談到BI��,就會談到數據挖掘(Data mining)����。數據挖掘是指用某些方法和工具����,對數據進行分析����,發現隱藏規律并利的一種方法��。下面我們將通過具體的例子來學習什么是數據挖掘�����。
案例“上大學分析”-體驗什么是數據挖掘
某社會機構�����,收集了大量的學生考大學的數據�����。該機構希望找出一些規律�����,以推動更多的學生考大學���。該機構委托你來做這個分析工作�����,給出具體的可以推動更多學生考大學的建議���。
收集到的數據如下:
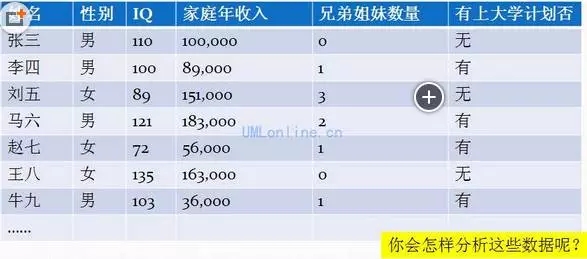 你可能會考慮用SQL語句進行查詢分析��。但問題是:
1.用什么語句查呢����?要組合什么條件呢�����?
2.你想查到怎樣的結果呢����?這個結果對決策有幫助嗎���?
那數據挖掘一下吧���!但如何挖掘呢����?
不了解數據挖掘的人�����,往往會認為只需要讓計算機去挖掘一下�,計算機就能幫我們找出想要的東西�。計算機哪會這樣神奇�,在數據挖掘之前�����,我們必須要自己好好分析一下���。
1.明確挖掘的目標����。
我們看看原始需求是這樣的:該機構希望找出一些規律���,以推動更多的學生考大學����。
你可能會說:該目標也太大了一點吧��!現在該機構委托你做這個事情���,人家不是專業人士����,你還指望人家什么都幫你做好嗎�����?那要你干嘛��!
我們仔細分析一下�����,原始數據有姓名�、性別�、IQ����、家庭年收入�、兄弟姐妹數量����、是否想上大學字段����,要推動更多學生考大學��,我們無非就是要分析出:
1)有上大學計劃的人主要原因是什么呢�?
2)無上大學計劃的人主要原因是什么呢���?
分析出這些原因���,就可以提出針對性的建議了�����。
2.明確因果關系
看下面這個圖:
你可能會考慮用SQL語句進行查詢分析��。但問題是:
1.用什么語句查呢����?要組合什么條件呢�����?
2.你想查到怎樣的結果呢����?這個結果對決策有幫助嗎���?
那數據挖掘一下吧���!但如何挖掘呢����?
不了解數據挖掘的人�����,往往會認為只需要讓計算機去挖掘一下�,計算機就能幫我們找出想要的東西�。計算機哪會這樣神奇�,在數據挖掘之前�����,我們必須要自己好好分析一下���。
1.明確挖掘的目標����。
我們看看原始需求是這樣的:該機構希望找出一些規律���,以推動更多的學生考大學����。
你可能會說:該目標也太大了一點吧��!現在該機構委托你做這個事情���,人家不是專業人士����,你還指望人家什么都幫你做好嗎�����?那要你干嘛��!
我們仔細分析一下�����,原始數據有姓名�、性別�、IQ����、家庭年收入�、兄弟姐妹數量����、是否想上大學字段����,要推動更多學生考大學��,我們無非就是要分析出:
1)有上大學計劃的人主要原因是什么呢�?
2)無上大學計劃的人主要原因是什么呢���?
分析出這些原因���,就可以提出針對性的建議了�����。
2.明確因果關系
看下面這個圖:
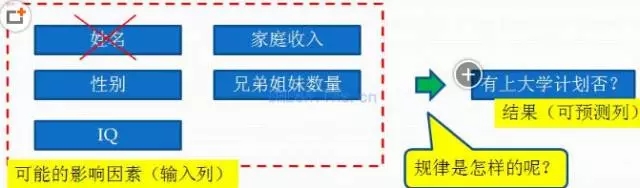 對原始數據表進行分析�����,我們可以推論出:家庭收入�����、性別��、兄弟姐妹數量�、IQ這些因素�,很可能會影響有否上大學計劃��。至于姓名會不會影響�����,我們可以用常識判斷應該不會����,故可以排除��。
這樣我們就可以確定輸入列有:家庭收入�����、性別����、兄弟姐妹數量����、IQ���,可預測列為:有上大學計劃否��。
數據挖掘的目標就是找出輸入列與可預測列的關系�����,只要找到這個規律�����,就可以提出針對性的建議���,也可以利用這個規律做預測�。
以上工作準備就緒后�����,我們就需要選擇合適的分析方法來數據挖掘了�。我們選擇“決策樹”的方法����,下面是決策樹的部分分析結果:
對原始數據表進行分析�����,我們可以推論出:家庭收入�����、性別��、兄弟姐妹數量�、IQ這些因素�,很可能會影響有否上大學計劃��。至于姓名會不會影響�����,我們可以用常識判斷應該不會����,故可以排除��。
這樣我們就可以確定輸入列有:家庭收入�����、性別����、兄弟姐妹數量����、IQ���,可預測列為:有上大學計劃否��。
數據挖掘的目標就是找出輸入列與可預測列的關系�����,只要找到這個規律�����,就可以提出針對性的建議���,也可以利用這個規律做預測�。
以上工作準備就緒后�����,我們就需要選擇合適的分析方法來數據挖掘了�。我們選擇“決策樹”的方法����,下面是決策樹的部分分析結果:
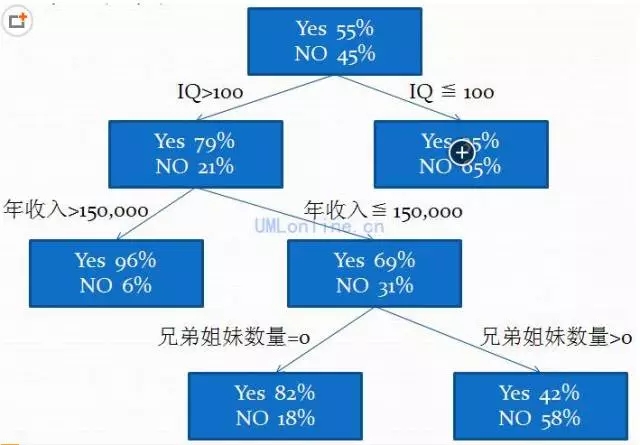 說明:
1.最上面的一個節點表示有55%的人有計劃上大學�,45%的人沒有計劃��。
2.第二層節點�,以IQ為條件進行劃分�����,IQ大于100的人中����,有上大學計劃的人有79%之多�����,而IQ小于等于100的人����,有上大學計劃的人只有35%��,這說明IQ是很重要的影響因素��。
3.第三層節點是年收入��,第四層是兄弟姐妹數量��。
4.決策樹算法會分析原始數據���,將影響程度最大的因素排在上面�,次之的因素排在后面���。
由上面的分析�,我們可以得到這樣的一些信息:
1.越是IQ高的越有上大學的計劃���。
2.家庭收入越高�,越有上大學計劃��。
3.兄弟姐妹越多��,上大學計劃就越微���。
4.性別沒有在這棵樹出現�,說明性別對有否上大學計劃沒有明顯影響���。
接下來我們就可以提出針對性的建議�����,以推動更多人考大學:
1.大學學位有限�����,目前重點應該是鼓勵更多的聰明的學生考大學����。
2.聰明的學生不計劃上大學���,主要原因是家庭收入低�����、兄弟姐妹多����,針對這樣的情況��,政府可考慮降低大學學費�,或對低收入�、多子女的家庭進行資助���。
總結一下數據挖掘的過程:
1.明確你的目標���,收集相關數據�����。 2.根據目標分析這些數據�,找出輸入列����、可預測列�����。 3.選擇合適的數據挖掘方法����。 4.分析數據挖掘結果�,給出建議���。 第2�����、3步可能需要不斷地嘗試和調試�,才能找到合適的分析結果����。
怎么樣�����?這個過程不簡單吧���?以上這個例子已經經過我的簡化和提煉�����,其目標就是讓大家能容易理解什么是數據挖掘�,實際工作中的數據挖掘難度是很高的�����,需要具備這些能力:
1.能深徹體會業務的要求�,能將客戶籠統的需求轉化為實在的工作指導��。
2.能分析出輸入列���、可預測列���。
3.熟悉各種數據挖掘方法�,會選擇合適的方法進行分析�。
4.能深入分析數據挖掘的結果���,綜合運用你的各種知識�,為客戶提出針對性的決策建議��。
常見的數據挖掘方法
常見的數據挖掘方法有分類��、聚類�、關聯�、回歸�、時間序列分析�、離散序列分成��、偏差分析��、貝葉斯����、神經網絡等等��。這些內容都涉及到深厚的數學知識�����,下面只是一些膚淺的介紹����,讓大家有個大概的認識���,為大家進一步學習打好基礎���。
數據挖掘算法之分類
例:某銀行每天收到很多信用卡辦理的申請���,為提高效率和準確性���,想應用數據挖掘技術來改善工作���,你會怎樣考慮呢����?
該銀行有大量的歷史數據�,將申請者分為高���、中��、低三種風險類型����,這樣輸入列就是申請者的學歷����、收入���、職業等信息����,而可預測列就是風險類型��。這樣對歷史數據進行數據挖掘后����,當有新的申請者提交資料�,系統就可以判斷該申請者風險類型為高�、中還是低了�����。
以上的算法就是“分類”����,該挖掘方法需人工指定類別���,然后找出一組屬性與該類別的關系����,利用這些關系來預測新的情況����。數據挖掘算法之聚類
說明:
1.最上面的一個節點表示有55%的人有計劃上大學�,45%的人沒有計劃��。
2.第二層節點�,以IQ為條件進行劃分�����,IQ大于100的人中����,有上大學計劃的人有79%之多�����,而IQ小于等于100的人����,有上大學計劃的人只有35%��,這說明IQ是很重要的影響因素��。
3.第三層節點是年收入��,第四層是兄弟姐妹數量��。
4.決策樹算法會分析原始數據���,將影響程度最大的因素排在上面�,次之的因素排在后面���。
由上面的分析�,我們可以得到這樣的一些信息:
1.越是IQ高的越有上大學的計劃���。
2.家庭收入越高�,越有上大學計劃��。
3.兄弟姐妹越多��,上大學計劃就越微���。
4.性別沒有在這棵樹出現�,說明性別對有否上大學計劃沒有明顯影響���。
接下來我們就可以提出針對性的建議�����,以推動更多人考大學:
1.大學學位有限�����,目前重點應該是鼓勵更多的聰明的學生考大學����。
2.聰明的學生不計劃上大學���,主要原因是家庭收入低�����、兄弟姐妹多����,針對這樣的情況��,政府可考慮降低大學學費�,或對低收入�、多子女的家庭進行資助���。
總結一下數據挖掘的過程:
1.明確你的目標���,收集相關數據�����。 2.根據目標分析這些數據�,找出輸入列����、可預測列�����。 3.選擇合適的數據挖掘方法����。 4.分析數據挖掘結果�,給出建議���。 第2�����、3步可能需要不斷地嘗試和調試�,才能找到合適的分析結果����。
怎么樣�����?這個過程不簡單吧���?以上這個例子已經經過我的簡化和提煉�����,其目標就是讓大家能容易理解什么是數據挖掘�,實際工作中的數據挖掘難度是很高的�����,需要具備這些能力:
1.能深徹體會業務的要求�,能將客戶籠統的需求轉化為實在的工作指導��。
2.能分析出輸入列���、可預測列���。
3.熟悉各種數據挖掘方法�,會選擇合適的方法進行分析�。
4.能深入分析數據挖掘的結果���,綜合運用你的各種知識�,為客戶提出針對性的決策建議��。
常見的數據挖掘方法
常見的數據挖掘方法有分類��、聚類�、關聯�、回歸�、時間序列分析�、離散序列分成��、偏差分析��、貝葉斯����、神經網絡等等��。這些內容都涉及到深厚的數學知識�����,下面只是一些膚淺的介紹����,讓大家有個大概的認識���,為大家進一步學習打好基礎���。
數據挖掘算法之分類
例:某銀行每天收到很多信用卡辦理的申請���,為提高效率和準確性���,想應用數據挖掘技術來改善工作���,你會怎樣考慮呢����?
該銀行有大量的歷史數據�,將申請者分為高���、中��、低三種風險類型����,這樣輸入列就是申請者的學歷����、收入���、職業等信息����,而可預測列就是風險類型��。這樣對歷史數據進行數據挖掘后����,當有新的申請者提交資料�,系統就可以判斷該申請者風險類型為高�、中還是低了�����。
以上的算法就是“分類”����,該挖掘方法需人工指定類別���,然后找出一組屬性與該類別的關系����,利用這些關系來預測新的情況����。數據挖掘算法之聚類
“聚類”與“分類”很相似����,同樣是找出一組屬性與類別的關系�,不同的是這類別不是事先指定的�����,而是由數據挖掘自己找出分類�。
例:某公司收集了很多客戶的資料�,記錄了客戶的年齡和收入���。該公司相對這些數據進行分析�����,找出可以重點營銷的客戶對象�。我們可指定輸入列為年齡和收入��,經過聚類數據挖掘后����,發現客戶群可以劃分為三個群體:低收入年輕客戶����、高收入中年客戶��、收入相對低的年老客戶�。根據這樣的分析結果�����,公司可采取決策��,重點針對高收入中年客戶進行營銷活動�����。
數據挖掘算法之關聯
例:在一家超市里�,有一個有趣的現象:尿布和啤酒赫然擺在一起出售���。但是這個奇怪的舉措卻使尿布和啤酒的銷量雙雙增加了����。這不是一個笑話����,而是發生在美國沃爾瑪連鎖店超市的真實案例���,并一直為商家所津津樂道�。原來�,美國的婦女們經常會囑咐她們的丈夫下班以后要為孩子買尿布��。而丈夫在買完尿布之后又要順手買回自己愛喝的啤酒��,因此啤酒和尿布在一起購買的機會還是很多的�����。
上述這個例子經常會被人拿來說�,但很少人會舉一反三地應用這個例子���。我們有很多超市記錄了大量的交易數據���,只要對這些交易數據做一下關聯分析����,就很可能會得到不少價值巨大的商業機會���。上述這個“尿布+啤酒”的例子���,就是應用了關聯分析�,發現尿布和啤酒兩個東西經常被一起賣掉�����。關聯分析主要用來找出某些東西“擺在一起“的機會�。我們上網上商城購買東西��,你每選擇一個商品���,就可能會向你推銷一堆別的商品���,這很可能就是關聯分析在“作怪”�����。
數據挖掘算法之回歸
變量X��、Y可能存在關系��,我們可以將大量的(X����、Y)繪制到一張圖上��,形成一張散點圖��。如果這些散點更好都在一條直線附近��,那么這條直線的方程就可以近似代表X與Y的關系�����。
所謂的回歸���,就是要找到一個函數代表變量X1����,X2�,X3�����,…與Y的關系��,該函數所繪制出來的曲線�����,能盡量擬合這些“散點”���。
下圖是某軟件公司某項目測試時間與發現缺陷數量的關系圖:
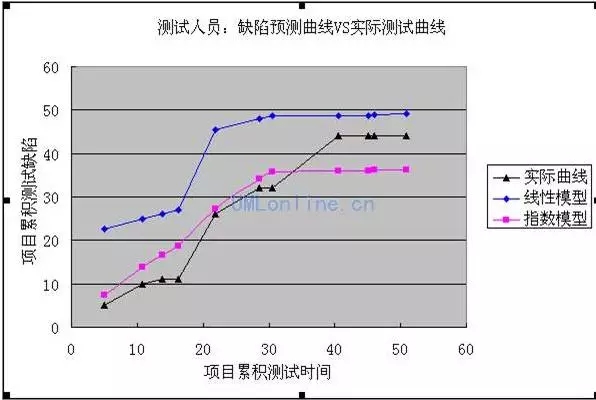 回歸可分為線性回歸和非線性回歸�,線性回歸比較容易操作����,但一般情況下數據很難是線性的�,而非線性回歸就超復雜了�。
上圖的線性模型采用的是多階段的線性回歸�����,指數模型采用的是多階段的指數回歸����,而黑色曲線代表的是真實數據�,從圖中看��,似乎指數模型的吻合度更高一點�����。
數據挖掘算法之時間序列分析
例1:炒股的人都想預測明天是漲還是跌����,實際上我們已經積累了大量的歷史數據����,說不定還是可以預測的����!某股票已經連續漲了3天���,明天會不會再漲呢�?某股票連續跌了7天了����,明天應該不會再跌了吧�?
例2:很多商家會在某些節假日時����,重點銷售某些產品�����,以求可以賣出更多���,圣誕節快到了��,應該主推什么產品好呢��?實際上各商家的收款系統中����,記錄了大量的與時間相關的銷售數據�����,如果對這些數據做一下時間序列分析���,說不定能找到重大商機���。
時間序列分析��,輸入列都是與時間相關的數據�����,同時需要考慮季節��、歷史等因素�����,這樣就可以預測某個時間會怎樣了����。
數據挖掘算法之離散序列分析
某網站對訪問者的操作進行了統計����,如下:
回歸可分為線性回歸和非線性回歸�,線性回歸比較容易操作����,但一般情況下數據很難是線性的�,而非線性回歸就超復雜了�。
上圖的線性模型采用的是多階段的線性回歸�����,指數模型采用的是多階段的指數回歸����,而黑色曲線代表的是真實數據�,從圖中看��,似乎指數模型的吻合度更高一點�����。
數據挖掘算法之時間序列分析
例1:炒股的人都想預測明天是漲還是跌����,實際上我們已經積累了大量的歷史數據����,說不定還是可以預測的����!某股票已經連續漲了3天���,明天會不會再漲呢�?某股票連續跌了7天了����,明天應該不會再跌了吧�?
例2:很多商家會在某些節假日時����,重點銷售某些產品�����,以求可以賣出更多���,圣誕節快到了��,應該主推什么產品好呢��?實際上各商家的收款系統中����,記錄了大量的與時間相關的銷售數據�����,如果對這些數據做一下時間序列分析���,說不定能找到重大商機���。
時間序列分析��,輸入列都是與時間相關的數據�����,同時需要考慮季節��、歷史等因素�����,這樣就可以預測某個時間會怎樣了����。
數據挖掘算法之離散序列分析
某網站對訪問者的操作進行了統計����,如下:
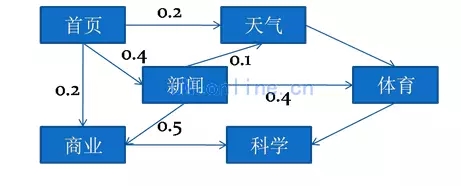 說明:
1.訪問者進入首頁后����,有20%會進入天氣頁面���,40%進入新聞頁面��,20%進入商業頁面��。
2.從首頁進入新聞頁面的機會是40%��,而從天氣進入新聞的機會是10%��。
以上的分析對于優化網站是很有幫助的��,上述的分析用到了離散序列分析技術��。
離散序列分析�����,輸入列是一系列有“次序”的數據���,通過這一系列有次序的數據預測另外一個數據情況��。
數據挖掘算法之偏差分析
例:某銀行有信用卡異常使用情況的監控系統�,如果發現某些用卡行為與客戶往常習慣不一樣時����,會發出警告�。
信用卡每次使用情況�����,包括時間����、地點��、金額��、商戶等信息都會記錄下來��。利用正常的歷史數據對系統進行訓練�����,告訴系統這些是“正?����!钡氖褂们闆r����,當出現新的用卡記錄與這些正常使用的特征不符時�,則可以發出警告�。偏差分析的原理就是用正常的數據去訓練系統�����,由系統去判斷新數據是否在正常范圍�����?有沒有偏差��?
軟件項目管理如果達到CMMI4級或以上的層次�����,就會使用基線來管理項目�,基線上下限范圍內可認為是“正?!钡?���,如果超出上下限���,則認為是“偏差”���,需要分析原因并采取措施��。這種用基線來管理項目�����,其實也是一種數據挖掘算法-偏差分析���。
數據挖掘算法之貝葉斯
貝葉斯算法是一種根據歷史事件發生的概率來推測將來的算法���,由偉大的數學家Thomas Bayes所創建的���。Thomas Bayes�����,1702年出生于英國倫敦�����。
該算法的原理是這樣的:如果事情A���、事情B�、事情C����、…����、這些事情發生了�����,那么事情X發生的幾率是多少�。前面這些事情叫做前提事情��,可以是一個到多個��,前提事情越多分析起來就越復雜但會更加準確���。
舉個例子:據說麥當勞當年發現����,如果顧客購買了漢堡包和薯條���,那么顧客再購買可樂的機會是70%�����,于是麥當勞就將這三個產品捆綁在一起作為套餐�,于是銷量大增�。對于這個案例���,前提事件就是購買漢堡包和購買薯條�����,要預測的是顧客會不會買可樂�����,預測結果就是有70%機會會買�。我們可以利用貝葉斯原理來進行數據挖掘��。
數據挖掘算法之神經網絡
人腦其實是由數量龐大的神經細胞組成的����,神經細胞龐大的數量及復雜的結構�,讓人類充滿了智慧����。人一出世���,腦袋是一片空白的�,當我們學會了某樣東西的時候���,我們會對起進行推演和歸納�����。比方說我們認識了這是一條狗�����,當我們見到另外一條不同品種狗的時候���,我們會判斷這也是一條狗��。而計算機的判斷一般來說就比較死板了�����,如果有細微的偏差就會認不出來�。
神經網絡算法其實就是通過計算機來構造類似于人腦的神經細胞網絡(當然該網絡無論如何不能跟人腦相比)��,通過一些訓練�,能讓該網絡能識別某一類事物���。文字識別�����、指紋識別等都是應用了神經網絡技術的�。
通過數據訓練���,我們可以在輸入列與可預測列之間找到合適的神經網絡��,然后通過這個網絡對新情況進行判斷�。
數據挖掘技術
數據挖掘涉及到很多知識���,涉及到數學��、機器學習��、數據庫等領域�。
數學方面的知識只要是概率與統計方面的知識���,回歸����、時序�、決策樹�、貝葉斯等數據挖掘算法都是依賴于這些數學知識的�。
電腦的發展讓機器學習發揮出無窮的威力�����,神經網絡���、遺傳算法是兩種倚賴于計算機學習的算法����。
數據倉庫��、數據集市����、數據立方體的存儲技術等數據庫技術的發展���,讓數據挖掘可以處理越來越大量的數據����。
你如果對數據挖掘感興趣��,那么請努力學習以上提到的知識吧�!
說明:
1.訪問者進入首頁后����,有20%會進入天氣頁面���,40%進入新聞頁面��,20%進入商業頁面��。
2.從首頁進入新聞頁面的機會是40%��,而從天氣進入新聞的機會是10%��。
以上的分析對于優化網站是很有幫助的��,上述的分析用到了離散序列分析技術��。
離散序列分析�����,輸入列是一系列有“次序”的數據���,通過這一系列有次序的數據預測另外一個數據情況��。
數據挖掘算法之偏差分析
例:某銀行有信用卡異常使用情況的監控系統�,如果發現某些用卡行為與客戶往常習慣不一樣時����,會發出警告�。
信用卡每次使用情況�����,包括時間����、地點��、金額��、商戶等信息都會記錄下來��。利用正常的歷史數據對系統進行訓練�����,告訴系統這些是“正?����!钡氖褂们闆r����,當出現新的用卡記錄與這些正常使用的特征不符時�,則可以發出警告�。偏差分析的原理就是用正常的數據去訓練系統�����,由系統去判斷新數據是否在正常范圍�����?有沒有偏差��?
軟件項目管理如果達到CMMI4級或以上的層次�����,就會使用基線來管理項目�,基線上下限范圍內可認為是“正?!钡?���,如果超出上下限���,則認為是“偏差”���,需要分析原因并采取措施��。這種用基線來管理項目�����,其實也是一種數據挖掘算法-偏差分析���。
數據挖掘算法之貝葉斯
貝葉斯算法是一種根據歷史事件發生的概率來推測將來的算法���,由偉大的數學家Thomas Bayes所創建的���。Thomas Bayes�����,1702年出生于英國倫敦�����。
該算法的原理是這樣的:如果事情A���、事情B�、事情C����、…����、這些事情發生了�����,那么事情X發生的幾率是多少�。前面這些事情叫做前提事情��,可以是一個到多個��,前提事情越多分析起來就越復雜但會更加準確���。
舉個例子:據說麥當勞當年發現����,如果顧客購買了漢堡包和薯條���,那么顧客再購買可樂的機會是70%�����,于是麥當勞就將這三個產品捆綁在一起作為套餐�,于是銷量大增�。對于這個案例���,前提事件就是購買漢堡包和購買薯條�����,要預測的是顧客會不會買可樂�����,預測結果就是有70%機會會買�。我們可以利用貝葉斯原理來進行數據挖掘��。
數據挖掘算法之神經網絡
人腦其實是由數量龐大的神經細胞組成的����,神經細胞龐大的數量及復雜的結構�,讓人類充滿了智慧����。人一出世���,腦袋是一片空白的�,當我們學會了某樣東西的時候���,我們會對起進行推演和歸納�����。比方說我們認識了這是一條狗�����,當我們見到另外一條不同品種狗的時候���,我們會判斷這也是一條狗��。而計算機的判斷一般來說就比較死板了�����,如果有細微的偏差就會認不出來�。
神經網絡算法其實就是通過計算機來構造類似于人腦的神經細胞網絡(當然該網絡無論如何不能跟人腦相比)��,通過一些訓練�,能讓該網絡能識別某一類事物���。文字識別�����、指紋識別等都是應用了神經網絡技術的�。
通過數據訓練���,我們可以在輸入列與可預測列之間找到合適的神經網絡��,然后通過這個網絡對新情況進行判斷�。
數據挖掘技術
數據挖掘涉及到很多知識���,涉及到數學��、機器學習��、數據庫等領域�。
數學方面的知識只要是概率與統計方面的知識���,回歸����、時序�、決策樹�、貝葉斯等數據挖掘算法都是依賴于這些數學知識的�。
電腦的發展讓機器學習發揮出無窮的威力�����,神經網絡���、遺傳算法是兩種倚賴于計算機學習的算法����。
數據倉庫��、數據集市����、數據立方體的存儲技術等數據庫技術的發展���,讓數據挖掘可以處理越來越大量的數據����。
你如果對數據挖掘感興趣��,那么請努力學習以上提到的知識吧�!
數據挖掘是高精尖的技術���,是改變世界的一種技術����,希望我們能涌現出一批批實實在在的數據挖掘精英����,改變我們的生活����,改變我們的世界����!
文 | 創新工場創業課堂(敏捷課程)講師 張傳波
責任編輯 | 李佳燕
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
