數據分析的影響因素之分析算法
整個數據分析的流程就是基于基礎數據�����,通過不同的算法或數學模型來實現業務價值的過程��。當我們擁有了數據基礎后����,下一步要做的就是選擇合適的算法來挖掘隱藏在數據中的信息價值����。
在以往企業的數據分析中�����,數據分析人員更多會從歷史數據與當期數據的對比��,當期數據多種緯度的現狀呈現角度入手��,其呈現價值主要在于對于企業運營的情況進行呈現�,由于企業各個部門中有大量的信息需要同步給其他部門�����,而這些內容如果光靠語言描述或者會議紀要的方式傳遞的話��,無論是承載的信息量還是傳遞效率還是記錄過程中的信息流失都是無法承受的�。
所以從很久以前開始�,數字化管理就已經成為企業的關鍵管理模塊了�����。正如質量管理專家戴明說的那句名言:In God We Trust, All Others Bring Data.(除了上帝我無條件相信以外�����,所有其他的都給我把數據拿出來)����。
在以往�����,這個“所有其他的”的范圍倒是還比較小���,因為數據分析人員只要把上述內容做好����,把當期的情況全面呈現出來���,再跟以往作下對比就行了��,如果說做的比較好的�����,則會把趨勢分析也加入進來�����,基于以往的數據��,基于趨勢分析算法來評估未來該數據指標的變動趨勢和波動范圍�。
可是在今天�,這些內容已經遠遠不能滿足企業的胃口了�����,導致這一切發生的根本原因就在于上一篇文章我所說的����,技術和管理能力的提升所導致的數據指標的極大豐富����,這一因素致使以往管理者想都不敢想的數學算法�,數學模型的應用成為可能�����。
從數學角度來看數據分析的話�,其“了解過去”�����,用數字的方式來呈現企業內部方方面面的運營情況僅僅只是其功能的很小的一部分��,甚至可以說這部分內容都不能算在數學領域內����,因為其根本就沒有涉及到任何的算法或模型的應用��。而真正應用數學知識來實現的數據分析則更多會關注在預測未來上�。
何為未來的預測����,在前邊我所提到的趨勢分析就是其中一種���,即運用統計學算法來計算未來數據的波動情況���,而這個內容的應用在以往之所以能夠實現的原因就在于其對于數據指標的需求較為簡單�,因為只要數據庫中能夠有單一指標的歷史數據積累�����,即便數據的記錄有所缺失都能夠應用該算法�����。
但是再往上��,在應用統計學中的更高階的算法工具時���,如聚類分析����,回歸分析時���,我們對于數據指標的需求就大大提升了��。就像“啤酒尿布”理論中使用的RFM模型就需要最近一次消費(Recency)����、消費頻率(Frequency)���、消費金額(Monetary)和商品類型等四類指標信息�。而一旦提升到關聯分析這個層級�,我們所需要就已經不是有限的指標了���,而是已經把指標的豐富度作為了模型品質的考核因素之一了����,也就是說模型中的指標越豐富�����,那么這個模型就越可能發揮其作用��,至于完全獨立的創建數學模型的話�����,我們則不僅需要數據指標了����,其他諸如文本信息的結構化都成為了模型構成的核心要素了��。
所以說在以往�����,如果想要達成上述工具或模型的應用��,我們的數據庫需要多么強大�,不過在今天���,這一切終于得到了系統層面上的解決方案�,在大數據技術的應用下��,讓我們來看看何為真正的數據分析吧�����。
目前針對業務需求�����,我們最為常用的統計學分析方法主要有兩類�����,即聚類分析跟回歸分析����。以下讓我們分別以案例的方式來介紹這兩部分內容���。
聚類分析(客戶分類/熱門問題聚焦)
聚類分析�,專業定義請各位自行查找百度百科����,在這里我用大白話來說����,其實聚類分析顧名思義就是“物以類聚”的分析方法�,它的目標就是把類似的對象放到一個類型中去���。
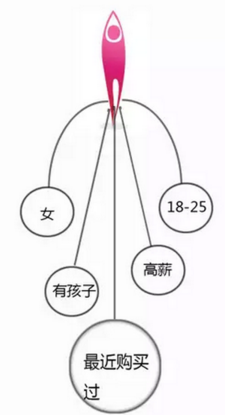
聚類分析這個分析工具在企業的運營過程中能夠起到非常巨大的效果�����,最典型的應用場景就是客戶分類或者說市場細分層面上���,在以往我們都是通過客戶的消費能力來界定客戶類型的��,即“高端客戶”等���,而且這個消費能力的邊界也是企業自己腦補的�,100元以下一類��?1000元以下一類�?10000元以下一類�����?都是企業管理人員自己看著定的��,當然并不是說這種拍腦袋的方法有什么錯誤����,實際上資深企業管理人員的經驗往往是最好的分析工具�。但是這個工具無法推廣����,如果換個新人來�,出錯誤的概率就會大大提升�����,而且另一方面�����,僅僅只是消費能力是不是就能夠界定出所謂的“高端客戶”�����,這本身也存在一定的不合理性����。今天比較先進的企業會采取將交互活躍度��,購買頻次等信息共同加入的方法來全面衡量所謂的“高端客戶”���,但這是否足夠全面�����,其實大家心里都明白��。但如果再增加內容���,一方面數據來源困難�,一方面傳統的人工界定的方法難以顧得過來這么多的信息����,而此時就需要大數據系統和統計學軟件了���。在今天的數據庫中���,我們所記錄的內容已經遠遠不是當年的客戶簡單的行為信息了�,包括地理信息(如住址�����,氣候����,環境)���,人口信息(年齡�、性別�����、職業��、收入����、教育�����、家庭類型�、家庭人口)�,心理信息(風格個性���、愛好���、態度特點���、渠道偏好)�,交互信息(購買產品類型�����、交互頻次�、購買頻次�、售后頻次���、售后內容�、產品評價)等等��。通過SPSS或者SAS統計軟件�,我們能夠將這些內容通通放入程序中進行綜合分析�����,在這些各類型的信息綜合之下����,我們將能夠在一個更為完整的客戶畫像之下對客戶進行分類����,進而對企業戰略側重提供關鍵信息����。
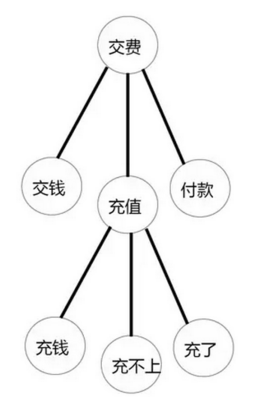
在文本分析中�,聚類分析也起到了不可忽視的作用����,譬如熱門問題聚焦��。以往企業可以收集到很多客戶反饋的評論�,這些客戶聲音對企業的價值很大����,可是龐大的信息量���、非結構化的文本��,使得對文本價值的挖掘造成了很大困擾�����。為了使文本信息量縮小并且可分析����,首先我們可以去掉一些水詞(如:的���、呀等副詞)����;然后將一些相似的詞或近義詞進行聚類(如:交費���、充錢�、充不上錢�����、交錢等即可聚類為交費)���,這樣我們會聚類出很多關鍵詞��;然后�����,我們對這些關鍵詞進行聚類�����,即可得到熱門話題(如:交費出問題)��。由于漢語的博大精神���,現在文本分析的道路還存在一些障礙��,不過不久的將來�����,文本分析應該會帶給企業更多的顯性價值�����。
回歸分析(疾病分析/《紙牌屋》)
回歸分析的具體定義在這里也不詳講����,從作用上來講�����,這種分析方法最重要的目的就在于找到各種因素之間的具體關系����。這個分析工具能夠在大量的毫無關聯的因素之間��,基于一個目標因素進行分析�����,來看其他所有的因素與這個目標因素之間究竟有著怎么樣的關系���,在這個領域中��,屬醫學分析相關應用最為成熟�,舉例來講����,醫生希望能夠通過一系列檢查來判斷病人是否有得心臟病���,那就需要判斷心臟病可能會跟哪些其他癥狀有相關性�����,這就需要對以往得過心臟病的病人與沒得過心臟病的正常人進行綜合比對���,將各個指標�����,諸如心率�,膽固醇等指標進行匯總���,以對象是否有心臟病作為目標因素來分析����,通過SVM等回歸算法來判斷���,患有心臟病的對象與沒有心臟病的對象之間有差異的因素都有哪些��,這些因素將會成為我們對患者檢查的關鍵因素�����。
而在商業領域中���,netflix的《紙牌屋》就是另一個典型的例子了�,我們可以看到��,以往客戶觀看的電視劇類型�,演員陣容�,主題類型����,包括地點���,結局等�,通過以客戶是否觀看作為判斷因素����,將上述因素與這個目標進行回歸分析��,我們就能看到影響客戶觀看的關鍵因素都可能是哪些�,他們本身又應該是什么��,這樣就能進一步判斷不同類型的客戶�,以及這類客戶的需求會有哪些���,應該給他們推什么產品���,或者設計什么產品等��,這同樣能夠為企業戰略提供重要支撐���。
上述案例是眾多的數學方法應用于數據分析的典型場景����,但并不是全部場景���,實際上這個領域可以擴展的內容太多����,幾乎無法窮舉���,而伴隨著今天底層數據的越發成熟���,我們能夠使用的數據分析方法也就越來越豐富����,能夠給企業帶來價值的緯度也就越來越多��,可以說在今天這樣的技術支撐下�,我們才真正敢說數據分析迎來了正式的春天�����,而要真正進入這一數據時代���,除了前邊所說的數據和算法支撐���,這些都屬于業務層面��,我們最后需要的就是事務層面的需求�����,這也就是我在下次文章中希望能夠介紹的�����,在組織結構上的數據分析變革����。
其實算法層面并不像其他層面有那么多的問題��,其實它就是一個客觀的工具�,我們更多需要的是在業務層面�,即數據指標層面�,和事務層面��,即組織結構層面上的支撐��,只有這些支撐真正到位���,我們才能應用這些數學工具�����,真正發揮數據分析的價值��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
