R語言數據挖掘實戰案例:電商評論情感分析
隨著網上購物的流行,各大電商競爭激烈,為了提高客戶服務質量,除了打價格戰外,了解客戶的需求點,傾聽客戶的心聲也越來越重要,其中重要的方式 就是對消費者的文本評論進行數據挖掘.今天通過學習《R語言數據挖掘實戰》之案例:電商評論與數據分析���,從目標到操作內容分享給大家�����。
本文的結構如下

1.要達到的目標
通過對客戶的評論,進行一系列的方法進行分析,得出客戶對于某個商品的各方面的態度和情感傾向,以及客戶注重商品的哪些屬性,商品的優點和缺點分別是什么,商品的賣點是什么,等等..
2.文本挖掘主要的思想.
由于語言數據的特殊性,我們主要是將一篇句子中的關鍵詞提取出來,從而將一個評論的關鍵詞也提取出來,然后根據關鍵詞所占的權重,這里我們用空間向量的模型,將每個特征關鍵詞轉化為數字向量,然后計算其距離,然后聚類,得到情感的三類,分別是正面的,負面的,中性的.用以代表客戶對商品的情感傾向.
3.文本挖掘的主要流程:
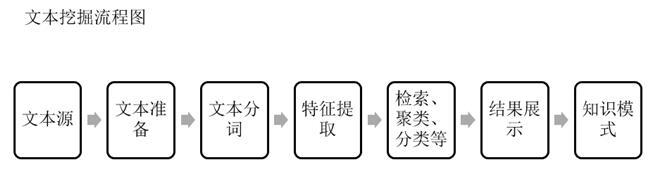
4.案例流程簡介與原理介紹及軟件操作
4.1數據的爬取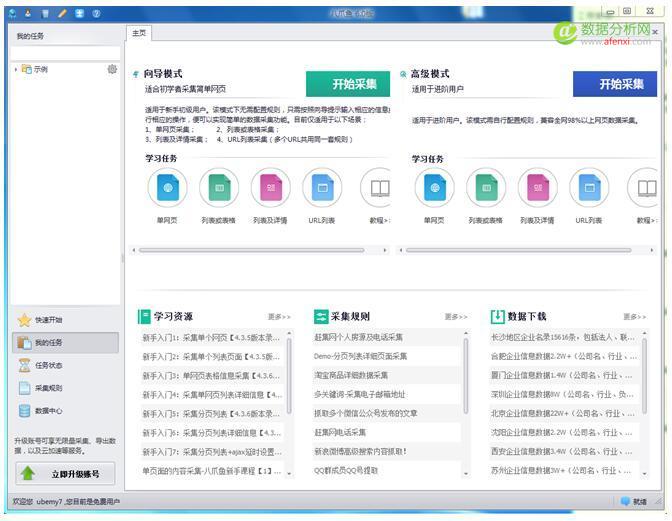
首先下載八爪魚軟件,鏈接是http://www.bazhuayu.com/download,下載安裝后,注冊賬號登錄, 界面如上:
點擊快速開始—新建任務,輸入任務名點擊下一步,打開京東美的熱水器頁面
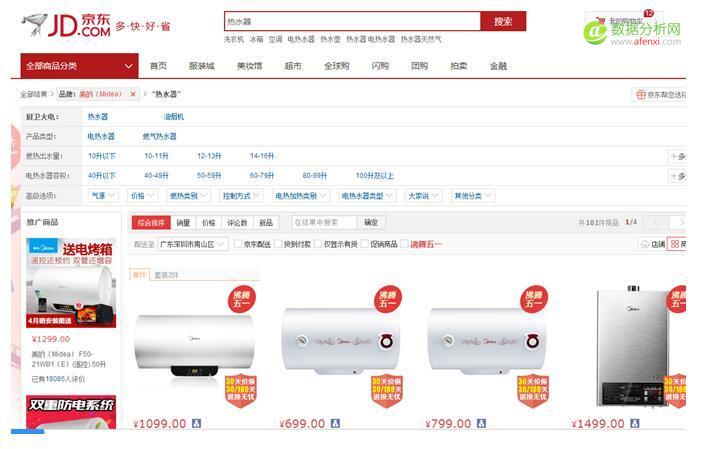
復制制頁面的地址到八爪魚中去如下圖: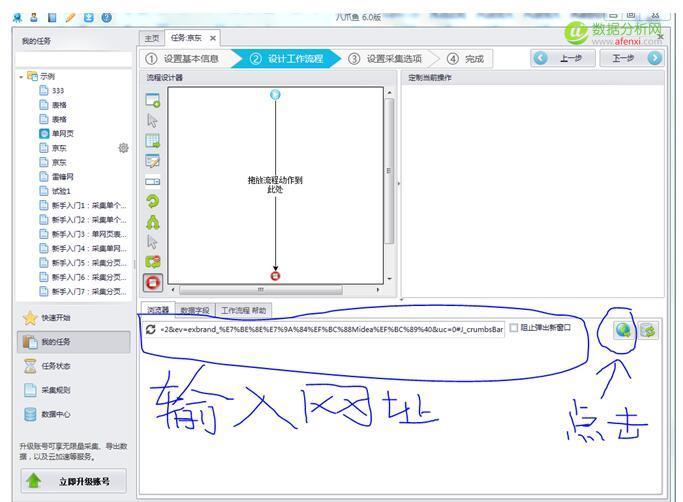
觀察網頁的類型,由于包含美的熱水器的頁面不止一頁,下面有翻頁按鈕,因此我們需要建立一個循環點擊下一頁, 然后在八爪魚中的京東頁面上點擊下一頁,在彈出的對話列表中點擊循環點擊下一頁,如圖: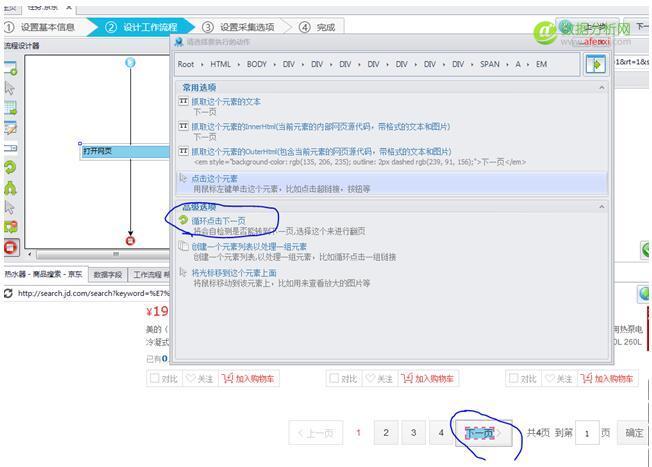
然后點擊一個商品,在彈出的頁面中點擊添加一個元素列表以處理一祖元素–再點擊添加到列表—繼續編輯列表,接下來我們點擊另一商品的名字,在彈出的頁面上點擊添加到列表,這樣軟件便自動識別了頁面中的其他商品,再點擊創建列表完成,再點擊循環,這樣就創建了一個循環抓取頁面中商品的列表,
然后軟件自動跳轉到第一個商品的具體頁面,我們點擊評論,在彈出頁面中點擊 點擊這個元素,看到評論也有很多頁,這時我們又需要創建一個循環列表,同上,點擊下一頁—循環點擊.然后點擊我們需要抓取的評論文本,在彈出頁面中點擊創建一個元素列表以處理一組元素—-點擊添加到列表—繼續編輯列表,然后點擊第2個評論在彈出頁面中點擊添加到列表—循環,再點擊評論的文本選擇抓取這個元素的文本.好了,此時軟件會循環抓取本頁面的文本,如圖:

都點擊完成成后,我們再看設計器發現有4個循環,第一個是翻頁,第二個是循環點擊每一個商品,第三個是評論頁翻頁,第4個是循環抓取評論文本,這樣我們需要把第4個循環內嵌在第3個循環里面去,然后再整體內嵌到第2個循環里面去,再整體內嵌到第1個循環里面去,這樣的意思就是,先點下一頁,再點商品,再點下一特,再抓取評論,這套動作循環.那么我們在設計器中只需拖動第4個循環到第3個循環再這樣拖動下去.即可: 拖動結果如下:,再點下一步—下一步–單擊采集就OK 了.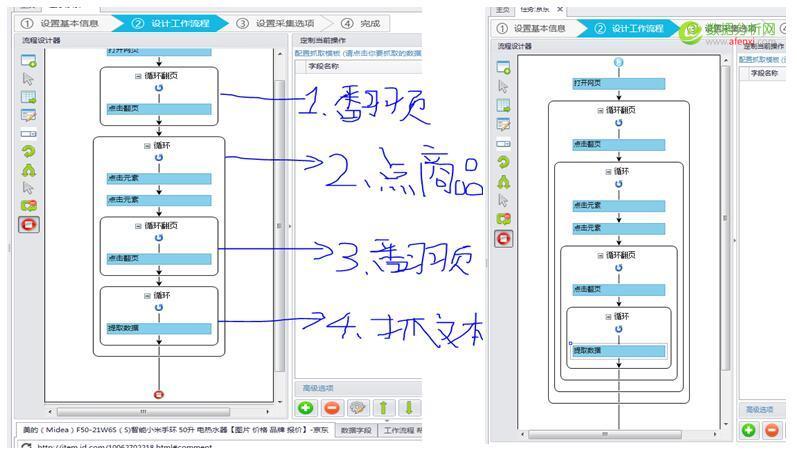 4.2文本去重
4.2文本去重
本例使用了京東平臺下對于美的熱水器的客戶評論作為分析對象,按照流程,首先我們使用八爪魚在京東網站上爬取了客戶對于美的熱水器的評論,部分數據如下!

進行簡單的觀察,我們可以發現評論的一些特點,
文本短,基本上大量的評論就是一句話.
情感傾向明顯:明顯的詞匯 如”好” “可以”
語言不規范:會出現一些網絡用詞,符號,數字等
重復性大:一句話出現詞語重復
數據量大.
故我們需要對這些數據進行數據預處理,先進行數據清洗,
編輯距離去重其實就是一種字符串之間相似度計算的方法�����。給定兩個字符串����,將字符串A轉化為字符串B所需要的刪除�����、插入����、替換等操作步驟的數量就叫做從A到B的編輯路徑����。而最短的編輯路徑就叫字符串A�、B的編輯距離���。比如����,“還沒正式使用�����,不知道怎樣�����,但安裝的材料費確實有點高���,380”與“還沒使用����,不知道質量如何�,但安裝的材料費確實貴�����,380”的編輯距離就是9.
首先,針對重復的評論我們要去重,即刪掉重復的評論.
另外一句話中出現的重復詞匯,這會影響一個評論中關鍵詞在整體中出現的頻率太高而影響分析結果.我們要將其壓縮.
還有一些無意義的評論,像是自動好評的,我們要識別并刪去.
4.3壓縮語句的規則:
1.若讀入與上列表相同,下為空,則放下
2.若讀入與上列表相同,下有,判斷重復, 清空下表
3.若讀入與上列表相同,下有,判斷不重,清空上下
4.若讀入與上列表不同,字符>=2,判斷重復,清空上下
5.若讀入與上列表不同,下為空,判斷不重,繼續放上
6.若讀入與上列表不同,下有,判斷不重,放下
7.讀完后,判斷上下,若重則壓縮.
4.4然后我們再進行中文的分詞,分詞的大致原理是:
中文分詞是指將一段漢字序列切分成獨立的詞����。分詞結果的準確性對文本挖掘效果至關重要��。目前分詞算法主要包括四種:字符串匹配算法�、基于理解的算法�、基于統計的方法和基于機器學習的算法�����。
1.字符串匹配算法是將待分的文本串和詞典中的詞進行精確匹配�,如果詞典中的字符串出現在當前的待分的文本中�����,說明匹配成功�����。常用的匹配算法主要有正向最大匹配����、逆向最大匹配�、雙向最大匹配和最小切分���。
2.基于理解的算法是通過模擬現實中人對某個句子的理解的效果進行分詞�。這種方法需要進行句法結構分析����,同時需要使用大量的語言知識和信息�,比較復雜���。
3.基于統計的方法是利用統計的思想進行分詞�。單詞由單字構成��,在文本中����,相鄰字共同出現的次數越多����,他們構成詞的概率就越大;因此可以利用字之間的共現概率來反映詞的幾率�����,統計相鄰字的共現次數�,計算它們的共現概率�。當共現概率高于設定的閾值時��,可以認為它們可能構成了詞
4.最后是基于機器學習的方法:利用機器學習進行模型構建�����。構建大量已分詞的文本作為訓練數據��,利用機器學習算法進行模型訓練�����,利用模型對未知文本進行分詞���。
4.5得到分詞結果后,
我們知道,在句子中經常會有一些”了””啊””但是”這些句子的語氣詞,關聯詞,介詞等等,這些詞語對于句子的特征沒有貢獻,我們可以將其去除,另外還有一些專有名詞,針對此次分析案例,評論中經常會出現”熱水器”,”中國”這是我們已知的,因為我們本來就是對于熱水器的評論進行分析,故這些屬于無用信息.我們也可以刪除.那么這里就要去除這些詞.一般是通過建立的自定義詞庫來刪除.
4.6 我們處理完分詞結果后,
便可以進行統計,畫出詞頻云圖,來大致的了解那些關鍵詞的情況,借此對于我們下一步的分析,提供思考的材料.操作如下:

4.7 有了分詞結果后,
我們便開始著手建模分析了,在模型的選擇面前,有很多方法,但總結下來就只有兩類,分別向量空間模型和概率模型,這里分別介紹一個代表模型
模型一: TF-IDF法:

方法A:將每個詞出現的頻率加權后,當做其所在維度的坐標,由此確定一特征的空間位置.
方法B:將出現的所有詞包含的屬性作為維度,再將詞與每個屬性的關系作為坐標,然后來定位一篇文檔在向量空間里的位置.
但是實際上��,如果一個詞條在一個類的文檔中頻繁出現�����,則說明該詞條能夠很好代表這個類的文本的特征���,這樣的詞條應該給它們賦予較高的權重���,并選來作為該類文本的特征詞以區別與其它類文檔�。這就是IDF的不足之處.
模型二:.LDA模型
傳統判斷兩個文檔相似性的方法是通過查看兩個文檔共同出現的單詞的多少��,如TF-IDF等�����,這種方法沒有考慮到文字背后的語義關聯���,可能在兩個文檔共同出現的單詞很少甚至沒有�����,但兩個文檔是相似的�����。
舉個例子����,有兩個句子分別如下:
“喬布斯離我們而去了�����?���!?/span>
“蘋果價格會不會降?”
可以看到上面這兩個句子沒有共同出現的單詞�����,但這兩個句子是相似的���,如果按傳統的方法判斷這兩個句子肯定不相似�����,所以在判斷文檔相關性的時候需要考慮到文檔的語義���,而語義挖掘的利器是主題模型����,LDA就是其中一種比較有效的模型��。
LDA模型是一個無監督的生成主題模型�,其假設:文檔集中的文檔是按照一定的概率共享隱含主題集合��,隱含主題集合則由相關詞構成���。這里一共有三個集合�,分別是文檔集����、主題集和詞集��。文檔集到主題集服從概率分布���,詞集到主題集也服從概率分布?,F在我們已知文檔集和詞集����,根據貝葉斯定理我們就有可能求出主題集���。具體的算法非常復雜,這里不做多的解釋,有興趣的同學可以參看如下資料
http://www.52analysis.com/shujuwajue/2609.html
http://blog.csdn.net/huagong_a … 37616
4.8 項目總結
1.數據的復雜性更高,文本挖掘面對的非結構性語言,且文本很復雜.
2.流程不同,文本挖掘更注重預處理階段
3.總的流程如下:

5.應用領域:
1.輿情分析
2.搜索引擎優化
3.其他各行各業的輔助應用
6.分析工具:
ROST CM 6是武漢大學沈陽教授研發編碼的國內目前唯一的以輔助人文社會科學研究的大型免費社會計算平臺��。該軟件可以實現微博分析���、聊天分析����、全網分析����、網站分析���、瀏覽分析��、分詞���、詞頻統計��、英文詞頻統計�、流量分析����、聚類分析等一系列文本分析,用戶量超過7000,遍布海內外100多所大學,包括劍橋大學��、日本北海道大學�、北京大學����、清華大學�����、香港城市大學����、澳門大學眾多高校���。下載地址: http://www.121down.com/soft/softview-38078.html
RStudio是一種R語言的集成開發環境(IDE)����,其亮點是出色的界面設計及編程輔助工具�。它可以在多種平臺上運行�,包括windows���,Mac�����,Ubuntu�����,以及網頁版����。另外這個軟件是免費和開源的���,可以在官方網頁:www.rstudio.org
上下載��。
7.1 Rostcm6實現:
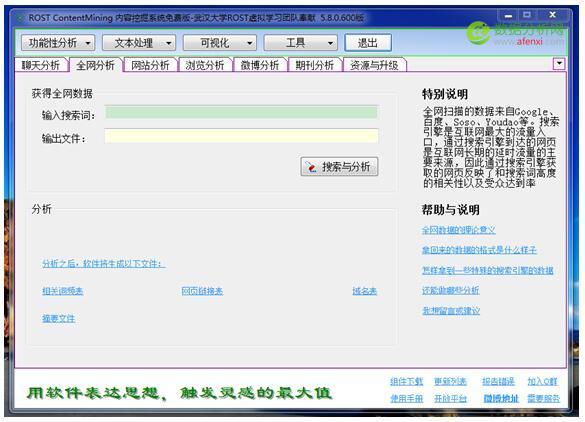
打開軟件ROSTCM6
這是處理前的文本內容,我們將爬取到的數據,只去除評論這一字段,然后保存為TXT格式,打開如下,按照流程我們先去除重復和字符,英文,數字等項.
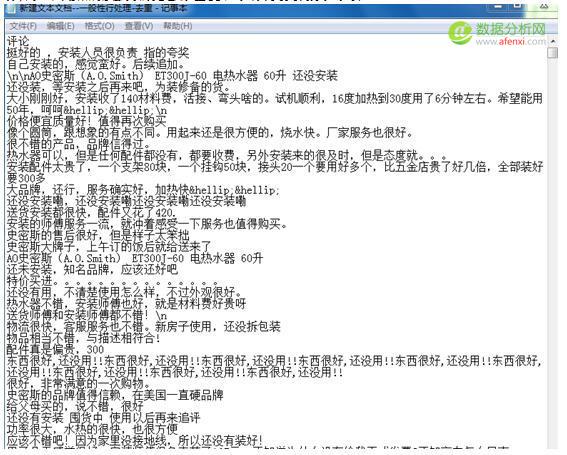
2.點 文本處理–一般性處理—處理條件選 “凡是重復的行只保留一行”與”把所有行中包含的英文字符全部刪掉” 用來去掉英文和數字等字符
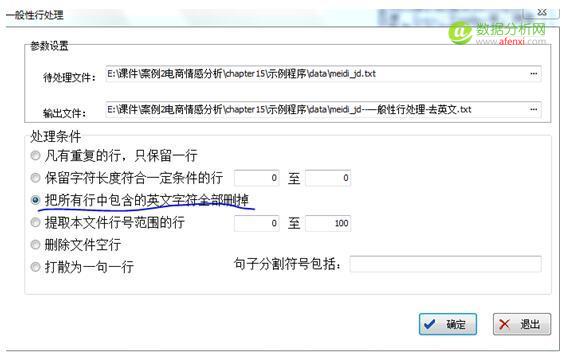
這是處理后的文檔內容,可以看到數字和英文都被刪除了. 3.接下來, 再進行分詞處理. 點 功能分析 —-分詞 (這里可以選擇自定義詞庫,比如搜狗詞庫,或者其他)
3.接下來, 再進行分詞處理. 點 功能分析 —-分詞 (這里可以選擇自定義詞庫,比如搜狗詞庫,或者其他)
得分詞處理后的結果.,簡單觀察一下,分詞后 ,有許多 “在”,”下”,”一”等等無意義的停用詞
4.接下來,我們進行專有名詞,停用詞過濾. 并統計詞頻.點 功能分析 —詞頻分析(中文)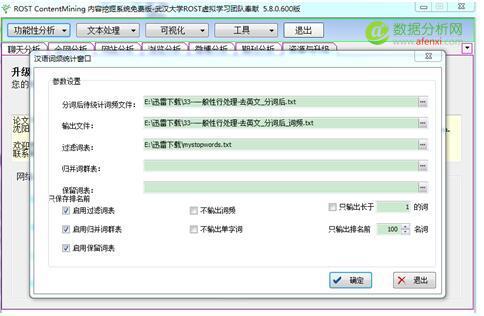
在功能性分析下點情感分析,可以進行情感分析,
并可以實現云圖的可視化.
7.2 R的實現
這里需要安裝幾個必須包,因為有幾個包安裝比較復雜,這里給了鏈接http://blog.csdn.net/cl1143015 … 82731
大家可以參看這個博客安裝包.安裝完成后就可以開始R文本挖掘了
加載工作空間
library(rJava)
library(tmcn)
library(Rwordseg)
library(tm)
setwd(“F:/數據及程序/chapter15/上機實驗”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8″)
head(data1)
data<-data1[1:100]
—————————————————————#Rwordseg分詞
data1_cut=segmentCN(data1,nosymbol=T,returnType=”tm”)
刪除\n,英文字母��,數字
data1_cut=gsub(“\n”,””,data1_cut)
data1_cut=gsub(“[a-z]*”,””,data1_cut)
data1_cut=gsub(“\d+”,””,data1_cut)
write.table(data1_cut,’data1_cut.txt’,row.names = FALSE)
Data1=readLines(‘data1_cut.txt’)
Data1=gsub(‘\”‘,”,data1_cut)
length(Data1)
head(Data1)
———————————————————————– #加載工作空間
library(NLP)
library(tm)
library(slam)
library(topicmodels)
R語言環境下的文本可視化及主題分析
setwd(“F:/數據及程序/chapter15/上機實驗”)
data1=readLines(“./data/meidi_jd_pos_cut.txt”,encoding = “UTF-8”)
head(data1)
stopwords<- unlist (readLines(“./data/stoplist.txt”,encoding = “UTF-8”))
stopwords = stopwords[611:length(stopwords)]
刪除空格���、字母
Data1=gsub(“\n”,””,Data1)
Data1=gsub(“[a~z]*”,””,Data1)
Data1=gsub(“\d+”,””,Data1)
構建語料庫
corpus1 = Corpus(VectorSource(Data1))
corpus1 = tm_map(corpus1,FUN=removeWords,stopwordsCN(stopwords))
建立文檔-詞條矩陣
sample.dtm1 <- DocumentTermMatrix(corpus1, control = list(wordLengths = c(2, Inf)))
colnames(as.matrix(sample.dtm1))
tm::findFreqTerms(sample.dtm1,2)
unlist(tm::findAssocs(sample.dtm1,’安裝’,0.2))
—————————————————————–
#主題模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = “Gibbs”,control = list(seed = 2015, burnin = 1000,thin = 100, iter = 1000))
最可能的主題文檔
Topic1 <- topics(Gibbs, 1)
table(Topic1)
每個Topic前10個Term
Terms1 <- terms(Gibbs, 10)
Terms1
——————————————————————- #用vec方法分詞
library(tmcn)
library(tm)
library(Rwordseg)
library(wordcloud)
setwd(“F:/數據及程序/chapter15/上機實驗”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8”)
d.vec1 <- segmentCN(data1,returnType = “vec”)
wc1=getWordFreq(unlist(d.vec1),onlyCN = TRUE)
wordcloud(wc1$Word,wc1$Freq,col=rainbow(length(wc1$Freq)),min.freq = 1000)
#
8.結果展示與說明
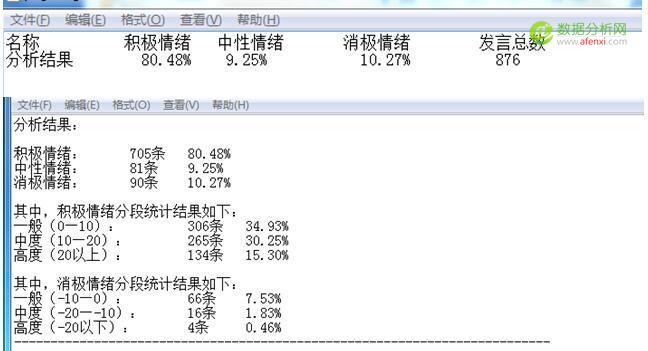
這是分析的部分結果.可以看到大部分客戶的評論包含積極情緒,說明了客戶對于美的熱水器認可度比較高滿意度也可以,當然,我們僅憑情感分析的結果是無法看出,客戶到底對于哪些方面滿意,哪些方面不滿意,我們有什么可以保持的地方,又有哪些需要改進的地方,這就需要我們的另一項結果展示.

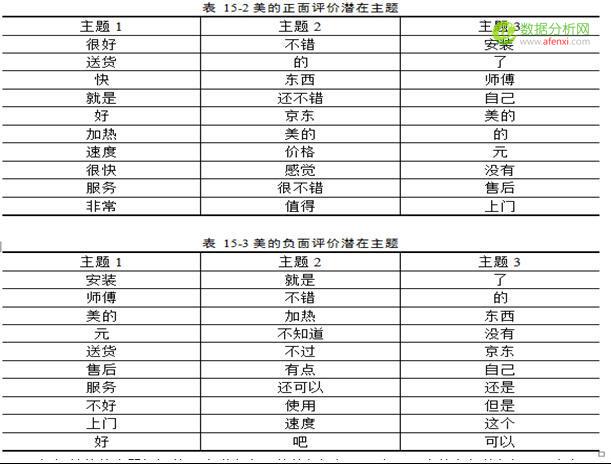
點可視化工具,便可得到詞頻云圖.根據云圖,我們可以看到客戶最最關心的幾個點,也就是評論中,說得比較多的幾個點,由圖我們可以看到”安裝”,”師傅””配件””加熱””快””便宜””速度””品牌””京東””送貨”“服務””價格””加熱”等等關鍵詞出現頻率較高,我們大致可以猜測的是26
安裝方面的問題
熱水器價格方面比較便宜
熱水器功能方面 加熱快,
京東的服務和送貨比較快.
另外值得我們注意的是,云圖里面,也有些”好”,”大”,”滿意”等等出現比較多的詞,我們尚且不知道這些詞背后的語義,這就需要我們去找到相應的評論,提取出這些詞相應的主題點.再加以優化分析的結果
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
