷史的數據推斷出來的結果�����,并不是完全真實的事情��,只是在推斷未來會這樣發生發展��。
而多維分析是為了更好的展示歷史數據���,而沒有這種基于歷史數據的推斷和預測能力�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
