第 1 部分:數據基礎設施的背后哲學
在 Airbnb 我們提倡數據文化并使用數據作為關鍵輸入去決策����。跟蹤指標��,通過實驗驗證假設��,建立機器學習模型和深入挖掘商業洞察是我們快速聰明前進的關鍵�。
經過多年的進化��,我們覺得數據基礎設施服務穩定����,可靠��,可擴展�,因此是一個很好的機會來分享我們的經驗給社區����。在接下來的幾周內���,我們將發布一系列突出我們的分布式架構和工具組件的博客文章���。由于開源貢獻者提供了許多我們每天使用的基礎系統�����,使我們不僅樂意分享在公共 GitHub 的項目����,而且還會聊我們一路上學到的東西��。
了解我們數據基礎設施的一些非正式理念:
放眼開源世界:在開源社區中數據基礎設施有很多好的資源�����,我們盡量采用這些系統�。此外�����,如果我們建立一些對自己有用又對社有回報的東西���。
首選標準組件和方法:有些時候是發明一種全新的一塊基礎設施是合理的��,但很多時候��,這沒有很好的利用資源���。建立一個獨特解決方案是靠直覺還是采用現有的是非常重要的�,而靠直覺必須正確考慮維護支持的隱性成本�����。
確保它能夠擴展:我們發現數據與業務不是線性增長��,但隨著技術員工建立新的產品和在業務采取新方式后�,將超線性增長���。
通過傾聽你的同事解決實際問題:與公司的數據用戶溝通是了解路線圖的重要組成部分���。與亨利·福特的口號一致�����,我們必須在找更快的馬與造汽車上保持平衡 – 但首先要聽你的客戶�����。
留有一定的余量:我們超額認購資源如集群�����,促進探索的文化�����。對基礎設施團隊實現資源利用最大化還高興的太早�,但我們的假設是�,在存儲中發現了一個新的商業機會將抵消了這些額外的機器費用��。
第 2 部分:基礎設施概況
這里是我們的基礎設施的主要部件的簡圖����。
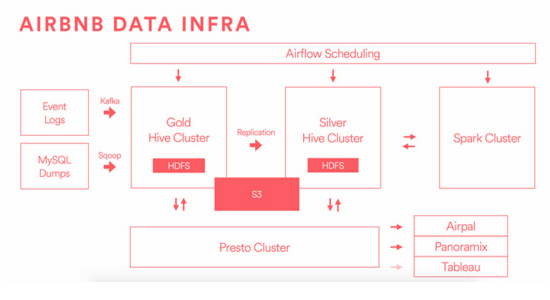
源數據進入我們的系統有兩個主要渠道:源代碼發送 Kafka 事件和線上數據庫將 AWS RDS 中的存儲導出����,再通過 Sqoop 傳遞�。
這里數據源包含用戶的活動事件數據和快照源數據����,發送到 “金” 集群存儲����,并開始運行我們的提取�����,轉換和加載(ETL)�����。在此步驟中����,我們針對業務邏輯���,匯總表格����,并執行數據質量檢查�。
在上面的圖中����,有 “金” 和 “銀” 兩個獨立集群���,我們將在后面詳細描述�。分離原因是保證計算和存儲資源的隔離����,如果一個掛了可以做災難恢復�。這種架構提供了一個理想環境����,最重要的工作嚴格保障 SLA(服務保證協議)�,避免資源密集型即席查詢的影響����。我們把 ‘銀’ 集群作為一個生產環境�,但是放寬保證�,可以承受資源密集型查詢��。
通過兩個集群我們獲得隔離力量�����,在管理大量的數據復制并維持動態系統之間有同步的成本���?��!敖稹?是我們的真正來源��,我們將復制 “金” 數據的每一位到 “銀”��?���!般y” 集群上生成的數據不會被復制回 “金”���,所以你可以認為這是 “銀” 作為一個超集集群�����,是單向復制方案�。因為我們的很多分析和報告從 “銀” 簇發��,當 “金” 有新數據產生��,我們盡快復制它到 “銀”���,去保證其他工作刻不容緩運行���。更關鍵的是�����,如果我們更新預先存在的 “金” 集群上的數據���,我們必須小心的更新并同步傳播給 “銀”����。這種復制優化問題并沒有一個開源的很好解決方案����,所以我們建立了一套新的工具���,我們會以后更詳細地介紹���。
我們改進 HDFS 已經取得了很大效果����,并更準確地用 Hive 管理表����,作為我們中心源的數據��。倉庫的質量和完整性取決于數據不變的����,繼承數據可通過重新推導計算的 – 使用分區 Hive 表對這個目標非常重要�����。此外�,我們不鼓勵數據系統的擴散�����,不希望維護單獨的基礎設施��,比如我們的源數據和我們終端用戶報告�。根據我們的經驗����,這些中間系統混淆真理的來源�,增加 ETL 的管理負擔�����,難以跟蹤從原始數據一路上來自的迭代指標�����。我們不跑 Oracle��,Teradata�,Vertica�����,Redshift 等����,而是使用 Presto 對所有 Hive 管理的表做即席查詢�。我們都希望在不久的將來����,聯通 Presto 和 Tableau��。
其他的一些在圖中要注意的東西�����,包括 Airpal�,使用 Presto 支持基于 Web 查詢執行的工具�,我們搭建并開源了�����。這是在數據倉庫即席 SQL 查詢�����,1/3 以上的所有員工都使用該工具運行查詢主界面��。作業調度功能就是通 Airflow�����,一個以編程方式編寫��,調度和監控的平臺��,可以運行在 Hive��,Presto����,Spark�����,MySQL 的數據管道等����。我們在邏輯上跨集群共享 Airflow�,但物理作業運行在合適的集群機器上����。Spark 集群是工程師和數據科學家機器學習工作偏愛的另一處理工具��,對流處理非常有用�����。你可以在 Aerosolve 查看我們在機器學習上的努力���。 S3 是一個獨立的存儲系統����,我們可以從 HDFS 數據得到便宜的長期存儲�。Hive 管理的表可以對自己存儲改變��,并指向 S3 的文件�����,容易訪問和管理元數據�。
第 3 部分:Hadoop 集群的詳細演化
今年我們從架構不佳的集群上進行遷移����,被稱為 “Pinky 與 Brain”�,放到上述的 “金銀” 系統中去���。兩年前��,我們從 Amazon EMR 移到一組運行在 HDFS 300 TB 數據的 EC2 實例�。今天���,我們有兩個獨立的 HDFS 集群�����,數據 11 PB���,我們 S3 存儲 PB 級別�。有了這樣的背景�,我們來解決問題:
1)在 Mesos 架構上運行一個獨特的 Hadoop
早期的 Airbnb 工程師們在一個叫做 Mesos 上�,其中規定了部署跨多個服務器的配置��。我們使用 AWS 上 c3.8xlarge 的單一集群�。每個 bucket 是 3T 的 EBS��,并跑了所有的 Hadoop�����,Hive�,Presto�,Chronos 的���,和 Mesos 上的 Marathon���。
需要明確的是��,許多公司都使用 Mesos 實施新穎的解決方案來管理大型重要基礎設施����。但是�����,我們的小團隊決定運行更加規范����,無處不在的部署�,減少我們花在運營和調試的時間�����。
Mesos 上 Hadoop 問題:
很少能見到工作運行和日志文件
很少能見到集群健康狀態
Hadoop 在 Mesos 只能運行 MR1
Task Tracker 競爭的性能問題
集群的低利用率
高負荷���,難調試系統
缺乏整合 Kerberos 安全
解決方法:答案是簡單地轉移到一個 “標準” 棧��。我們很樂意從數百或數千公司學習操作大型集群����,而不是試圖去創造一種新的解決方案�。
2)遠程讀取和寫入
之前通過存儲在 EBS(彈性塊存儲)上訪問我們所有 HDFS 數據�,我們發送到公共 Amazon EC2 運行查詢網絡數據���。
Hadoop 是為特定硬件搭建���,預先在本地磁盤讀寫����,所以這是一個設計不匹配����。
關于遠程讀寫�����,我們曾錯誤地選擇了 AWS 在三個不同的可用性區域分割我們的數據存儲��,而它們在一個區域內���。每個可用區被定為自己的 “機架”�,3 個副本分別存放在不同的機架�,因此遠程讀寫操作都不斷發生���。這又是一個設計缺陷��,導致緩慢的數據傳輸��,當一臺機器丟失或損壞塊時候��,遠程拷貝就隨時發生��。
解決方法:使用本地存儲專門實例�����,并在一個可用性區域中運行�,而不是讓 EBS 修正這些問題��。
3)同構機器上工作負載的異構
縱觀我們的工作量���,我們發現��,我們的構件有不同的要求�����。我們的 Hive/ Hadoop/ HDFS 機器需大量的儲存空間�����,但并不需要多少內存或 CPU����。Presto 和 Spark 渴望內存和高處理能力�,但并不需要多大的存儲��。通過 3TB EBS 支持運行 c3.8xlarge 被證明是存儲非常昂貴�,也是限制因素�����。
解決方法:一旦我們遷移出 Mesos 架構�,我們能選擇不同類型的機器運行各種集群����,例如使用 r3.8xlarge 實例運行 Spark����。亞馬遜發布新生代 “D 系列” 的實例���,我們正在評估�,這從成本角度所作的過渡更可取的���。從 c3.8xlarge 機器每個節點的遠程存儲 3TB 轉變到 d2.8xlarge 機器上本地存儲 48TB 是非常有吸引力����,會為我們在未來三年節省了數百萬美元�。
4)HDFS Federation
我們一直在運行Federation HDFS 集群���,數據共享物理塊池���,但每個邏輯集群分離 mapper 和 reducer 集合��。這讓我們可以通過 query 查詢訪問任何一塊數據�����,提高終端用戶體驗����,但我們發現��,Federation 并沒有得到廣泛的支持�,被某些專家認為是實驗性和不可靠的��。
解決方法:移到一個完全不同的 HDFS 節點���,而不是運行 Federation�,做到在機器水平的真正隔離�,這也提供了更好的災難恢復機制����。
5)系統監控是累贅
一個獨特的基礎設施體系最嚴重的問題是創建自定義監視和報警集群����。 Hadoop����,Hive�,HDFS 是復雜的系統�����,容易發生眾多故障��。試圖預測所有故障狀態��,并設置合理的門檻是相當有挑戰性���。
解決方法:我們簽了 Cloudera 的支持合同��,用他們的專業知識來獲得在架構和操作這些大型系統����,以及最重要的通過使用 Cloudera 的管理器工具����,減少我們的維護負擔���。接入到我們內部系統����,大大減少了我們的監控和報警負擔�,這樣我們花很少的時間進行系統維護和警報����。
結論
在我們舊的集群上評估錯誤和低效率�,開始著手系統地解決這些問題�����。去遷移 PB 數據和數百個用戶作業是一個漫長的過程����,因為還不破壞我們現有服務;我們將單獨把一些工具貢獻給開源社區�����。
現在����,遷移完成后�,我們已經大大減少了平臺事故和故障的數量���。不難想象我們在不成熟的平臺上處理的 bug 和問題�,但系統現在基本上是穩定的��。另一個好處是��,當我們雇傭新工程師加入我們的團隊�,上手很快因為系統也被其他公司采用���。
最后����,因為我們有機會在 “金銀” 系統去設置新鮮的架構��,搭建所有新實例�����,用合理的方式添加 IAM 角色來管理安全性�。這意味著在集群之上提供更為精密的訪問控制層����,集成管理我們所有的機器���。











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
