矩陣分解在推薦系統中的應用:NMF和經典SVD實戰
數據

關于NMF����,在隱語義模型和NMF(非負矩陣分解)已經有過介紹��。
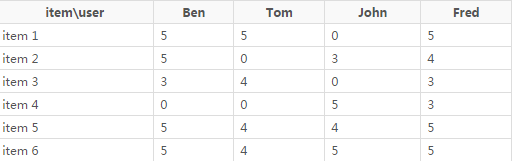
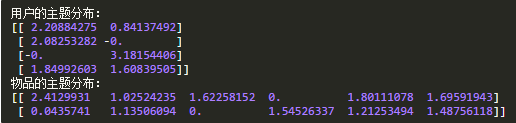
用戶和物品的主題分布

運行后輸出:
可視化物品的主題分布:
結果:
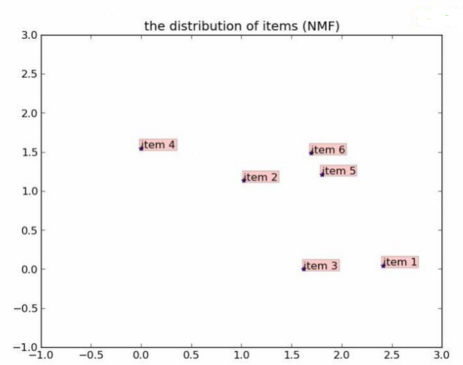
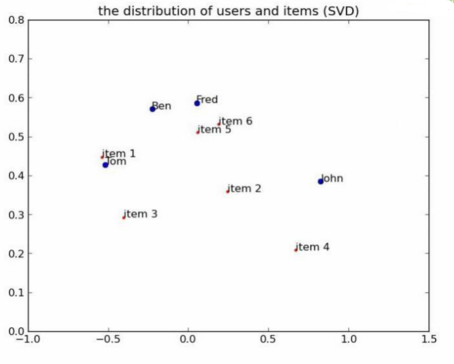
從距離的角度來看���,item 5和item 6比較類似�����;從余弦相似度角度看�,item 2���、5���、6 比較相似�����,item 1���、3比較相似��。
可視化用戶的主題分布:
結果:
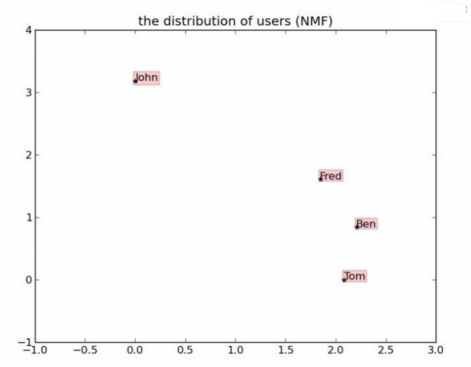
從距離的角度來看�,Fred���、Ben���、Tom的口味差不多�;從余弦相似度角度看�����,Fred�����、Ben���、Tom的口味還是差不多����。
如何推薦
現在對于用戶A����,如何向其推薦物品呢���?
方法1: 找出與用戶A最相似的用戶B���,將B評分過的����、評分較高����、A沒評分過的的若干物品推薦給A��。
方法2: 找出用戶A評分較高的若干物品�����,找出與這些物品相似的����、且A沒評分的若干物品推薦給A�。
方法3: 找出用戶A最感興趣的k個主題�,找出最符合這k個主題的����、且A沒評分的若干物品推薦給A����。
方法4: 由NMF得到的兩個矩陣���,重建評分矩陣�����。例如:
運行結果:
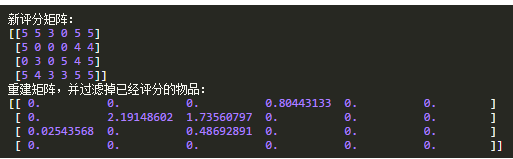
對于Tom(評分矩陣的第2行)��,其未評分過的物品是item 2����、item 3���、item 4�����。item 2的推薦值是2.19148602��,item 3的推薦值是1.73560797��,item 4的推薦值是0����,若要推薦一個物品��,推薦item 2����。
如何處理有評分記錄的新用戶
NMF是將非負矩陣V分解為兩個非負矩陣W和H:
V=W×H
在本文上面的實現中�,V對應評分矩陣����,W是用戶的主題分布���,H是物品的主題分布�。
對于有評分記錄的新用戶�,如何得到其主題分布����?
方法1: 有評分記錄的新用戶的評分數據放入評分矩陣中�����,使用NMF處理新的評分矩陣�����。
方法2: 物品的主題分布矩陣H保持不變�����,將V更換為新用戶的評分組成的行向量��,求W即可��。
下面嘗試一下方法2�����。
設新用戶Bob的評分記錄為:
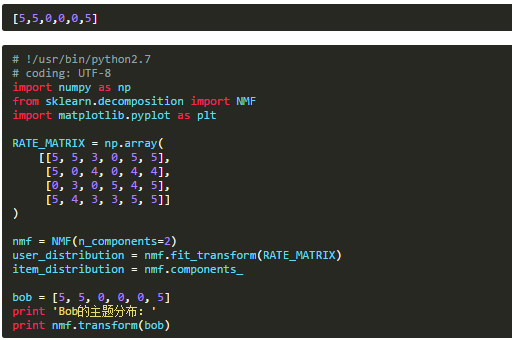
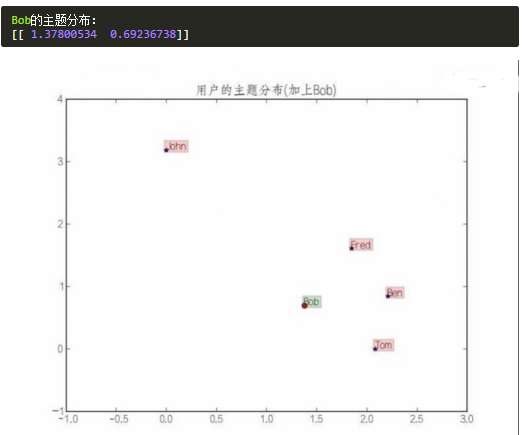
運行結果是:
關于SVD的一篇好文章:強大的矩陣奇異值分解(SVD)及其應用�����。
相關分析與上面類似����,這里就直接上代碼了���。
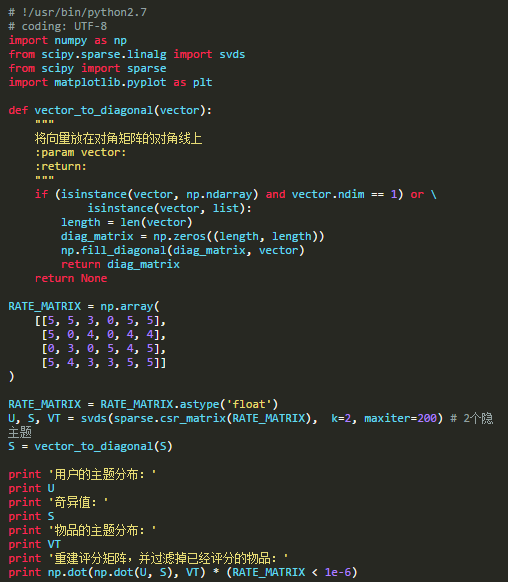
運行結果:

可視化一下:
0代表沒有評分�����,但是上面的方法(如何推薦這一節的方法4)又確實把0看作了評分����,所以最終得到的只是一個推薦值(而且總體都偏?��。?���,而無法當作預測的評分����。在How do I use the SVD in collaborative filtering?有這方面的討論�。
SVD的目標是將m*n大小的矩陣A分解為三個矩陣的乘積:
[latex]
A = U S V^{T}
[/latex]
U和V都是正交矩陣�,大小分別是m*m�����、n*n���。S是一個對角矩陣�,大小是m*n��,對角線存放著奇異值���,從左上到右下依次減小�,設奇異值的數量是r�。
取k�,k<<r��。
取得UU的前k列得到UkUk�,SS的前k個奇異值對應的方形矩陣得到SkSk�,VTVT的前k行得到VTkVkT��,于是有
[latex]
A_{k} = U_{k} S_{k} V^{T}_{k}
[/latex]
AkAk可以認為是AA的近似�。
下面的算法將協同過濾和SVD結合了起來����。
Item-based Filtering Enhanced by SVD
這個算法來自下面這篇論文:
Vozalis M G, Margaritis K G. Applying SVD on Generalized Item-based Filtering[J]. IJCSA, 2006, 3(3): 27-51.
1��、 設評分矩陣為R�,大小為m*n�,m個用戶����,n個物品��。R中元素rijrij代表著用戶uiui對物品ijij的評分�。
2�、 預處理R�,消除掉其中未評分數據(即值為0)的評分���。
計算R中每一行的平均值(平均值的計算中不包括值為0的評分)��,令Rfilled?in=RRfilled?in=R����,然后將Rfilled?inRfilled?in中的0設置為該行的平均值��。
計算R中每一列的平均值(平均值的計算中不包括值為0的評分)riri���,Rfilled?inRfilled?in中的所有元素減去對應的riri���,得到正規化的矩陣RnormRnorm�。(norm����,即normalized)�。
3��、 對RnormRnorm進行奇異值分解�,得到:
[latex]
R_{norm} = U S V^{T}
[/latex]
4����、 設正整數k�����,取得UU的前k列得到UkUk���,SS的前k個奇異值對應的方形矩陣得到SkSk�����,VTVT的前k行得到VTkVkT��,于是有
[latex]
R_{red} = U_{k} S_{k} V^{T}_{k}
[/latex]
red�����,即dimensionality reduction中的reduction�?��?梢哉J為k是指最重要的k個主題���。定義RredRred中元素rrijrrij用戶i對物品j在矩陣RredRred中的值�。
5�、 [latex] U_{k} S_{k}^{\frac{1}{2}}[/latex]���,是用戶相關的降維后的數據���,其中的每行代表著對應用戶在新特征空間下位置�。[latex] S_{k}^{\frac{1}{2}}V^{T}_{k}[/latex]�����,是物品相關的降維后的數據����,其中的每列代表著對應物品在新特征空間下的位置��。
S12k?VTkSk12?VkT中的元素mrijmrij代表物品j在新空間下維度i中的值����,也可以認為是物品j屬于主題i的程度�。(共有k個主題)��。
6�、 獲取物品之間相似度�����。
根據S12k?VTkSk12?VkT計算物品之間的相似度���,例如使用余弦相似度計算物品j和f的相似度: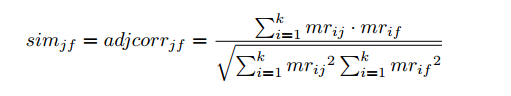
相似度計算出來后就可以得到每個物品最相似的若干物品了��。
7�����、 使用下面的公式預測用戶a對物品j的評分:
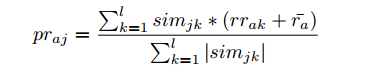
這個公式里有些變量的使用和上面的沖突了(例如k)���。
ll是指取物品j最相似的ll個物品�����。
mrijmrij代表物品j在新空間下維度i中的值�,也可以認為是物品j屬于主題i的程度����。
simjksimjk是物品j和物品k的相似度����。
RredRred中元素rrakrrak是用戶a對物品k在矩陣RredRred中對應的評分�。raˉraˉ是指用戶a在評分矩陣RR中評分的平均值(平均值的計算中不包括值為0的評分)���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
