決策樹算法真的越復雜越好嗎����?
凡是在統計分析或機器學習領域從業的朋友們�����,對決策樹這個名詞肯定都不陌生吧�。
決策樹是一種解決分類問題的絕好方法����,顧名思義��,它正像一棵大樹一樣���,由根部不斷生長出很多枝葉�����;它的優點實在太多�����,比如可以避免缺失值的影響�����、可以處理混合預測��、模型容易展示等��。然而��,決策樹的實際應用也絕不簡單����,如果樹根稍有不穩�、或者枝干略有差池��,樹就可能會徹底長偏啦��,我們總是需要仔細挑選單棵決策樹�����、或適當的組合��。
單棵決策樹
這是統計分析領域比較常用�����、機器學習領域也用得爛熟的分類算法:一棵大樹上每支葉子自成一類�����。在實際業務中�,大家最關心的問題包括:在每一個節點該選擇哪個屬性進行分割��?該怎樣分割才能效果最好�?這些問題通常都可以通過SAS Enterprise Miner中強大的交互決策樹功能解決�����,選擇最大的logworth值來選擇拆分變量�、創建拆分規則����。
不過��,這樣的分類過程到底應該在什么時候結束呢����?最直觀的方式當然是在每個子節點只有一種類型的記錄時停止分類����,但是這樣可能會使得樹的節點過多����,導致過擬合問題(overfitting)�����,即該決策樹對訓練數據可以得到很低的錯誤率���,但是運用到驗證數據上時卻錯誤率極高�。所以����,剪枝是優化和解決這類問題的必要做法�,我們之前介紹過的K折交叉驗證(點擊閱讀)也可用來對原始決策樹進行驗證和裁減��,從而得到最優決策樹�。單棵決策樹的實現在SAS Enterprise Miner中有現成的節點可直接使用��。
除了剪枝�����、交叉驗證等手段外���,為了有效減少單決策樹帶來的問題����,與決策樹相關的組合分類(比如Bagging, Boosting等算法)也逐漸被引入進來��,這些算法的精髓都是通過生成N棵樹(N可能高達幾百)��、最終形成一棵最適合的結果分類樹����。有人戲稱這是三個臭皮匠頂一個諸葛亮的算法:雖然這幾百棵決策樹中的每一棵相對于C4.5算法來說可能都很簡單���,但是他們組合起來卻真的很強大����。下面我們就來簡單介紹幾種常見的組合算法:
Bagging組合算法
Bagging組合算法是bootstrap aggregating的縮寫���。我們可以讓上述決策樹學習算法訓練多輪��,每輪的訓練集由從初始的訓練集中有放回地隨機抽取n個訓練樣本組成�,某個初始訓練樣本在某輪訓練集中可以出現多次或根本不出現���,訓練之后就可以得到一個決策樹群h_1,……h_n �����,也類似于一個森林�����。最終的決策樹H對分類問題采用投票方式���,對回歸問題采用簡單平均方法對新示例進行判別���。
Boosting組合算法
此類算法中其中應用最廣的是AdaBoost(Adaptive Boosting)�����。在此算法中�����,初始化時以等權重有放回抽樣方式進行訓練�,接下來每次訓練后要特別關注前一次訓練失敗的訓練樣本�,并賦以較大的權重進行抽樣�����,從而得到一個預測函數序列h_1,?, h_m , 其中h_i也有一定的權重��,預測效果好的預測函數權重較大��,反之較小��。最終的預測函數H對分類問題采用有權重的投票方式����,所以Boosting更像是一個人學習的過程�����,剛開始學習時會做一些習題�,常常連一些簡單的題目都會弄錯��,但經過對這些題目的針對性練習之后����,解題能力自然會有所上升�����,就會去做更復雜的題目�;等到他完成足夠多題目后����,不管是難題還是簡單題都可以解決掉了��。
隨機森林(Random forest)
隨機森林����,顧名思義��,是用隨機的方式建立一個森林�,所以它對輸入數據集要進行行��、列的隨機采樣��。行采樣采用有放回的隨機抽樣方式�,即采樣樣本中可能有重復的記錄���;列采樣就是隨機抽取部分分類特征�����,然后使用完全分裂的方式不斷循環建立決策樹群�。當有新的輸入樣本進入的時候����,也要通過投票方式決定最終的分類器��。
一般的單棵決策樹都需要進行剪枝操作���,但隨機森林在經過兩個隨機采樣后���,就算不剪枝也不會出現overfitting��。我們可以這樣比喻隨機森林算法:從M個feature中選擇m個讓每一棵決策樹進行學習時�,就像是把它們分別培養成了精通于某一個窄領域的專家���,因此在隨機森林中有很多個不同領域的專家����,對一個新的問題(新的輸入數據)可以從不同的角度去看待����,最終由各位專家投票得到結果���。
至此���,我們已經簡單介紹了各類算法的原理����,這些組合算法們看起來都很酷炫���?��?墒撬鼈冎g究竟有哪些差異呢���?
隨機森林與Bagging算法的區別主要有兩點:
-
隨機森林算法會以輸入樣本數目作為選取次數��,一個樣本可能會被選取多次�����,一些樣本也可能不會被選取到�����;而Bagging一般選取比輸入樣本的數目少的樣本�;
-
Bagging算法中使用全部特征來得到分類器�,而隨機森林算法需要從全部特征中選取其中的一部分來訓練得到分類器��。從我們的實際經驗來看�����,隨機森林算法常常優于Bagging算法���。
Boosting和Bagging算法之間的主要區別是取樣方式的不同���。Bagging采用均勻取樣�����,而Boosting根據錯誤率來取樣���,因此Boosting的分類精度要優于Bagging���。Bagging和Boosting都可以有效地提高分類的準確性��。在多數數據集中���,Boosting的準確性比Bagging高一些����,不過Boosting在某些數據集中會引起退化——過擬合��。
俗話說三個臭皮匠賽過諸葛亮��,各類組合算法的確有其優越之處�����;我們也認為����,模型效果從好到差的排序通常依次為:隨機森林>Boosting > Bagging > 單棵決策樹����。但歸根結底����,這只是一種一般性的經驗����、而非定論�����,應根據實際數據情況具體分析��。就單棵決策樹和組合算法相比較而言���,決策樹相關的組合算法在提高模型區分能力和預測精度方面比較有效�����,對于像決策樹����、神經網絡這樣的“不穩定”算法有明顯的提升效果��,所以有時會表現出優于單棵決策樹的效果�。但復雜的模型未必一定是最好的��,我們要在具體的分析案例中����,根據業務需求和數據情況在算法復雜性和模型效果之間找到平衡點�����。
下面就通過一個實際案例來說明我們的觀點吧���。在筆者多年的數據分析工作中�,無論哪種分析都難以離開鐘愛的SAS Enterprise Miner軟件�,這里我們也以SAS EM來實現各分類算法在實際案例中的具體應用和分類效果����。
本文使用的樣例數據是一組2015年第三季度的房屋貸款數據�����,大約共5960條數據���,其中貸款逾期的客戶數占比為19.95%, 分析變量包含所需的貸款金額����、貸款客戶的職業類別�����、當前工作年限�����、押品的到期價值等13個屬性特征����。我們的目標是要通過上述數據來擬合貸款客戶是否會出現逾期行為的分類模型�,進而判斷和預測2015年第四季度的房貸客戶是否會出現逾期情況��。
在建立各類模型前��,筆者同樣利用數據分區節點將全量的建模樣本一分為二�����,其中70%作為訓練樣本���、30%作為驗證樣本�,然后再來逐個建立�����、驗證決策樹的單棵樹模型和組合分類模型����,并進行模型之間的比較分析和評估����。
模型建設和分析的整個流程圖邏輯如下:
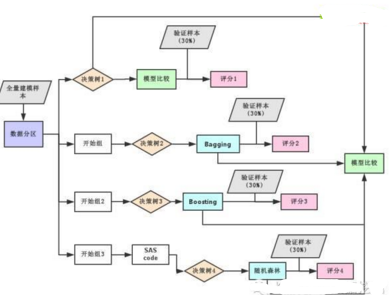
熟悉SAS EM的小伙伴會發現��,三種組合算法都使用了開始組這樣的節點�,目的有三:
傳統的Bagging和Boosting算法在操作中都需要在開始組節點中設置屬性����;
對于隨機森林的實現�,可添加SAS code節點通過手工coding方式實現隨機森林��;
對不同算法設置盡可能相同的模型屬性���,方便比較模型預測效果��,比如組合算法中循環次數都選擇為10次��。
說到這里����,大家大概迫不及待要看看四類模型對新樣本的預測準確性了吧�,下圖就是利用上述四種分類模型對2015年第四季度房貸新樣本客戶的貸款逾期情況的預測概率分布結果:
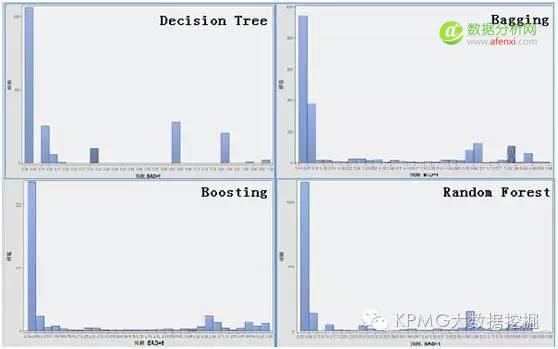
四張圖中分別是單棵決策樹�����、Bagging算法���、Boosting算法和隨機森林算法的結果�。圖中的橫軸代表逾期概率����,縱軸代表客戶數量�,顯然���,高柱狀分布越是靠向右邊�����,說明預測得到逾期客戶越多����;高柱狀分布越是靠向左邊�����,說明貸款客戶信用較好����。整體來看����,新樣本中預期逾期客戶較少���,但也有一部分客戶比較集中地分布在逾期概率為0.7和0.85附近�,這些客戶需要特別關注���。
對于這樣的分類結果�,又如何來判斷它的預測準確性是好是差呢���?這時就要推出誤分類率和和均方誤差這兩個統計量了�。從下面的結果可以看出���,四類模型的誤分類率都很小���,相比較而言����,單棵決策樹最終勝出����。
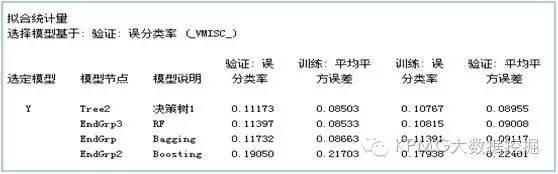
是不是完全沒想到�?上文看起來不太高大上的單棵決策樹�����,在這個案例中倒是效果格外好�。再來看看其他統計量的比較吧:


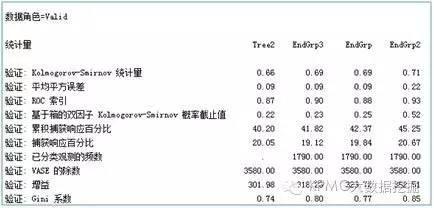
從上面的結果看���,四類模型中ROC統計量的值都在0.8以上���,KS值也都在0.6以上����,說明它們的效果都比較好�����。我們使用的樣本數據分布本身較為理想�,單決策樹模型的效果已經就相當理想���,即使使用其他組合算法進行優化��,模型效果的差異不會太明顯���,而三類組合算法之間的差異也不太突出����。
我們同時發現�,組合算法在提升度上確實比單個決策樹效果要好�,尤其Boosting算法表現更為明顯���。但是SAS EM的模型比較節點還是認為單決策樹模型是最優模型����,其驗證集誤判率最小�����。
就這一案例而言��,盡管單決策樹模型的區分能力和提升度都沒有Boosting算法和隨機森林算法效果好���,但其本身的效果已經在合理且效果較好的范圍之內了�,而且模型本身運行效率較高����、可解釋性也很高�����。組合算法雖然看起來更厲害����,但在應用實際業務場景和實際數據分布時���,找到模型復雜度和模型效果之間的平衡取舍也是需要慎重考慮的�。
我一向認為��,一名數據分析工作者的重要素質不但在于深入掌握多種方法�����,更在于做出合適的選擇��,為不同的業務情境選擇最恰當的方法���。畢竟����,沒有哪種算法是解決所有問題的萬靈藥���,而模型的運行效率���、甚至可解釋性等評判指標���,在實際工作中可能與模型效果同等重要��。復雜未必一定優于簡單��,而真正考驗功力的�,永遠是化繁為簡�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
