本文描述了一個基于 Spark 構建的認知系統:文本情感分析系統���,分析和理解社交論壇的非結構化文本數據�。
基于 Spark 的文本情感分析
文本情感分析是指對具有人為主觀情感色彩文本材料進行處理�����、分析和推理的過程����。文本情感分析主要的應用場景是對用戶關于某個主題的評論文本進行處理和分析��。比如�����,人們在打算去看一部電影之前�,通常會去看豆瓣電影板塊上的用戶評論�,再決定是否去看這部電影��。另外一方面���,電影制片人會通過對專業論壇上的用戶評論進行分析����,了解市場對于電影的總體反饋��。本文中文本分析的對象為網絡短評�,為非正式場合的短文本語料���,在只考慮正面傾向和負面傾向的情況下���,實現文本傾向性的分類��。
文本情感分析主要涉及如下四個技術環節:
收集數據集:本文中�����,以分析電影《瘋狂動物城》的用戶評論為例子����,采集豆瓣上《瘋狂動物城》的用戶短評和短評評分作為樣本數據��,通過樣本數據訓練分類模型來判斷微博上的一段話對該電影的情感傾向�。
設計文本的表示模型:讓機器“讀懂”文字�����,是文本情感分析的基礎����,而這首先要解決的問題是文本的表示模型���。通常�,文本的表示采用向量空間模型����,也就是說采用向量表示文本����。向量的特征項是模型中最小的單元���,可以是一個文檔中的字��、詞或短語���,一個文檔的內容可以看成是它的特征項組成的集合�,而每一個特征項依據一定的原則都被賦予上權重���。
選擇文本的特征:當可以把一個文檔映射成向量后����,那如何選擇特征項和特征值呢����?通常的做法是先進行中文分詞(----本文使用 jieba 分詞工具)���,把用戶評論轉化成詞語后�,可以使用 TF-IDF(Term Frequency–Inverse Document Frequency�,詞頻-逆文檔頻率)算法來抽取特征�����,并計算出特征值�。
選擇分類模型:常用的分類算法有很多����,如:決策樹��、貝葉斯����、人工神經網絡�����、K-近鄰�、支持向量機等等�。在文本分類上使用較多的是貝葉斯和支持向量機��。本文中�����,也以這兩種方法來進行模型訓練����。
為什么采用 Spark
傳統的單節點計算已經難以滿足用戶生成的海量數據的處理和分析的要求�����。比如�����,豆瓣網站上《瘋狂動物城》電影短評就有 111421 條�����,如果需要同時處理來自多個大型專業網站上所有電影的影評��,單臺服務器的計算能力和存儲能力都很難滿足需求�。這個時候需要考慮引入分布式計算的技術��,使得計算能力和存儲能力能夠線性擴展��。
Spark 是一個快速的��、通用的集群計算平臺�,也是業內非常流行的開源分布式技術����。Spark 圍繞著 RDD(Resilient Distributed Dataset)彈性分布式數據集��,擴展了廣泛使用的 MapReduce[5]計算模型�,相比起 Hadoop[6]的 MapReduce 計算框架�����,Spark 更為高效和靈活��。Spark 主要的特點如下:
內存計算:能夠在內存中進行計算��,它會優先考慮使用各計算節點的內存作為存儲�����,當內存不足時才會考慮使用磁盤�,這樣極大的減少了磁盤 I/O�����,提高了效率�。
惰性求值:RDD 豐富的計算操作可以分為兩類��,轉化操作和行動操作�����。而當程序調用 RDD 的轉化操作(如數據的讀取�、Map�����、Filter)的時候���,Spark 并不會立刻開始計算����,而是記下所需要執行的操作����,盡可能的將一些轉化操作合并�,來減少計算數據的步驟�����,只有在調用行動操作(如獲取數據的行數 Count)的時候才會開始讀入數據����,進行轉化操作���、行動操作���,得到結果�。
接口豐富:Spark 提供 Scala��,Java�����,Python��,R 四種編程語言接口�����,可以滿足不同技術背景的工程人員的需求��。并且還能和其他大數據工具密切配合�。例如 Spark 可以運行在 Hadoop 之上�����,能夠訪問所有支持 Hadoop 的數據源(如 HDFS���、Cassandra��、Hbase)����。
本文以 Spark 的 Python 接口為例���,介紹如何構建一個文本情感分析系統�����。作者采用 Python 3.5.0��,Spark1.6.1 作為開發環境���,使用 Jupyter Notebook[7]編寫代碼�����。Jupyter Notebook 是由 IPython Notebook 演化而來�����,是一套基于 Web 的交互環境��,允許大家將代碼����、代碼執行���、數學函數����、富文檔����、繪圖以及其它元素整合為單一文件���。在運行 pyspark 的之前�����,需要指定一下 pyspark 的運行環境����,如下所示:
清單 1. 指定 pyspark 的 ipython notebook 運行環境

接下里就可以在 Jupyter Notebook 里編寫代碼了�����。
基于 Spark 如何構建文本情感分析系統
在本文第 1 章��,介紹了文本情感分析主要涉及的四個技術環節���?���;?Spark 構建的文本分類系統的技術流程也是這樣的�����。在大規模的文本數據的情況下�����,有所不同的是文本的特征維度一般都是非常巨大的��。試想一下所有的中文字���、詞有多少���,再算上其他的語言和所有能在互聯網上找到的文本�,那么文本數據按照詞的維度就能輕松的超過數十萬�、數百萬維�,所以需要尋找一種可以處理極大維度文本數據的方法�����。
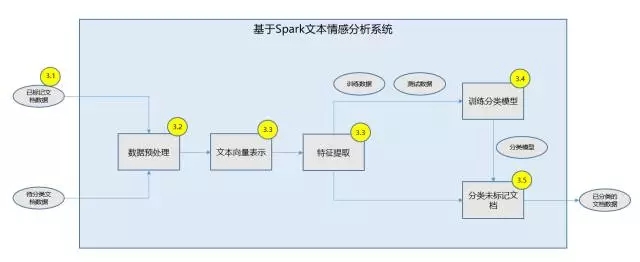
在本文后續章節中����,將依次按照基于 Spark 做數據預處理�����、文本建模����、特征提取���、訓練分類模型�、實現待輸入文本分類展開討論����。系統的上下文關系圖如圖 1 所示���,系統的功能架構圖如圖 2 所示���。
圖 1. 基于 Spark 文本情感分析系統上下文

圖 2. 基于 Spark 文本情感分析系統功能架構圖
爬取的數據說明
為了說明文本分類系統的構建過程�,作者爬取了豆瓣網絡上《瘋狂動物城》的短評和評分(https://movie.douban.com/subject/25662329/comments)��。示例數據如下所示:
表 1. 示例數據

表格中每一行為一條評論數據����,按照“評分���,評論文本”排放�,中間以制表符切分�����,評分范圍從 1 分到 5 分��,這樣的數據共采集了 116567 條��。
數據預處理
這一節本文是要說明用 Spark 是如何做數據清洗和抽取的��。在該子系統中輸入為爬蟲的數據���,輸出為包含相同數量好評和壞評的 Saprk 彈性分布式數據集�。
Spark 數據處理主要是圍繞 RDD(Resilient Distributed Datasets) 彈性分布式數據集對象展開��,本文首先將爬蟲數據載入到 Spark 系統��,抽象成為一個 RDD�?����?梢杂?distinct 方法對數據去重�。數據轉換主要是用了 map 方法�,它接受傳入的一個數據轉換的方法來按行執行方法��,從而達到轉換的操作它只需要用一個函數將輸入和輸出映射好����,那么就能完成轉換����。數據過濾使用 filter 方法��,它能夠保留判斷條件為真的數據����?�?梢杂孟旅孢@個語句�,將每一行文本變成一個 list���,并且只保留長度為 2 的數據�。
清單 2. Spark 做數據預處理

清單 3. 統計數據基本信息
 本文得到�����,五分的數據有 30447 條���,4 分����、3 分�、2 分����、1 分的數據分別有 11711 條����,123 條����,70 條�。打五分的毫無疑問是好評�;考慮到不同人對于評分的不同偏好��,對于打四分的數據���,本文無法得知它是好評還是壞評�����;對于打三分及三分以下的是壞評����。
下面就可以將帶有評分數據轉化成為好評數據和壞評數據�����,為了提高計算效率��,本文將其重新分區���。
清單 4. 合并負樣本數據
本文得到�����,五分的數據有 30447 條���,4 分����、3 分�、2 分����、1 分的數據分別有 11711 條����,123 條����,70 條�。打五分的毫無疑問是好評�;考慮到不同人對于評分的不同偏好��,對于打四分的數據���,本文無法得知它是好評還是壞評�����;對于打三分及三分以下的是壞評����。
下面就可以將帶有評分數據轉化成為好評數據和壞評數據�����,為了提高計算效率��,本文將其重新分區���。
清單 4. 合并負樣本數據
 通過計算得到���,好評和壞評分別有 30447 條和 2238 條��,屬于非平衡樣本的機器模型訓練��。本文只取部分好評數據�,好評和壞評的數量一樣����,這樣訓練的正負樣本就是均衡的���。最后把正負樣本放在一起����,并把分類標簽和文本分開��,形成訓練數據集
清單 5. 生成訓練數據集
通過計算得到���,好評和壞評分別有 30447 條和 2238 條��,屬于非平衡樣本的機器模型訓練��。本文只取部分好評數據�,好評和壞評的數量一樣����,這樣訓練的正負樣本就是均衡的���。最后把正負樣本放在一起����,并把分類標簽和文本分開��,形成訓練數據集
清單 5. 生成訓練數據集
 文本的向量表示和文本特征提取
這一節中����,本文主要介紹如何做文本分詞�,如何用 TF-IDF 算法抽取文本特征����。將輸入的文本數據轉化為向量����,讓計算能夠“讀懂”文本��。
解決文本分類問題�����,最重要的就是要讓文本可計算�����,用合適的方式來表示文本�����,其中的核心就是找到文本的特征和特征值�。相比起英文�,中文多了一個分詞的過程�。本文首先用 jieba 分詞器將文本分詞����,這樣每個詞都可以作為文本的一個特征��。jieba 分詞器有三種模式的分詞:
精確模式����,試圖將句子最精確地切開���,適合文本分析�����;
全模式��,把句子中所有的可以成詞的詞語都掃描出來����, 速度非?��??����,但是不能解決歧義����;
搜索引擎模式���,在精確模式的基礎上�,對長詞再次切分��,提高召回率����,適合用于搜索引擎分詞�。
這里本文用的是搜索引擎模式將每一句評論轉化為詞����。
清單 6. 分詞
文本的向量表示和文本特征提取
這一節中����,本文主要介紹如何做文本分詞�,如何用 TF-IDF 算法抽取文本特征����。將輸入的文本數據轉化為向量����,讓計算能夠“讀懂”文本��。
解決文本分類問題�����,最重要的就是要讓文本可計算�����,用合適的方式來表示文本�����,其中的核心就是找到文本的特征和特征值�。相比起英文�,中文多了一個分詞的過程�。本文首先用 jieba 分詞器將文本分詞����,這樣每個詞都可以作為文本的一個特征��。jieba 分詞器有三種模式的分詞:
精確模式����,試圖將句子最精確地切開���,適合文本分析�����;
全模式��,把句子中所有的可以成詞的詞語都掃描出來����, 速度非?��??����,但是不能解決歧義����;
搜索引擎模式���,在精確模式的基礎上�,對長詞再次切分��,提高召回率����,適合用于搜索引擎分詞�。
這里本文用的是搜索引擎模式將每一句評論轉化為詞����。
清單 6. 分詞
 出于對大規模數據計算需求的考慮���,spark 的詞頻計算是用特征哈希(HashingTF)來計算的�����。特征哈希是一種處理高維數據的技術�,經常應用在文本和分類數據集上�。普通的 k 分之一特征編碼需要在一個向量中維護可能的特征值及其到下標的映射����,而每次構建這個映射的過程本身就需要對數據集進行一次遍歷�����。這并不適合上千萬甚至更多維度的特征處理�����。
特征哈希是通過哈希方程對特征賦予向量下標的�����,所以在不同情況下��,同樣的特征就是能夠得到相同的向量下標��,這樣就不需要維護一個特征值及其下表的向量�����。
要使用特征哈希來處理文本�����,需要先實例化一個 HashingTF 對象����,將詞轉化為詞頻����,為了高效計算�,本文將后面會重復使用的詞頻緩存�����。
清單 7. 訓練詞頻矩陣
出于對大規模數據計算需求的考慮���,spark 的詞頻計算是用特征哈希(HashingTF)來計算的�����。特征哈希是一種處理高維數據的技術�,經常應用在文本和分類數據集上�。普通的 k 分之一特征編碼需要在一個向量中維護可能的特征值及其到下標的映射����,而每次構建這個映射的過程本身就需要對數據集進行一次遍歷�����。這并不適合上千萬甚至更多維度的特征處理�����。
特征哈希是通過哈希方程對特征賦予向量下標的�����,所以在不同情況下��,同樣的特征就是能夠得到相同的向量下標��,這樣就不需要維護一個特征值及其下表的向量�����。
要使用特征哈希來處理文本�����,需要先實例化一個 HashingTF 對象����,將詞轉化為詞頻����,為了高效計算�,本文將后面會重復使用的詞頻緩存�����。
清單 7. 訓練詞頻矩陣

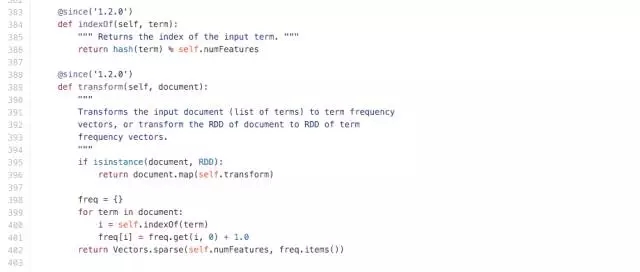
缺省情況下���,實例化的 HashingTF 特征維數 numFeatures 取了 220次方維�����,在 spark 的源碼中可以看到��,HashingTF 的過程就是對每一個詞作了一次哈希并對特征維數取余得到該詞的位置�����,然后按照該詞出現的次數計次���。所以就不用像傳統方法一樣每次維護一張詞表��,運用 HashingTF 就可以方便的得到該詞所對應向量元素的位置���。當然這樣做的代價就是向量維數會非常大����,好在 spark 可以支持稀疏向量���,所以計算開銷并不大��。
圖 3. HashingTF 源碼
 詞頻是一種抽取特征的方法����,但是它還有很多問題���,比如在這句話中“這幾天的天氣真好�����,項目組的老師打算組織大家一起去春游�?!暗摹毕啾扔凇绊椖拷M”更容易出現在人們的語言中�����,“的”和“項目組”同樣只出現一次����,但是項目組對于這句話來說更重要�����。
本文采用 TF-IDF 作為特征提取的方法�����,它的權重與特征項在文檔中出現的評率成正相關�����,與在整個語料中出現該特征項的文檔成反相關�。下面依據 tf 來計算逆詞頻 idf����,并計算出 TF-IDF
清單 8. 計算 TF-IDF 矩陣
詞頻是一種抽取特征的方法����,但是它還有很多問題���,比如在這句話中“這幾天的天氣真好�����,項目組的老師打算組織大家一起去春游�?!暗摹毕啾扔凇绊椖拷M”更容易出現在人們的語言中�����,“的”和“項目組”同樣只出現一次����,但是項目組對于這句話來說更重要�����。
本文采用 TF-IDF 作為特征提取的方法�����,它的權重與特征項在文檔中出現的評率成正相關�����,與在整個語料中出現該特征項的文檔成反相關�。下面依據 tf 來計算逆詞頻 idf����,并計算出 TF-IDF
清單 8. 計算 TF-IDF 矩陣
 至此���,本文就抽取出了文本的特征����,并用向量去表示了文本�����。
訓練分類模型
在這一小節中�����,本文介紹如何用 Spark 訓練樸素貝葉斯分類模型��,這一流程的輸入是文本的特征向量及已經標記好的分類標簽�����。在這里本文得到的是分類模型及文本分類的正確率����。
現在�,有了文本的特征項及特征值�,也有了分類標簽�����,需要用 RDD 的 zip 算子將這兩部分數據連接起來�,并將其轉化為分類模型里的 LabeledPoint 類型�����。并隨機將數據分為訓練集和測試集��,60%作為訓練集���,40%作為測試集��。
清單 9. 生成訓練集和測試集
至此���,本文就抽取出了文本的特征����,并用向量去表示了文本�����。
訓練分類模型
在這一小節中�����,本文介紹如何用 Spark 訓練樸素貝葉斯分類模型��,這一流程的輸入是文本的特征向量及已經標記好的分類標簽�����。在這里本文得到的是分類模型及文本分類的正確率����。
現在�,有了文本的特征項及特征值�,也有了分類標簽�����,需要用 RDD 的 zip 算子將這兩部分數據連接起來�,并將其轉化為分類模型里的 LabeledPoint 類型�����。并隨機將數據分為訓練集和測試集��,60%作為訓練集���,40%作為測試集��。
清單 9. 生成訓練集和測試集
 本文用訓練數據來訓練貝葉斯模型���,得到 NBmodel 模型來預測測試集的文本特征向量��,并且計算出各個模型的正確率����,這個模型的正確率為 74.83%�����。
清單 10. 訓練貝葉斯分類模型
本文用訓練數據來訓練貝葉斯模型���,得到 NBmodel 模型來預測測試集的文本特征向量��,并且計算出各個模型的正確率����,這個模型的正確率為 74.83%�����。
清單 10. 訓練貝葉斯分類模型
 可以看出貝葉斯模型最后的預測模型并不高����,但是基于本文采集的數據資源有限�,特征提取過程比較簡單直接����。所以還有很大的優化空間���,在第四章中�,本文將介紹提高正確率的方法����。
分類未標記文檔
現在可以用本文訓練好的模型來對未標記文本分類����,流程是獲取用戶輸入的評論��,然后將輸入的評論文本分詞并轉化成 tf-idf 特征向量��,然后用 3.4 節中訓練好的分類模型來分類���。
清單 11. 分類未分類文本
可以看出貝葉斯模型最后的預測模型并不高����,但是基于本文采集的數據資源有限�,特征提取過程比較簡單直接����。所以還有很大的優化空間���,在第四章中�,本文將介紹提高正確率的方法����。
分類未標記文檔
現在可以用本文訓練好的模型來對未標記文本分類����,流程是獲取用戶輸入的評論��,然后將輸入的評論文本分詞并轉化成 tf-idf 特征向量��,然后用 3.4 節中訓練好的分類模型來分類���。
清單 11. 分類未分類文本
 當程序輸入待分類的評論:“這部電影沒有意思�,劇情老套�,真沒勁����, 后悔來看了”
程序輸出為“NaiveBayes Model Predict: 0.0”���。
當程序輸入待分類的評論:“太精彩了講了一個關于夢想的故事劇情很反轉制作也很精良”
程序輸出為“NaiveBayes Model Predict: 1.0”�。
至此���,最為簡單的文本情感分類系統就構建完整了�����。
提高正確率的方法
在第三章中��,本文介紹了構建文本分類系統的方法���,但是正確率只有 74.83%�����,在這一章中�����,本文將講述文本分類正確率低的原因及改進方法�����。
文本分類正確率低的原因主要有:
文本預處理比較粗糙����,可以進一步處理����,比如去掉停用詞��,去掉低頻詞�;
特征詞抽取信息太少�����,搜索引擎模式的分詞模式不如全分詞模式提供的特征項多��;
樸素貝葉斯模型比較簡單�,可以用其他更為先進的模型算法���,如 SVM����;
數據資源太少�����,本文只能利用了好評�����、壞評論各 2238 條��。數據量太少�����,由于爬蟲爬取的數據����,沒有進行人工的進一步的篩選�����,數據質量也得不到 100%的保證�����。
下面分別就這四個方面���,本文進一步深入的進行處理�,對模型進行優化�����。
數據預處理中去掉停用詞
停用詞是指出現在所有文檔中很多次的常用詞��,比如“的”�、“了”���、“是”等�����,可以在提取特征的時候將這些噪聲去掉�。
首先需要統計一下詞頻���,看哪些詞是使用最多的�����,然后定義一個停用詞表�,在構建向量前���,將這些詞去掉�����。本文先進行詞頻統計��,查看最常用的詞是哪些��。
清單 12. 統計詞頻
當程序輸入待分類的評論:“這部電影沒有意思�,劇情老套�,真沒勁����, 后悔來看了”
程序輸出為“NaiveBayes Model Predict: 0.0”���。
當程序輸入待分類的評論:“太精彩了講了一個關于夢想的故事劇情很反轉制作也很精良”
程序輸出為“NaiveBayes Model Predict: 1.0”�。
至此���,最為簡單的文本情感分類系統就構建完整了�����。
提高正確率的方法
在第三章中��,本文介紹了構建文本分類系統的方法���,但是正確率只有 74.83%�����,在這一章中�����,本文將講述文本分類正確率低的原因及改進方法�����。
文本分類正確率低的原因主要有:
文本預處理比較粗糙����,可以進一步處理����,比如去掉停用詞��,去掉低頻詞�;
特征詞抽取信息太少�����,搜索引擎模式的分詞模式不如全分詞模式提供的特征項多��;
樸素貝葉斯模型比較簡單�,可以用其他更為先進的模型算法���,如 SVM����;
數據資源太少�����,本文只能利用了好評�����、壞評論各 2238 條��。數據量太少�����,由于爬蟲爬取的數據����,沒有進行人工的進一步的篩選�����,數據質量也得不到 100%的保證�����。
下面分別就這四個方面���,本文進一步深入的進行處理�,對模型進行優化�����。
數據預處理中去掉停用詞
停用詞是指出現在所有文檔中很多次的常用詞��,比如“的”�、“了”���、“是”等�����,可以在提取特征的時候將這些噪聲去掉�。
首先需要統計一下詞頻���,看哪些詞是使用最多的�����,然后定義一個停用詞表�,在構建向量前���,將這些詞去掉�����。本文先進行詞頻統計��,查看最常用的詞是哪些��。
清單 12. 統計詞頻
 通過觀察�,選擇出現次數比較多�,但是對于文本情感表達沒有意義的詞���,作為停用詞��,構建停用詞表����。然后定義一個過濾函數����,如果該詞在停用詞表中那么需要將這個詞過濾掉��。
清單 13. 去掉停用詞
通過觀察�,選擇出現次數比較多�,但是對于文本情感表達沒有意義的詞���,作為停用詞��,構建停用詞表����。然后定義一個過濾函數����,如果該詞在停用詞表中那么需要將這個詞過濾掉��。
清單 13. 去掉停用詞

嘗試不用的分詞模式
本文在分詞的時候使用的搜索引擎分詞模式�����,在這種模式下只抽取了重要的關鍵字����,可能忽略了一些可能的特征詞����?��?梢园逊衷~模式切換到全分詞模式����,盡可能的不漏掉特征詞���,同樣的模型訓練�,正確率會有 1%~2%的提升��。
清單 14. 全分詞模式分詞
 更換訓練模型方法
在不進行深入優化的情況下��,SVM 往往有著比其他分類模型更好的分類效果�����。下面在相同的條件下��,運用 SVM 模型訓練�,最后得到的正確率有 78.59%���。
清單 15. 用支持向量機訓練分類模型
更換訓練模型方法
在不進行深入優化的情況下��,SVM 往往有著比其他分類模型更好的分類效果�����。下面在相同的條件下��,運用 SVM 模型訓練�,最后得到的正確率有 78.59%���。
清單 15. 用支持向量機訓練分類模型
 訓練數據的問題
本文只是為了演示如何構建這套系統���,所以爬取的數據量并不多�,獲取的文本數據也沒有人工的進一步核對其正確性��。如果本文能夠有更豐富且權威的數據源�,那么模型的正確率將會有較大的提高��。
作者對中國科學院大學的譚松波教授發布的酒店產品評論文本做了分類系統測試�����,該數據集是多數學者公認并且使用的����。用 SVM 訓練的模型正確率有 87.59%��。
總結
訓練數據的問題
本文只是為了演示如何構建這套系統���,所以爬取的數據量并不多�,獲取的文本數據也沒有人工的進一步核對其正確性��。如果本文能夠有更豐富且權威的數據源�,那么模型的正確率將會有較大的提高��。
作者對中國科學院大學的譚松波教授發布的酒店產品評論文本做了分類系統測試�����,該數據集是多數學者公認并且使用的����。用 SVM 訓練的模型正確率有 87.59%��。
總結
本文向讀者詳細的介紹了利用 Spark 構建文本情感分類系統的過程���,從數據的清洗�、轉換��,Spark 的 RDD 有 Filter�、Map 方法可以輕松勝任��;對于抽取文本特征���,Spark 針對大規模數據的處理不僅在計算模型上有優化�����,還做了算法的優化�����,它利用哈希特征算法來實現 TF-IDF�,從而能夠支持上千萬維的模型訓練���;對于選擇分類模型�,Spark 也實現好了常用的分類模型���,調用起來非常方便��。最后希望這篇文章可以對大家學習 spark 和文本分類有幫助�。
文 | 江 萬���, 北京郵電大學研究生�, 北京郵電大學
英 春�,軟件服務團隊架構師����,IBM
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
