區分兩個概念:
hard clustering:一個文檔要么屬于類w����,要么不屬于類w�����,即文檔對確定的類w是二值的1或0�。
soft clustering:一個文檔可以屬于類w1��,同時也可以屬于w2��,而且文檔屬于一個類的值不是0或1���,可以是0.3這樣的小數�����。
K-Means就是一種hard clustering�����,所謂K-means里的K就是我們要事先指定分類的個數���,即K個���。
k-means算法的流程如下:
1)從N個文檔隨機選取K個文檔作為初始質心
2)對剩余的每個文檔測量其到每個質心的距離�����,并把它歸到最近的質心的類
3)重新計算已經得到的各個類的質心
4)迭代2~3步直至滿足既定的條件��,算法結束
在K-means算法里所有的文檔都必須向量化��,n個文檔的質心可以認為是這n個向量的中心�����,計算方法如下:
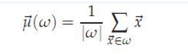
這里加入一個方差RSS的概念:
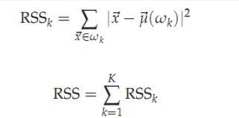
RSSk的值是類k中每個文檔到質心的距離�,RSS是所有k個類的RSS值的和�����。
算法結束條件:
1)給定一個迭代次數����,達到這個次數就停止�,這好像不是一個好建議����。
2)k個質心應該達到收斂���,即第n次計算出的n個質心在第n+1次迭代時候位置不變���。
3)n個文檔達到收斂���,即第n次計算出的n個文檔分類和在第n+1次迭代時候文檔分類結果相同�����。
4)RSS值小于一個閥值���,實際中往往把這個條件結合條件1使用
回過頭用RSS討論質心的計算方法是否合理
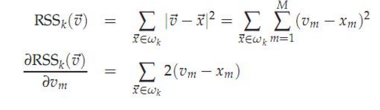
為了取得RSS的極小值��,RSS對質心求偏導數應該為0����,所以得到質心
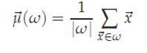
可見�����,這個質心的選擇是合乎數學原理的��。
K-means方法的缺點是聚類結果依賴于初始選擇的幾個質點位置���,看下面這個例子:
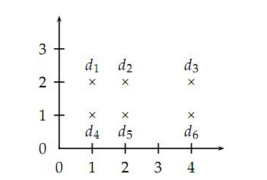
如果使用2-means方法��,初始選擇d2和d5那么得到的聚類結果就是{d1�,d2����,d3}{d4����,d5����,d6}����,這不是一個合理的聚類結果
解決這種初始種子問題的方案:
1)去處一些游離在外層的文檔后再選擇
2)多選一些種子���,取結果好的(RSS?。┑腒個類繼續算法
3)用層次聚類的方法選擇種子�。我認為這不是一個合適的方法�����,因為對初始N個文檔進行層次聚類代價非常高��。
以上的討論都是基于K是已知的����,但是我們怎么能從隨機的文檔集合中選擇這個k值呢�?
我們可以對k去1~N分別執行k-means�����,得到RSS關于K的函數下圖:
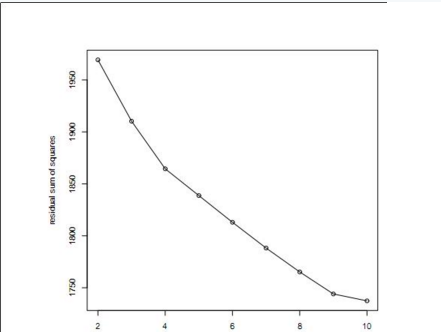
當RSS由顯著下降到不是那么顯著下降的K值就可以作為最終的K�,如圖可以選擇4或9�。
四��、算法及示例
k 均值算法的計算過程非常直觀:
1��、從D 中隨機取k 個元素���,作為k 個簇的各自的中心��。
2�、分別計算剩下的元素到k 個簇中心的相異度�����,將這些元素分別劃歸到相異度最低的簇��。
3�����、根據聚類結果�,重新計算k 個簇各自的中心���,計算方法是取簇中所有元素各自維度的算術平均數��。
4�����、將D 中全部元素按照新的中心重新聚類�����。
5���、重復第4 步���,直到聚類結果不再變化���。
6�、將結果輸出�。
由于算法比較直觀����,沒有什么可以過多講解的����。下面�,我們來看看k-means 算法一個有趣的應用示例:中國男足近幾年到底在亞洲處于幾流水平��?
今年中國男足可算是杯具到家了����,幾乎到了過街老鼠人人喊打的地步���。對于目前中國男足在亞洲的地位��,各方也是各執一詞�����,有人說中國男足亞洲二流�����,有人說三流�����,還有人說根本不入流���,更有人說其實不比日韓差多少�,是亞洲一流��。既然爭論不能解決問題�����,我們就讓數據告訴我們結果吧�。
下圖是采集的亞洲15 只球隊在2005 年-2010 年間大型杯賽的戰績(由于澳大利亞是后來加入亞足聯的�,所以這里沒有收錄)�。
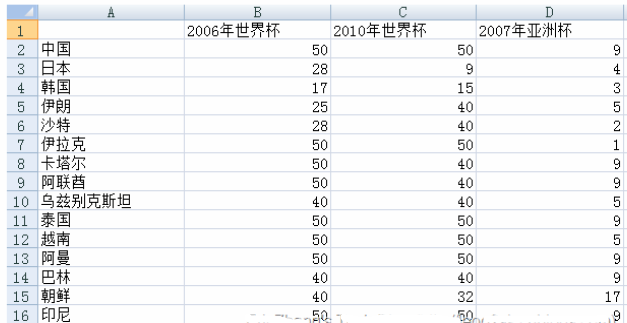
其中包括兩次世界杯和一次亞洲杯���。我提前對數據做了如下預處理:對于世界杯����,進入決賽圈則取其最終排名�,沒有進入決賽圈的��,打入預選賽十強賽賦予40��,預選賽小組未出線的賦予50�。對于亞洲杯���,前四名取其排名��,八強賦予5�,十六強賦予9�����,預選賽沒出現的賦予17�。這樣做是為了使得所有數據變為標量��,便于后續聚類���。
下面先對數據進行[0,1]規格化����,下面是規格化后的數據:
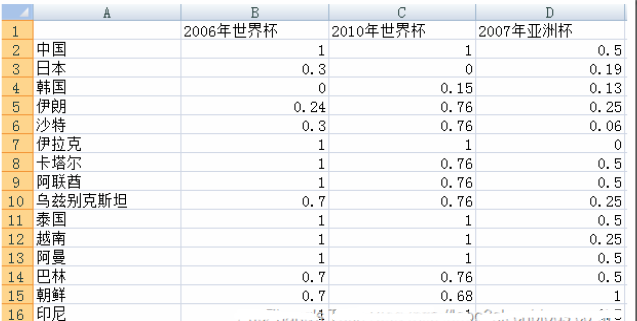
其中包括兩次世界杯和一次亞洲杯�。我提前對數據做了如下預處理:對于世界杯�����,進入決賽圈則取其最終排名����,沒有進入決賽圈的�����,打入預選賽十強賽賦予40�����,預選賽小組未出線的賦予50����。對于亞洲杯����,前四名取其排名�,八強賦予5���,十六強賦予9�����,預選賽沒出現的賦予17�。這樣做是為了使得所有數據變為標量����,便于后續聚類�。
下面先對數據進行[0,1]規格化���,下面是規格化后的數據:
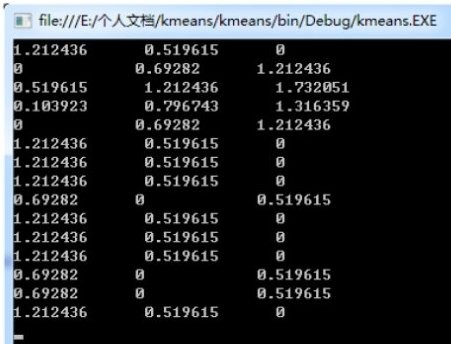
從做到右依次表示各支球隊到當前中心點的歐氏距離�,將每支球隊分到最近的簇��,可對各支球隊做如下聚類:
中國C����,日本A��,韓國A��,伊朗A���,沙特A���,伊拉克C�����,卡塔爾C����,阿聯酋C�����,烏茲別克斯坦B����,泰國C�����,越南C����,阿曼C�,巴林B�����,朝鮮B��,印尼C�。
第一次聚類結果:
A:日本���,韓國��,伊朗����,沙特��;
B:烏茲別克斯坦�����,巴林����,朝鮮�����;
C:中國�,伊拉克����,卡塔爾�,阿聯酋��,泰國��,越南���,阿曼�,印尼�����。
下面根據第一次聚類結果�,調整各個簇的中心點����。
A 簇的新中心點為: {(0.3+0+0.24+0.3)/4=0.21���,(0+0.15+0.76+0.76)/4=0.4175,(0.19+0.13+0.25+0.06)/4=0.1575} = {0.21, 0.4175, 0.1575}
用同樣的方法計算得到B 和C 簇的新中心點分別為{0.7, 0.7333, 0.4167}�,{1, 0.94,0.40625}���。
用調整后的中心點再次進行聚類����,得到:
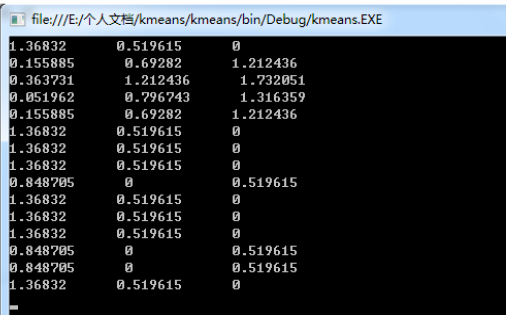
第二次迭代后的結果為:
中國C����,日本A�,韓國A�,伊朗A����,沙特A�����,伊拉克C���,卡塔爾C�����,阿聯酋C����,烏茲別克斯坦B�,泰國C����,越南C�����,阿曼C��,巴林B�,朝鮮B��,印尼C���。
結果無變化��,說明結果已收斂�,于是給出最終聚類結果:
亞洲一流:日本�����,韓國�,伊朗��,沙特
亞洲二流:烏茲別克斯坦����,巴林����,朝鮮
亞洲三流:中國���,伊拉克���,卡塔爾��,阿聯酋��,泰國����,越南����,阿曼����,印尼
看來數據告訴我們��,說國足近幾年處在亞洲三流水平真的是沒有冤枉他們����,至少從國際杯賽戰績是這樣的��。
其實上面的分析數據不僅告訴了我們聚類信息���,還提供了一些其它有趣的信息����,例如從中可以定量分析出各個球隊之間的差距����,例如�����,在亞洲一流隊伍中����,日本與沙特水平最接近���,而伊朗則相距他們較遠�����,這也和近幾年伊朗沒落的實際相符�����。另外�,烏茲別克斯坦和巴林雖然沒有打進近兩屆世界杯�����,不過憑借預算賽和亞洲杯上的出色表現占據B 組一席之地����,而朝鮮由于打入了2010 世界杯決賽圈而有幸進入B 組��,可是同樣奇跡般奪得2007年亞洲杯的伊拉克卻被分在三流�,看來亞洲杯冠軍的分量還不如打進世界杯決賽圈重啊�����。其它有趣的信息��,有興趣的朋友可以進一步挖掘�。











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
