數據分析中常犯哪些錯誤以及如何解決�����?
在大大小小的數據分析中會因為各種原因犯不同的錯誤都是哪方面的呢�����,又如何解決�?
錯把相關性當成因果性 correlation vs. causation
經典的冰淇凌銷量和游泳溺水人數成正比的數據��,這并不能說明冰淇凌銷量的增加會導致更多的人溺水�,而只能說明二者相關����,比如因為天熱所以二者數量都增加了���。這個例子比較明顯��,說起來可能會有人覺得怎么會有人犯這樣的錯誤���,然而在實際生活�、學習��、工作中�,時不時的就會有人犯這樣的錯誤�。
舉個栗子
數據顯示�����,當科比出手10-19次時���,湖人的勝率是71.5%��;當科比出手20-29次時����,湖人的勝率驟降到60.8%���;而當科比出手30次或者更多時�����,湖人的勝率只有41.7%����。
根據這組數據����,為了贏球���,科比應該少出手����?并不一定如此���。有可能科比出手少的時候是因為隊友狀態好���,并不需要他出手太多��。也有可能是因為球隊早早領先�,垃圾時間太多�。而出手太多的比賽是因為比賽艱難或者隊友狀態不好�,需要他挺身而出��。當然�,以上也只是可能之一��,具體是什么情況光靠這組數據并不能得出任何結論���。

幸存者偏差 survivorship bias
數據分析中看到的樣本是“幸存了某些經歷”才被觀察到的���,進而導致結論不正確����。
比如比爾蓋茨�、喬布斯���、扎克伯格都沒有念完大學�����,所以大家都應該退學去創業����。這一結論的最大問題在于那些退學而又沒有成功的例子���,很多時候我們是看不到的��。另一方面�����,他們是因為牛逼才退學����,而不是退學才牛逼的���,看��,相關性/因果性真是限魂不散�����。
再比如 Uber 發現新用戶有10塊錢優惠券����,但是平均評價卻只有3星����。相反�,第二次再用的時候沒有優惠券了���,評價卻高達4星半�����。這說明�����,不給優惠券用戶評價會更高�,果然用戶雖然愛用優惠券����,但內心還是覺得便宜沒好東西的�����?很明顯���,幸存者偏差在這個例子里體現在那些打一星二星評價的用戶�����,之后可能就沒有第二次了��。更明顯的���,這個例子是我瞎扯的�����。

樣本跟整體存在著本質的不同
以知乎為例�����,會有種錯覺人人年薪百萬�,985/211起�,各種GFSBFM��,天朝收入水平直逼灣區碼工���。然而一方面這是幸存者偏差�,知乎大V們的發聲更容易被看到(看�,幸存者偏差也是陰魂不散)�。另一方面�,不要小瞧知乎跟天朝網民的差別��,以及天朝網民跟天朝老百姓的差別–樣本跟整體的差別��。
類似的例子有水木的工作版塊��、步行街的收入和華人網站的貧困線���。

過于追逐統計上的顯著性 statistical significance
統計101告訴我們�,要比較兩組數是否不同����,最基本的一點可以看它們的區別是不是統計上顯著����。
比如 Linkedin 又要改版了(我為什么要說又呢)�,有兩個版本 A 和 B. 灰度測試發現�,跟現有版本比起來��,A 的日活比現有版本高20%�,但是統計不顯著��。而 B 的日活跟現有版本雖然只高了3%���,但是統計顯著�。于是 PM 拿出統計101翻到第二頁說����,來���,咱們把統計顯著的版本 B 上線吧����?���?啾频臄祿茖W家 DS 說����,等一下��!并不是所有時候都選統計顯著的那一個��,咱們再看看版本 A 的數據吧(具體分析略過一萬字)���。
很顯然����,這個例子也是我瞎扯的����。

不做數據可視化�,以及更可怕的:做出錯誤或者帶誤導性的數據可視化
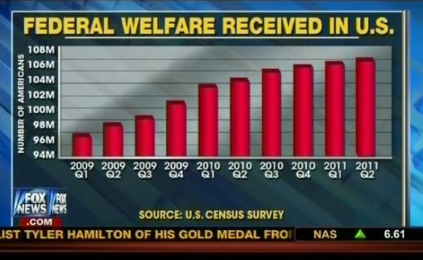
在趨勢圖中����,為了說明增長趨勢多明顯�����,把Y調成不從0開始�。這樣差距會看起來很大����,增長很大��,但是如果把Y軸從0開始看的話���,會顯得基本沒有差距���。
數據分析提供的結果和建議不具有可行性
twitter通過分析文本數據發現��。����。�。
算了���,我編不出來����,由此可見���,不具有可行性的結果雖然是“理論正確‘的分析結果����,然并卵����。����。���。

不做數據分析
別笑����,據以前的校內后來的人人現在不知道叫什么的 PM 說�����,這是真的��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
