概述
在真實的數據科學世界里���,我們會有兩個極端�,一個是業務�����,一個是工程���。偏向業務的數據科學被稱為數據分析(Data Analysis)�,也就是A型數據科學���。偏向工程的數據科學被稱為數據構建(Data Building)���,也就是B型數據科學�。
從工具上來看���,按由業務到工程的順序�����,這個兩條是:EXCEL >> R >> Python >> Scala
在實際工作中����,對于小數據集的簡單分析來說���,使用EXCEL絕對是最佳選擇�。當我們需要更多復雜的統計分析和數據處理時�,我們就需要轉移到 Python 和 R 上��。在確定工程實施和大數據集操作時��,我們就需要依賴 Scala 的靜態類型等工程方法構建完整的數據分析系統�����。
Scala 和 Excel 是兩個極端��,對于大多數創業公司而言��,我們沒有足夠多的人手來實現專業化的分工�,更多情況下�,我們會在 Python 和 R 上花費更多的時間同時完成數據分析(A型)和數據構建(B型)的工作�����。而許多人也對Python和R的交叉使用存在疑惑�����,所以本文將從實踐角度對 Python 和 R 中做了一個詳細的比較�。
應用場景對比
應用Python的場景
網絡爬蟲/抓?����。罕M管 rvest 已經讓 R 的網絡爬蟲/抓取變得容易�����,但 Python 的 beautifulsoup 和 Scrapy 更加成熟�、功能更強大��,結合django-scrapy我們可以很快的構建一個定制化的爬蟲管理系統���。
連接數據庫: R 提供了許多連接數據庫的選擇��,但 Python 只用 sqlachemy 通過ORM的方式���,一個包就解決了多種數據庫連接的問題�����,且在生產環境中廣泛使用��。Python由于支持占位符操作�����,在拼接SQL語句時也更加方便����。
內容管理系統:基于Django����,Python可以快速通過ORM建立數據庫���、后臺管理系統���,而R
中的 Shiny 的鑒權功能暫時還需要付費使用�����。
API構建:通過Tornado這個標準的網絡處理庫���,Python也可以快速實現輕量級的API����,而R則較為復雜����。
應用R的場景
統計分析: 盡管 Python 里 Scipy�����、Pandas���、statsmodels 提供了一系列統計工具 �,R 本身是專門為統計分析應用建立的���,所以擁有更多此類工具�����。
互動式圖表/面板: 近來 bokeh�、plotly���、 intuitics 將 Python 的圖形功能擴展到了網頁瀏覽器�����,甚至我們可以用tornado+d3來進一步定制可視化頁面�,但 R 的 shiny 和 shiny dashboard 速度更快����,所需代碼更少���。
此外���,當今數據分析團隊擁有許多技能����,選擇哪種語言實際上基于背景知識和經驗�。對于一些應用���,尤其是原型設計和開發類��,工作人員使用已經熟悉的工具會比較快速���。
數據流編程對比
接著�����,我們將通過下面幾個方面�����,對Python 和 R 的數據流編程做出一個詳細的對比�。
1.參數傳遞
2.數據讀取
3.基本數據結構對照
4.矩陣轉化
5.矩陣計算
6.數據操作
參數傳遞
Python/R 都可以通過命令行的方式和其他語言做交互����,通過命令行而不是直接調用某個類或方法可以更好地降低耦合性����,在提高團隊協作的效率��。
 數據傳輸與解析
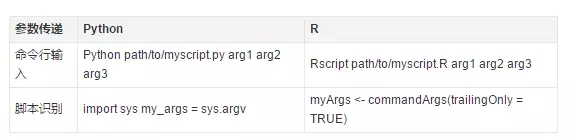
對于數據傳輸與解析��,我們首推的格式是csv�,因為一方面��,csv格式的讀寫解析都可以通過 Python 和 R 的原生函數完成��,不需要再安裝其他包�����。另一方面��,csv格式可以很快的轉化為 data frame 格式����,而data frame 格式是數據流分析的核心����。
不過��,實際情況中���,我們需要傳輸一些非結構化的數據��,這時候就必須用到 JSNO 或者 YAML����。
數據傳輸與解析
對于數據傳輸與解析��,我們首推的格式是csv�,因為一方面��,csv格式的讀寫解析都可以通過 Python 和 R 的原生函數完成��,不需要再安裝其他包�����。另一方面��,csv格式可以很快的轉化為 data frame 格式����,而data frame 格式是數據流分析的核心����。
不過��,實際情況中���,我們需要傳輸一些非結構化的數據��,這時候就必須用到 JSNO 或者 YAML����。
 基本數據結構
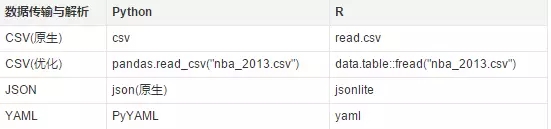
由于是從科學計算的角度出發�,R 中的數據結構非常的簡單��,主要包括 向量(一維)�、多維數組(二維時為矩陣)�����、列表(非結構化數據)�、數據框(結構化數據)��。而 Python 則包含更豐富的數據結構來實現數據更精準的訪問和內存控制���,多維數組(可讀寫�、有序)�、元組(只讀�����、有序)��、集合(唯一�、無序)��、字典(Key-Value)等等���。
基本數據結構
由于是從科學計算的角度出發�,R 中的數據結構非常的簡單��,主要包括 向量(一維)�、多維數組(二維時為矩陣)�����、列表(非結構化數據)�、數據框(結構化數據)��。而 Python 則包含更豐富的數據結構來實現數據更精準的訪問和內存控制���,多維數組(可讀寫�、有序)�、元組(只讀�����、有序)��、集合(唯一�、無序)��、字典(Key-Value)等等���。
 矩陣操作
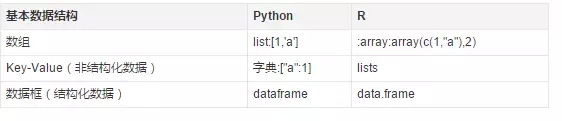
實際上����,Python(numpy) 和 R中的矩陣都是通過一個多維數組(ndarray)實現的���。
矩陣操作
實際上����,Python(numpy) 和 R中的矩陣都是通過一個多維數組(ndarray)實現的���。
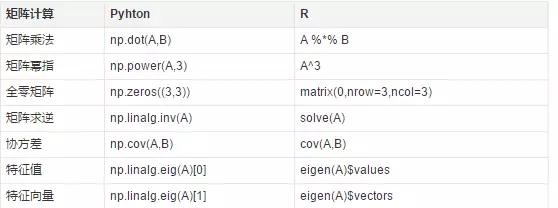 數據框操作
參考 R 中的 data frame 結構���,Python 的 Pandas包也實現了類似的 data frame 數據結構?��,F在�����,為了加強數據框的操作��,R 中更是演進出了 data table 格式(簡稱dt)�,這種格式以 dt[where�����,select����,group by] 的形式支持類似SQL的語法���。
數據框操作
參考 R 中的 data frame 結構���,Python 的 Pandas包也實現了類似的 data frame 數據結構?��,F在�����,為了加強數據框的操作��,R 中更是演進出了 data table 格式(簡稱dt)�,這種格式以 dt[where�����,select����,group by] 的形式支持類似SQL的語法���。


 數據流編程對比的示例
Python 的 Pandas 中的管道操作
數據流編程對比的示例
Python 的 Pandas 中的管道操作
 R 的 dplyr 中的管道操作
R 的 dplyr 中的管道操作
 數據可視化對比
繪制相關性散點圖
對比數據相關性是數據探索常用的一種方法����,下面是Python和R的對比����。
Python
數據可視化對比
繪制相關性散點圖
對比數據相關性是數據探索常用的一種方法����,下面是Python和R的對比����。
Python
 R
R
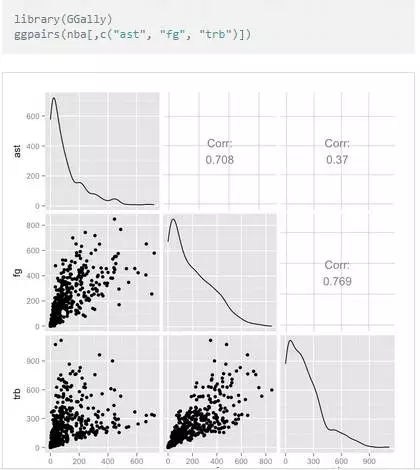 雖然我們最終得到了類似的圖形�����,這里R中GGally是依賴于ggplot2���,而Python則是在matplotlib的基礎上結合Seaborn�����,除了GGally在R中我們還有很多其他的類似方法來實現對比制圖���,顯然R中的繪圖有更完善的生態系統��。
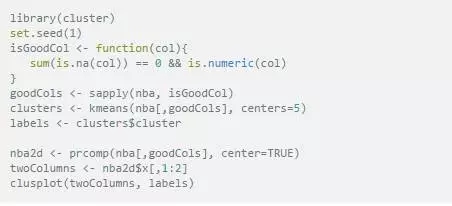
繪制聚類效果圖
這里以K-means為例����,為了方便聚類��,我們將非數值型或者有確實數據的列排除在外����。
Python
雖然我們最終得到了類似的圖形�����,這里R中GGally是依賴于ggplot2���,而Python則是在matplotlib的基礎上結合Seaborn�����,除了GGally在R中我們還有很多其他的類似方法來實現對比制圖���,顯然R中的繪圖有更完善的生態系統��。
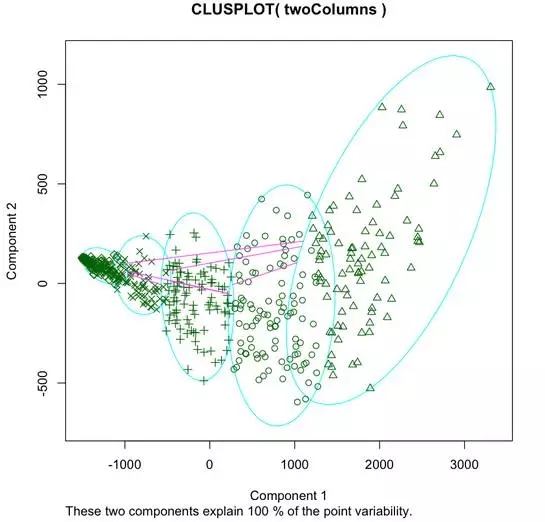
繪制聚類效果圖
這里以K-means為例����,為了方便聚類��,我們將非數值型或者有確實數據的列排除在外����。
Python
 R
R
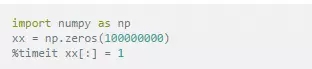
 速度對比
Python
速度對比
Python
 The slowest run took 9.29 times longer than the fastest. This could mean that an intermediate result is being cached
1 loops���, best of 3: 111 ms per loop
R
The slowest run took 9.29 times longer than the fastest. This could mean that an intermediate result is being cached
1 loops���, best of 3: 111 ms per loop
R
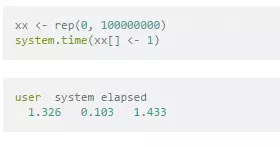 顯然這里 R 1.326的成績 比 Python 的 Numpy 3:111 的速度快了不少�����。
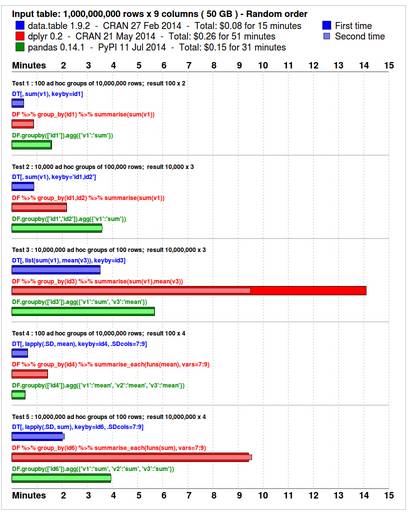
事實上�����,現在 R 和 Python 的數據操作的速度已經被優化得旗鼓相當了��。下面是R中的 data.table���、dplyr 與 Python 中的 pandas 的數據操作性能對比:
顯然這里 R 1.326的成績 比 Python 的 Numpy 3:111 的速度快了不少�����。
事實上�����,現在 R 和 Python 的數據操作的速度已經被優化得旗鼓相當了��。下面是R中的 data.table���、dplyr 與 Python 中的 pandas 的數據操作性能對比:
 結論
結論
Python 的 pandas 從 R 中偷師 dataframes����,R 中的 rvest 則借鑒了 Python 的 BeautifulSoup���,我們可以看出兩種語言在一定程度上存在的互補性�����,通常�,我們認為 Python 比 R 在泛型編程上更有優勢����,而 R 在數據探索�����、統計分析是一種更高效的獨立數據分析工具�。所以說����,同時學會Python和R這兩把刷子才是數據科學的王道����。
本文由CDA作者庫成員HarryZhu原創�,并授權發布����。
CDA作者庫凝聚原創力量��,只做更有價值的分享�����。
了解詳情請微信添加trasn863�,或發送郵件至songpeiyang@pinggu.org
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
