淺析時間序列用戶生命周期的聚類方法
一�、時間序列
時間序列和時間序列分式分別是什么�?
時間序列是指將某種現象某一個統計指標在不同時間上的各個數值�,按時間先后順序排列而形成的序列���。
而時間序列分析(Time series analysis)是一種動態數據處理的統計方法��。該方法基于隨機過程理論和數理統計學方法���,研究隨機數據序列所遵從的統計規律�����,以用于解決實際問題���。(引自百度百科)
從上述說明可以看出���,時間序列不僅僅只是一個序列數據����,而是一個受系統影響很大的序列數據�,時間序列的數據本身存在于生活中的各個領域里���。人們對時間序列的分析從很早以前就開始了�,發展至今�����,在大數據環境下�,采用數據挖掘的方法來表示數據內部規律也成為了分析時間序列的一種重要方向和趨勢�����。
二�、時間序列特征
時間序列變量有以下兩大主要特征:
1.非平穩性(nonstationarity���,也作不平穩性�����,非穩定性):即時間序列變量無法呈現出一個長期趨勢并最終趨于一個常數或是一個線性函數�����。也就是說�����,時間序列在每個時間周期里可能出現兩種變化��,一種是受整個系統變化的影響����,另一種是隨機的變化�。
2.波動幅度隨時間變化(Time—varying Volatility):即一個時間序列變量的方差隨時間的變化而變化����。
正是因為這種不確定性和各自間的相關性��,使得有效分析時間序列變量十分困難�。舉例來說�,每個人在不同的時間點產生的行為都是隨機行為����,但即將產生的行為或多或少又會受個人過去的行為習慣所影響�。假設當我們有這個人過去的全部行為數據時���,首先希望通過某種方式刻畫這個人過去的行為�����,并最終找到和這個人有類似行為習慣的人群���。
傳統的劃分方法很多�����,但都是通過某個行為來進行分類��,將所有相關行為放在時間序列上來進行整體觀察�。就用戶生命周期而言�����,國內外都有很多這個方向的研究����。那么能否找到一種方法通過大量的數據來實踐時間序列的聚類方法優劣性�,并應用到實際項目中呢�����?
三���、相關案例
時間序列在電子商務領域的研究����,近幾年才逐漸興起����。我們在項目中希望能夠對有相似行為的人群做劃分���,但發現由于人的很多行為是相互關聯的���,并且在時間的維度中還會發生變化�����,可能受過去的影響�����,也可能不受影響��,所以��,這一秒和下一秒都是不可確定的����,從傳統方法的聚類存在局限性�。
但我們從長期趨勢研究中發現消費的某些行為可能是固定的����,比如定期的購買�、季節的變換����、促銷活動的影響等�����,這些都是和時間周期有關系的�,于是我們想到使用基于時間序列的聚類的方法來進行嘗試�,得到了一些新的效果����。隨著時間的變換��,人的行為可能和時間進行關聯后會產生不同的結果��,我們最后不僅能得到這個用戶局部的行為規律�,也可以看到用戶在整體時間周期里的行為的規律��,通過觀察整體和局部����,便能更好進行用戶畫像����。
四�、時間序列的聚類
關于時間序列聚類的方法��,簡單總結如下:
1.傳統靜態數據的聚類方法有:基于劃分的聚類�、基于層次的聚類��、基于密度的聚類��、基于格網的聚類���、基于模型的聚類���;
2.時間序列聚類方法:大概有三種�,一是基于形態特征���,即形狀變化����,包括全局特征和局部特征��;二是基于結構特征��,即全局構造或內在變化機制�,包括基本統計特征���、時域特征和頻域特征�;三是基于模型特征���,參數的的變化影響系統的變化��,同時存在隨機變化��。
然而無論是分類��、聚類還是關聯規則挖掘��,都需要解決時間序列的相似度問題���,相似性搜索是時間序列數據挖掘的研究基礎�。由于時間序列存在各種復雜變形(如平移�、伸縮��、間斷等) �,且變形時間和變形程度都無法預料�,傳統的歐氏距離已經無法勝任��。經過調研得知���,目前動態時間彎曲(DTW) 相似距離的穩定性已在國內外得到驗證�����,于是我們打算采用DTW來嘗試聚類分類�����。
五���、歐式距離
我們定義兩個時間序列長度為N的序列T和D的歐式距離如下:

歐式距離本身也是計算空間距離的����,我們剛開始選用它來計算距離����,但發現單獨使用準確性不高?��,F在����,我們來做一個簡單的實驗:
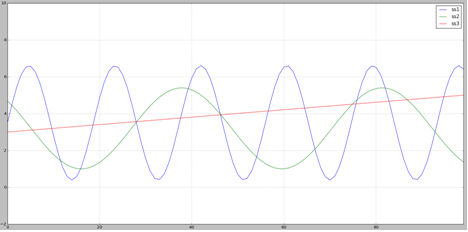
圖1 三條序列曲線
首先��,用Python來簡單的畫三條曲線(如圖1)�����,從圖中可以明顯的看出��,ss1和ss2曲線是很相似(這里就是sin函數的不同區間變換)���,ss3和他們兩個都有明顯的不同���。我們使用公式來計算ss1和ss2�,ss1和ss3的距離�,結果如下:
ss1 --> ss2 的歐式距離:26.959216038
ss1 --> ss3 的歐式距離:23.1892491903
從上面可以直觀的發現ss1和ss2的距離值反而更大��。這里只是直觀的說明它本身對序列計算的問題��,其實當發現時間序列的頻率變化�;時間扭曲的時候���,單一的歐式距離公式的偏差是比較大的���。
六�、動態時間規整(Dynamic Time Warping)
動態時間規整現在應用的比較多的是在語音識別上��,因為DTW本身是為了找到最優非線性時間序列之間的距離值���。這個算法是基于動態規劃(DP)的思想���,解決了發音長短不一的模板匹配問題����,簡單來說�����,就是通過構建一個鄰接矩陣���,尋找最短路徑和的犯法?����,F在我們繼續試驗����,定義兩個時間序列長度為n的序列T和D��。

我們需要先構建一個n x n的矩陣�,其中i�����,j是和之間的歐式距離��,我們想通過這個矩陣的最小累積距離的路徑���。然后確定對比兩個時間序列之間的距離���。我們叫這個路徑為W�����。
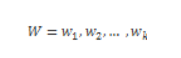
其中每個元素代表了T和D點之間的距離����,例如:
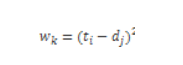
我們想找到距離最小的路徑:
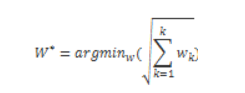
最佳路徑是使用的動態規劃遞歸函數�,具體公式如下:
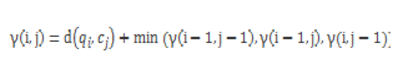
最后得到結果:
ss1 --> ss2 的DTW距離:17.9297184686
ss1 --> ss3 的DTW距離:21.5494948244
七�、聚類
從實驗后��,我們最后選用了DTW作為時間序列的計算的方法����。但在實際運行過程中�����,發現DTW的的運算速度確實比較慢�����,目前正在實驗提升它效率的方法�。有了計算方法后���,我們準備開始進行聚類了�����。我們使用k近鄰分類算法���。根據經驗�����,最理想的結果是當然是k = 1時的距離值��。在該算法中��,訓練集和測試集分別采用的時間序列的周期集合數據集���,在算法中��,對測試集進行預測的每個時間序列�����,搜索是必須通過訓練中的所有的點集��,發現最相似的一點����。
八��、小結
本文只是簡單介紹了在實際項目中使用時間序列聚類算法時產生的疑惑和解決思路�,期間很多方法可能還是嘗試和實驗階段���。由于時間的原因���,可能還有很多細節方面考慮不是很周到���,DTW算法比較可靠
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
